测量 GPU 内存带宽和处理能力
此示例演示了如何测量 GPU 硬件的一些关键性能指标。
GPU 可用于加速某些类型的计算。然而,不同的 GPU 设备之间的 GPU 性能存在很大差异。这三个测试用于量化 GPU 的性能:
数据可以多快被发送到 GPU 或从 GPU 读回?
GPU 内核读写数据的速度有多快?
GPU 在双精度和单精度模式下进行计算的速度有多快?
评估这些度量后,您可以比较 GPU 和主机 CPU 的性能。此比较表明,GPU 提供优于 CPU 的性能需要多少数据或计算量。
检查 GPU 设置
检查是否可用 GPU。
gpu = gpuDevice;
disp(gpu.Name + " GPU detected and available.")NVIDIA RTX A5000 GPU detected and available.
测量主机/GPU 带宽
第一个测试估计数据发送到 GPU 和从 GPU 读取的速度。由于 GPU 插入 PCI 总线,带宽主要取决于 PCI 总线的传输速度以及同时使用该总线的其他设备数量。但是,测量中包含了一些开销,尤其是调用发送和读取函数以及分配数组所花费的时间。由于这些开销在任何 GPU 的实际应用中都会存在,因此将其纳入计算是合理的。
定义测试参数:
创建一个变量,表示存储一个双精度数字所需的字节数。
创建一个大小向量,其中最大大小为可用 GPU 内存的 1/4。测试循环遍历该向量,并创建大小递增的数组。由于 MATLAB® 中 GPU 上的数组不能超过 个元素,请删除会创建超过此数组大小的任何大小。
sizeOfDouble = 8; maxSize = 0.25*gpu.AvailableMemory; maxNumTests = 15; sizes = logspace(4,log10(maxSize),maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
要测量主机/GPU 带宽,对于 sizes 中的每个数组大小:
numTests = numel(sizes); numElements = floor(sizes/sizeOfDouble); sendTimes = inf(1,numTests); gatherTimes = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing send and gather for array with " + numElements(idx) + " elements.") % Generate random data on GPU and host. gpuData = randi([0 9],numElements(idx),1,"gpuArray"); hostData = gather(gpuData); % Time sending data to GPU. sendFcn = @() gpuArray(hostData); sendTimes(idx) = gputimeit(sendFcn); % Time gathering data back from GPU. gatherFcn = @() gather(gpuData); gatherTimes(idx) = gputimeit(gatherFcn); end
Test 1 of 15. Timing send and gather for array with 1250 elements. Test 2 of 15. Timing send and gather for array with 3240 elements. Test 3 of 15. Timing send and gather for array with 8398 elements. Test 4 of 15. Timing send and gather for array with 21768 elements. Test 5 of 15. Timing send and gather for array with 56425 elements. Test 6 of 15. Timing send and gather for array with 146258 elements. Test 7 of 15. Timing send and gather for array with 379107 elements. Test 8 of 15. Timing send and gather for array with 982663 elements. Test 9 of 15. Timing send and gather for array with 2547104 elements. Test 10 of 15. Timing send and gather for array with 6602203 elements. Test 11 of 15. Timing send and gather for array with 17113191 elements. Test 12 of 15. Timing send and gather for array with 44358118 elements. Test 13 of 15. Timing send and gather for array with 114978124 elements. Test 14 of 15. Timing send and gather for array with 298028173 elements. Test 15 of 15. Timing send and gather for array with 772501660 elements.
