测量并提高 GPU 性能
测量 GPU 性能
测量 GPU 上的代码性能
代码性能的一个重要衡量标准是运行所需的时间。对在 GPU 上运行的代码进行计时的最佳方式是使用 gputimeit 函数,该函数多次运行一个函数以平均变化并补偿开销。gputimeit 函数还确保在记录时间之前 GPU 上的所有操作都已完成。
例如,测量 lu 函数计算大小为 A×N 的随机矩阵 N 的 LU 因式分解所需的时间。为了执行此测量,请为 lu 函数创建一个函数句柄,并将该函数句柄传递给 gputimeit。
N = 1000;
A = rand(N,"gpuArray");
f = @() lu(A);
numOutputs = 2;
gputimeit(f,numOutputs)您还可以使用 tic 和 toc 来计时您的代码。但是,为了获取在 GPU 上运行的代码的准确时间信息,您必须等待操作完成后才能调用 tic 和 toc。为此,您可以使用 wait 函数并以 gpuDevice 对象作为其输入。例如,测量使用 tic、toc 和 wait 计算矩阵 A 的 LU 分解所花费的时间。
D = gpuDevice; wait(D) tic [L,U] = lu(A); wait(D) toc
您可以使用 MATLAB® Profiler 查看代码每个部分花费的时间。有关分析代码的更多信息,请参阅 profile 和 探查您的代码以改善性能。Profiler 有助于识别代码中的性能瓶颈,但无法准确计时 GPU 代码,因为它没有考虑重叠执行,这在使用 GPU 时很常见。
使用此表可以帮助您决定使用哪种计时方法。
| 计时方法 | 适合的任务 | 限制 |
|---|---|---|
gputimeit | 对各个函数进行计时 |
|
tic 和 toc | 对多行代码或整个工作流进行计时 |
|
| MATLAB 探查器 | 查找性能瓶颈 | Profiler 独立运行每一行代码,并且不考虑重叠执行,这在使用 GPU 时很常见。您不能使用 Profiler 来准确计时 GPU 代码。 |
GPU 基准测试
基准测试有助于识别 GPU 的优势和劣势,并比较不同 GPU 的性能。使用这些基准测试来衡量 GPU 的性能:
运行测量 GPU 内存带宽和处理能力示例以获取有关 GPU 的详细信息,包括 PCI 总线速度、GPU 内存读/写以及双精度矩阵计算的峰值计算性能。
使用
gpuBench来测试单精度和双精度的内存和计算密集型任务。gpuBench可以从 Add-On Explorer 或 MATLAB 中央文件交换中心下载。有关更多信息,请参阅 https://www.mathworks.com/matlabcentral/fileexchange/34080-gpubench。
提高 GPU 性能
MATLAB 中的 GPU 计算的目的是为了加快您的代码速度。通过实施编写代码和配置 GPU 硬件的最佳做法,您可以在 GPU 上获得更好的性能。下面将讨论提高性能的各种方法,从最直接的方法开始。
使用此表可以帮助您决定使用哪种方法。
| 绩效改进方法 | 我应何时使用此方法? | 限制 |
|---|---|---|
使用 GPU 数组 - 将 GPU 数组传递给支持的函数,以在 GPU 上运行代码 | 普遍适用 | 您的函数必须支持 |
探查并改进您的 MATLAB 代码 - 探查您的代码以识别瓶颈 | 普遍适用 | 该探查器不能用于准确计时在 GPU 上运行的代码,如 测量 GPU 上的代码性能 部分所述。 |
向量化计算 - 用矩阵和向量运算替换 for 循环 | 在 for 循环内运行对向量或矩阵进行操作的代码时 | 有关详细信息,请参阅向量化的应用。 |
以单精度执行计算 - 使用较低精度的数据减少计算 | 当可以接受较小范围的数值和较低的精度时 | 某些类型的计算,例如线性代数问题,可能需要双精度处理。 |
使用 |
|