sendBandwidth = (sizes./sendTimes)/1e9; gatherBandwidth = (sizes./gatherTimes)/1e9;
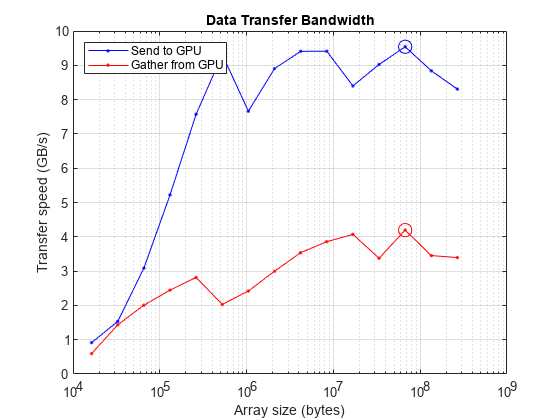
确定峰值发送和接收速度。请注意,本测试中使用的 GPU 支持 PCI Express® 4.0 版本,其每条通道的理论带宽为 1.97 GB/s。对于 NVIDIA® 计算卡使用的 16 个插槽,这提供了 31.52 GB/s 的理论带宽。
[maxSendBandwidth,maxSendIdx] = max(sendBandwidth);
[maxGatherBandwidth,maxGatherIdx] = max(gatherBandwidth);
fprintf("Achieved peak send speed of %.2f GB/s",maxSendBandwidth)Achieved peak send speed of 10.13 GB/s
fprintf("Achieved peak gather speed of %.2f GB/s",maxGatherBandwidth)Achieved peak gather speed of 4.28 GB/s
绘制数据传输速度与数组大小的关系图,并圈出每个情况下的峰值。由于数据集较小,因此开销占主导地位。当数据量较大时,PCI 总线就成为限制因素。
figure semilogx(sizes,sendBandwidth,MarkerIndices=maxSendIdx,Marker="o") hold on semilogx(sizes,gatherBandwidth,MarkerIndices=maxGatherIdx,Marker="o") grid on title("Data Transfer Bandwidth") xlabel("Array size (bytes)") ylabel("Transfer speed (GB/s)") legend(["Send to GPU" "Gather from GPU"],Location="SouthEast") hold off
在内存密集型操作期间测量读写速度
许多操作对数组中的每个元素进行很少的计算,因此这些操作主要受从内存中获取数据或将其写回内存所花费的时间的影响。函数如 ones、zeros、nan 和 true 仅输出结果,而函数如 transpose 和 tril 既读取数据又输出结果,但不进行任何计算。即使是像 plus 和 minus 这样简单的运算符,每个元素的计算量也非常少,因此它们的性能仅受内存访问速度的限制。
函数 plus 对于每个浮点运算执行一次内存读取和一次内存写入操作。因此,该函数受内存访问速度的限制,并能很好地反映读写操作的速度。
重置 GPU 以清除其内存中上一节分配的 GPU 数组。
reset(gpu)
创建一个大小向量。
sizes = logspace(4.5,log10(maxSize),maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
测量 GPU 读写 GPU 内存的速度。还要测量主机读写主机内存的速度。对于 sizes 中的每个数组大小:
在 GPU 和主机上创建随机双精度数据。
使用
gputimeit函数来计时在 GPU 上执行plus函数的时间。使用
timeit函数来计时主机上plus函数的执行时间。将测得的时间内读取和写入的数据量除以该时间,以确定读取和写入带宽。
numTests = numel(sizes); numElements = floor(sizes/sizeOfDouble); memoryTimesGPU = inf(1,numTests); memoryTimesHost = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing plus operation on GPU and CPU for arrays with " + numElements(idx) + " elements.") % Generate random data on GPU and host. gpuData = randi([0 9],numElements(idx),1,"gpuArray"); hostData = gather(gpuData); % Time the plus function on GPU. plusFcn = @() plus(gpuData,1.0); memoryTimesGPU(idx) = gputimeit(plusFcn); % Time the plus function on host. plusFcn = @() plus(hostData,1.0); memoryTimesHost(idx) = timeit(plusFcn); end
Test 1 of 15. Timing plus operation on GPU and CPU for arrays with 3952 elements. Test 2 of 15. Timing plus operation on GPU and CPU for arrays with 9437 elements. Test 3 of 15. Timing plus operation on GPU and CPU for arrays with 22530 elements. Test 4 of 15. Timing plus operation on GPU and CPU for arrays with 53788 elements. Test 5 of 15. Timing plus operation on GPU and CPU for arrays with 128416 elements. Test 6 of 15. Timing plus operation on GPU and CPU for arrays with 306583 elements. Test 7 of 15. Timing plus operation on GPU and CPU for arrays with 731942 elements. Test 8 of 15. Timing plus operation on GPU and CPU for arrays with 1747449 elements. Test 9 of 15. Timing plus operation on GPU and CPU for arrays with 4171886 elements. Test 10 of 15. Timing plus operation on GPU and CPU for arrays with 9960023 elements. Test 11 of 15. Timing plus operation on GPU and CPU for arrays with 23778702 elements. Test 12 of 15. Timing plus operation on GPU and CPU for arrays with 56769618 elements. Test 13 of 15. Timing plus operation on GPU and CPU for arrays with 135532606 elements. Test 14 of 15. Timing plus operation on GPU and CPU for arrays with 323572501 elements. Test 15 of 15. Timing plus operation on GPU and CPU for arrays with 772501660 elements.
memoryBandwidthGPU = 2*(sizes./memoryTimesGPU)/1e9; memoryBandwidthHost = 2*(sizes./memoryTimesHost)/1e9;
确定峰值读取和写入速度。
[maxBWGPU,maxBWIdxGPU] = max(memoryBandwidthGPU);
[maxBWHost,maxBWIdxHost] = max(memoryBandwidthHost);
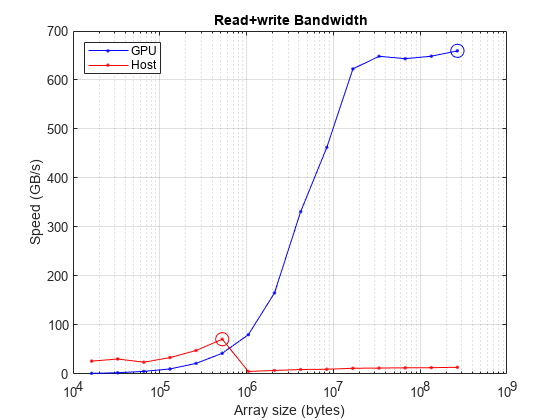
fprintf("Achieved peak read+write speed on the GPU: %.2f GB/s",maxBWGPU)Achieved peak read+write speed on the GPU: 678.83 GB/s
fprintf("Achieved peak read+write speed on the host: %.2f GB/s",maxBWHost)Achieved peak read+write speed on the host: 59.22 GB/s
绘制读写速度与数组大小的关系图,并圈出每个情况下的峰值。将此图与上面的数据传输图进行比较,可以清楚地看出,GPU 从其内存读取和写入的速度通常比从主机获取数据的速度快得多。因此,尽量减少主机与 GPU 或 GPU 与主机之间的内存传输次数非常重要。理想情况下,程序应首先在 GPU 上创建数据。否则,程序应将数据传输到 GPU,然后在数据位于 GPU 上时尽可能多地处理数据,只有在完成后才将数据返回主机。
figure semilogx(sizes,memoryBandwidthGPU,MarkerIndices=maxBWIdxGPU,Marker="o") hold on semilogx(sizes,memoryBandwidthHost,MarkerIndices=maxBWIdxHost,Marker="o") grid on title("Read+Write Bandwidth") xlabel("Array size (bytes)") ylabel("Speed (GB/s)") legend(["GPU" "Host"],Location="NorthWest") hold off
在计算密集型操作过程中测量处理能力
对于从内存读取或写入每个元素时浮点计算次数较多的操作,内存速度并不重要。这些操作被认为具有高计算密度。在这种情况下,浮点单元的数量和速度是限制因素。
矩阵与矩阵相乘是计算性能的一个很好的测试。对于两个 矩阵的乘法,浮点计算的总数为
.
读取两个输入矩阵并写入一个结果矩阵,总共读取或写入 个元素。这给出了 (2N - 1)/3 FLOP/元素的计算密度。将此与上文使用的 plus 函数进行对比,其计算密度为 1/2 FLOP/元素。
重置 GPU 以清除其内存中上一节分配的 GPU 数组,并创建一个大小为的向量。
reset(gpu) sizes = logspace(4,log10(maxSize)-1,maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
双精度
MATLAB 支持双精度或单精度计算。使用单精度计算而非双精度计算可以提升在 GPU 上运行的代码性能,因为大多数 GPU 显卡专为图形显示设计,而图形显示对单精度性能有较高要求。相比之下,CPU 设计用于通用计算,因此在从双精度切换到单精度时不会带来这种性能提升。有关将数据转换为单精度并对单精度数据执行算术运算的更多信息,请参阅 浮点数。适合 GPU 上单精度计算的工作流的典型示例包括图像处理和机器学习。然而,其他类型的计算,例如线性代数问题,通常需要双精度处理。
要大致测量 GPU 在单精度与双精度下的相对性能,请查询设备的 SingleDoubleRatio 属性。此属性描述设备上单精度浮点单元 (FPU) 与双精度浮点单元 (FPU) 的比例。大多数台式机 GPU 的单精度浮点运算单元数量是双精度浮点运算单元的 24 倍、32 倍,甚至 64 倍。部分图形处理单元 (GPU) 还集成了专门的处理核心,用于加速常见的深度学习运算。例如,安培架构以及后续的 NVIDIA 数据中心 GPU(A100 和 H100)均内置张量核心(Tensor Cores),可加速双精度矩阵乘法运算。对于这些数据中心 GPU,SingleDoubleRatio 属性可能无法准确表示与双精度相比,矩阵乘法在单精度下的相对性能。
gpu.SingleDoubleRatio
ans = 32
为了测量双精度处理能力,对 sizes 中的每个数组大小进行以下计算:
在 GPU 和主机上创建随机双精度数据。
使用
gputimeit函数在 GPU 上以单精度和双精度模式计时执行plus函数。使用
timeit函数以单精度和双精度计时主机上plus函数的执行时间。将测得的时间内读取和写入的数据量除以该时间,以确定读取和写入带宽。
numTests = numel(sizes); NDouble = floor(sqrt(sizes/sizeOfDouble)); mmTimesHostDouble = inf(1,numTests); mmTimesGPUDouble = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing double-precision matrix-matrix multiplication with " + NDouble(idx)^2 + " elements.") % Generate random data on GPU. A = rand(NDouble(idx),"gpuArray"); B = rand(NDouble(idx),"gpuArray"); % Time the matrix multiplication on GPU. mmTimesGPUDouble(idx) = gputimeit(@() A*B); % Gather the data and time matrix multiplication on the host. A = gather(A); B = gather(B); mmTimesHostDouble(idx) = timeit(@() A*B); end