有关支持的函数和其他限制的信息,请参阅 |
使用 | 使用对大量小矩阵执行独立矩阵运算的函数时 | 并非所有内置的 MATLAB 函数都受支持。有关支持的函数和其他限制的信息,请参阅 |
编写包含 CUDA 代码的 MEX 文件 - 访问 GPU 函数的附加库 | 当您想要访问 NVIDIA® 库或高级 CUDA 功能时 | 需要使用 CUDA C++ 框架编写的代码。 |
配置硬件以提高 GPU 性能 - 充分利用您的硬件 | 普遍适用 |
|
使用 GPU 数组
如果您的代码使用的所有函数都受 GPU 支持,则唯一需要的修改是通过调用 gpuArray 将输入数据传输到 GPU。有关支持 gpuArray 输入的 MATLAB 函数列表,请参阅 在 GPU 上运行 MATLAB 函数。
gpuArray 对象将数据存储在 GPU 内存中。由于 MATLAB 和许多其他工具箱中的大多数数值函数都支持 gpuArray 对象,因此您通常只需进行最少的更改即可在 GPU 上运行代码。这些函数接受 gpuArray 输入,在 GPU 上执行计算,并返回 gpuArray 输出。通常,这些函数支持与在 CPU 上运行的标准 MATLAB 函数相同的参量和数据类型。
提示
为了减少开销,请限制在主机内存和 GPU 之间传输数据的次数。尽可能直接在 GPU 上创建数组。有关详细信息,请参阅直接创建 GPU 数组。类似地,仅当需要在不支持 gpuArray 对象的代码中显示、保存或使用数据时,才使用 gather 将数据从 GPU 传输回主机内存。
探查并改进您的 MATLAB 代码
在将 MATLAB 代码转换为在 GPU 上运行的代码时,最好从已经运行良好的 MATLAB 代码开始。许多编写在 CPU 上运行良好的代码的指南也将提高在 GPU 上运行的代码的性能。您可以使用 MATLAB Profiler 探查您的 CPU 代码。在 CPU 上花费时间最多的代码行很可能是您应该改进的代码行,或者考虑使用 gpuArray 对象将其转移到 GPU 上。有关分析代码的更多信息,请参阅 探查您的代码以改善性能。
由于 MATLAB Profiler 独立运行每一行代码,因此它不考虑重叠执行,这在使用 GPU 时很常见。要对整个算法进行计时,请使用 tic 和 toc 或 gputimeit,如 测量 GPU 上的代码性能 部分所述。
向量化计算
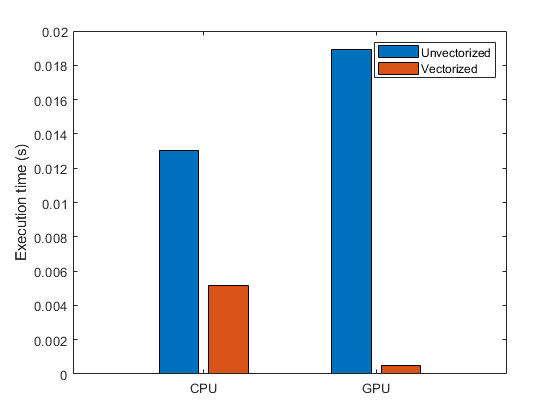
在 GPU 上,向量、矩阵和高维运算通常比标量运算表现更好,因为 GPU 通过并行计算许多结果来实现高性能。您可以通过重写循环来利用更高维的操作,从而获得更好的性能。修正基于循环且面向标量的代码以使用 MATLAB 矩阵和向量运算的过程称为向量化。有关向量化的信息,请参阅 向量化的应用 和 使用 GPU 和向量化计算提高性能。来自 使用 GPU 和向量化计算提高性能 示例的此图显示了通过向量化在 CPU 和 GPU 上执行的函数所实现的性能提升。
以单精度执行计算
您可以通过使用单精度浮点运算而非双精度浮点运算来提升 GPU 上运行的代码性能,因为 GPU 通常拥有更多的单精度浮点运算单元 (FPUs) 而非双精度浮点运算单元。相比之下,CPU 计算在单精度和双精度数据上的性能通常相似。
您可以使用 single 函数将数据转换为单精度,或者在使用创建函数(如 rand)创建数据时,通过指定底层类型 "single" 和数据类型 "gpuArray" 直接创建单精度 gpuArray 数据。有关将数据转换为单精度以及直接创建单精度数据的更多信息,请参阅 在 GPU 上建立数组。
适合 GPU 上单精度计算的工作流的典型示例包括图像处理和机器学习。然而,其他类型的计算,例如线性代数问题,通常需要双精度处理。Deep Learning Toolbox™ 默认以单精度执行许多操作。有关详细信息,请参阅Deep Learning Precision (Deep Learning Toolbox)。