Test 1 of 15. Timing double-precision matrix-matrix multiplication with 1225 elements. Test 2 of 15. Timing double-precision matrix-matrix multiplication with 2601 elements. Test 3 of 15. Timing double-precision matrix-matrix multiplication with 5776 elements. Test 4 of 15. Timing double-precision matrix-matrix multiplication with 12321 elements. Test 5 of 15. Timing double-precision matrix-matrix multiplication with 26569 elements. Test 6 of 15. Timing double-precision matrix-matrix multiplication with 57121 elements. Test 7 of 15. Timing double-precision matrix-matrix multiplication with 123201 elements. Test 8 of 15. Timing double-precision matrix-matrix multiplication with 265225 elements. Test 9 of 15. Timing double-precision matrix-matrix multiplication with 570025 elements. Test 10 of 15. Timing double-precision matrix-matrix multiplication with 1227664 elements. Test 11 of 15. Timing double-precision matrix-matrix multiplication with 2637376 elements. Test 12 of 15. Timing double-precision matrix-matrix multiplication with 5673924 elements. Test 13 of 15. Timing double-precision matrix-matrix multiplication with 12201049 elements. Test 14 of 15. Timing double-precision matrix-matrix multiplication with 26234884 elements. Test 15 of 15. Timing double-precision matrix-matrix multiplication with 56415121 elements.
确定峰值双精度处理能力。
mmFlopsHostDouble = (2*NDouble.^3 - NDouble.^2)./mmTimesHostDouble;
[maxFlopsHostDouble,maxFlopsHostDoubleIdx] = max(mmFlopsHostDouble);
mmFlopsGPUDouble = (2*NDouble.^3 - NDouble.^2)./mmTimesGPUDouble;
[maxFlopsGPUDouble,maxFlopsGPUDoubleIdx] = max(mmFlopsGPUDouble);
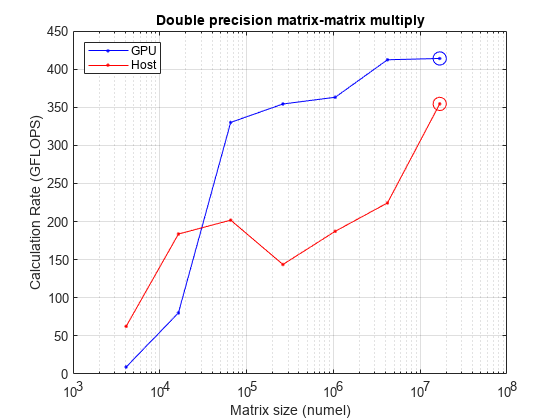
fprintf("Achieved peak double-precision processing power on the GPU: %.2f TFLOPS",maxFlopsGPUDouble/1e12)Achieved peak double-precision calculation rate on the GPU: 0.41 TFLOPS
fprintf("Achieved peak double-precision processing power on the host: %.2f TFLOPS",maxFlopsHostDouble/1e12)Achieved peak double-precision calculation rate on the host: 0.39 TFLOPS
单精度
您可以通过使用 single 函数将数据转换为单精度,或者在创建函数(如 single、zeros、ones 和 rand)中将数据类型指定为 eye。
测量单精度处理能力。使用 rand 函数生成单精度随机数据,并指定 single 作为数据类型。
NSingle = floor(sqrt(sizes/(sizeOfDouble/2))); mmTimesHostSingle = inf(1,numTests); mmTimesGPUSingle = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing single-precision matrix-matrix multiplication with " + NSingle(idx)^2 + " elements.") % Generate random, single-precision data on GPU. A = rand(NSingle(idx),"single","gpuArray"); B = rand(NSingle(idx),"single","gpuArray"); % Time matrix multiplication on GPU. mmTimesGPUSingle(idx) = gputimeit(@() A*B); % Gather the data and time matrix multiplication on the host. A = gather(A); B = gather(B); mmTimesHostSingle(idx) = timeit(@() A*B); end
Test 1 of 15. Timing single-precision matrix-matrix multiplication with 2500 elements. Test 2 of 15. Timing single-precision matrix-matrix multiplication with 5329 elements. Test 3 of 15. Timing single-precision matrix-matrix multiplication with 11449 elements. Test 4 of 15. Timing single-precision matrix-matrix multiplication with 24649 elements. Test 5 of 15. Timing single-precision matrix-matrix multiplication with 53361 elements. Test 6 of 15. Timing single-precision matrix-matrix multiplication with 114244 elements. Test 7 of 15. Timing single-precision matrix-matrix multiplication with 247009 elements. Test 8 of 15. Timing single-precision matrix-matrix multiplication with 529984 elements. Test 9 of 15. Timing single-precision matrix-matrix multiplication with 1140624 elements. Test 10 of 15. Timing single-precision matrix-matrix multiplication with 2455489 elements. Test 11 of 15. Timing single-precision matrix-matrix multiplication with 5276209 elements. Test 12 of 15. Timing single-precision matrix-matrix multiplication with 11350161 elements. Test 13 of 15. Timing single-precision matrix-matrix multiplication with 24403600 elements. Test 14 of 15. Timing single-precision matrix-matrix multiplication with 52475536 elements. Test 15 of 15. Timing single-precision matrix-matrix multiplication with 112848129 elements.
确定峰值单精度处理能力。
mmFlopsHostSingle = (2*NSingle.^3 - NSingle.^2)./mmTimesHostSingle;
[maxFlopsHostSingle,maxFlopsHostSingleIdx] = max(mmFlopsHostSingle);
mmFlopsGPUSingle = (2*NSingle.^3 - NSingle.^2)./mmTimesGPUSingle;
[maxFlopsGPUSingle,maxFlopsGPUSingleIdx] = max(mmFlopsGPUSingle);
fprintf("Achieved peak single-precision processing power on the GPU: %.2f TFLOPS",maxFlopsGPUSingle/1e12)Achieved peak single-precision calculation rate on the GPU: 16.50 TFLOPS
fprintf("Achieved peak single-precision processing power on the host: %.2f TFLOPS",maxFlopsHostSingle/1e12)Achieved peak single-precision calculation rate on the host: 0.83 TFLOPS
绘制双精度和单精度处理能力与数组大小的关系图,并圈出每个情况下的峰值。
figure loglog(NDouble.^2,mmFlopsGPUDouble,MarkerIndices=maxFlopsGPUDoubleIdx,Marker="o") hold on loglog(NSingle.^2,mmFlopsGPUSingle,MarkerIndices=maxFlopsGPUSingleIdx,Marker="o") loglog(NDouble.^2,mmFlopsHostDouble,MarkerIndices=maxFlopsHostDoubleIdx,Marker="o") loglog(NSingle.^2,mmFlopsHostSingle,MarkerIndices=maxFlopsHostSingleIdx,Marker="o") grid on title("Matrix-Matrix Multiply") xlabel("Matrix size (numel)") ylabel("processing power (FLOPS)") legend(["GPU double" "GPU single" "Host double" "Host single"],Location="SouthEast") hold off
结论
这些测试揭示了 GPU 性能的一些重要特征:
从主机内存到 GPU 内存和返回的传输相对较慢。
GPU 读写其内存的速度远快于主机 CPU 读写其内存的速度。
在数据量足够大的情况下,GPU 的计算速度比主机 CPU 更快。
GPU 在单精度计算中比双精度计算更快,而且通常快得多。
值得注意的是,在每次测试中,GPU 需要大型数组才能超越主机 CPU 的性能。GPU 在同时处理数百万个元素时具有最大的优势。
有关更详细的 GPU 性能测试,包括不同 GPU 之间的比较,请参阅 GPUBench 在 MATLAB Central 文件交换中。
另请参阅
gpuArray | gputimeit | gpuDevice | gpuDeviceTable