具体的性能提升取决于 GPU 卡和核心总数。要大致测量 GPU 在单精度与双精度下的相对性能,请查询设备的 SingleDoubleRatio 属性。此属性描述设备上单精度 FPU 与双精度 FPU 的比例。
gpu = gpuDevice; gpu.SingleDoubleRatio
大多数台式机 GPU 的单精度浮点运算单元数量是双精度浮点运算单元的 24 倍、32 倍,甚至 64 倍,而部分数据中心 GPU(如 A100 和 H100)的双精度浮点运算单元数量仅为单精度浮点运算单元的 2 倍。
有关 NVIDIA GPU 卡的全面性能概述,包括单精度和双精度处理能力,请参阅 https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units。
提高元素级函数的性能
如果您有一个元素函数,您通常可以通过使用 arrayfun 调用它来提高其性能。GPU 上的 arrayfun 函数将一个元素级别的 MATLAB 函数转换为自定义 CUDA 内核,从而减少执行该操作的开销。即使 arrayfun 不支持您的整个代码,您通常也可以将 arrayfun 与代码子集一起使用。使用 arrayfun 可以提高各种元素函数的性能,包括在循环或分支代码中执行许多元素操作的函数,以及嵌套函数访问其父函数中声明的变量的嵌套函数。
使用 arrayfun 提高 GPU 上元素级 MATLAB 函数的性能 示例展示了 arrayfun 的基本应用。使用 GPU arrayfun 进行蒙特卡罗仿真 示例显示使用 arrayfun 来提高循环内执行逐元素操作的函数的性能。GPU 上的模板操作 示例显示 arrayfun 用于调用嵌套函数,该嵌套函数访问父函数中声明的变量。
提高小矩阵运算的性能
如果您有一个对大量小矩阵执行独立矩阵运算的函数,则可以通过使用 pagefun 调用它来提高其性能。您可以使用 pagefun 在 GPU 上并行执行矩阵运算,而不是循环矩阵。使用 pagefun 提高 GPU 上小矩阵问题的性能 示例展示了如何在对许多小矩阵进行运算时使用 pagefun 来提高性能。
编写包含 CUDA 代码的 MEX 文件
虽然 MATLAB 提供了一个广泛的支持 GPU 的函数库,但您可以访问 MATLAB 中没有类似物的其他函数库。示例包括 NVIDIA 库,例如 NVIDIA 性能原语 (NPP) 和 cuRAND 库。您可以使用 mexcuda 函数编译在 CUDA C++ 框架中编写的 MEX 文件。您可以在 MATLAB 中执行已编译的 MEX 文件并调用 NVIDIA 库中的函数。有关如何编写和运行接受 gpuArray 输入并返回 gpuArray 输出的 MEX 函数的示例,请参阅 运行包含 CUDA 代码的 MEX 函数。
配置硬件以提高 GPU 性能
由于许多计算需要大量内存,并且大多数系统不断使用 GPU 进行图形处理,因此使用相同的 GPU 进行计算和图形处理通常是不切实际的。
在 Windows® 系统上,GPU 设备有两种操作模型:Windows 显示驱动模型 (WDDM) 或 Tesla 计算集群 (TCC)。为了使您的代码获得最佳性能,请将用于计算的设备设置为使用 TCC 模型。要查看您的 GPU 设备正在使用哪种型号,请检查 gpuDevice 函数返回的 DriverModel 属性。有关切换模型以及哪些 GPU 设备支持 TCC 模型的更多信息,请查阅 NVIDIA 文档。
为了降低 GPU 内存耗尽的可能性,请勿在 MATLAB 的多个实例上使用一个 GPU。要查看哪些 GPU 设备可用且已被选择,请使用 gpuDeviceTable 函数。
另请参阅
gpuDevice | gputimeit | tic | toc | gpuArray | arrayfun | pagefun | mexcuda