使用 GPU 和向量化计算提高性能
此示例展示了如何通过在 GPU 而不是 CPU 上运行函数以及向量化计算来加快代码速度。
MATLAB® 针对涉及矩阵和向量的运算进行了优化。修改基于循环、面向标量的代码以使用 MATLAB 矩阵和向量运算的过程称为向量化。向量化代码通常比相应的基于循环的代码运行得更快,并且通常更短且更容易理解。有关向量化的介绍,请参阅 向量化的应用。
此示例比较了函数向量化之前和之后在 CPU 和 GPU 上执行的函数的执行时间。
GPU 和 CPU 上基于时间循环的函数执行
快速卷积是信号处理应用中的常见操作。快速卷积运算包括以下步骤。
将每列数据从时间域转换到频域。
将频域数据与滤波器向量的变换相乘。
将过滤后的数据转换回时间域并将结果存储在矩阵中。
本节使用 fastConvolution 支持函数对矩阵执行快速卷积。该函数定义在本示例的末尾。
创建随机、复杂的输入数据和随机过滤向量。
data = complex(randn(4096,100),randn(4096,100)); filter = randn(16,1);
在 CPU 上使用 fastConvolution 函数对数据执行快速卷积,并使用timeit函数测量执行时间。
CPUtime = timeit(@() fastConvolution(data,filter))
CPUtime = 0.0148
确保您想要的 GPU 可用且已被选择。
gpu = gpuDevice;
disp(gpu.Name + " GPU selected.")NVIDIA RTX A5000 GPU selected.
通过将输入数据更改为 gpuArray 对象而不是普通的 MATLAB 数组来在 GPU 上执行该函数。由于 fastConvolution 函数使用 zeros函数的 like 语法,因此如果 gpuArray 是 data,则输出为 gpuArray。要对 GPU 上的函数执行进行计时,请使用 gputimeit。对于使用 GPU 的函数,使用 gputimeit 而不是 timeit,因为 gputimeit 可确保 GPU 上的所有操作在记录经过的时间之前完成。对于这个特定问题,该函数在 GPU 上执行的时间比在 CPU 上执行的时间更长。原因是 for 循环对长度为 4096 的各个列执行快速傅里叶变换 (FFT)、乘法和逆 FFT (IFFT) 运算。对每一列单独执行这些操作并不能有效利用 GPU 的计算能力,因为 GPU 在执行大量操作时通常会更有效。
gData = gpuArray(data); gFilter = gpuArray(filter); GPUtime = gputimeit(@() fastConvolution(gData,gFilter))
GPUtime = 0.0158
CPU 和 GPU 上向量化函数的执行时间
向量化代码是提高其性能的直接方法。您可以通过将所有数据作为输入传递来实现 FFT 和 IFFT 操作的向量化,而不是在 for 循环内单独传递每一列。乘法运算符 .* 将过滤器一次性与矩阵中的每一列相乘。本示例末尾提供了向量化的支持函数 fastConvolutionVectorized。要了解函数如何向量化,请比较支持函数 fastConvolution 和 fastConvolutionVectorized。
使用向量化函数执行相同的计算,并将时间结果与非向量化函数的执行进行比较。
CPUtimeVectorized = timeit(@() fastConvolutionVectorized(data,filter))
CPUtimeVectorized = 0.0062
GPUtimeVectorized = gputimeit(@() fastConvolutionVectorized(gData,gFilter))
GPUtimeVectorized = 4.5339e-04
CPUspeedup = CPUtime/CPUtimeVectorized
CPUspeedup = 2.3887
GPUspeedup = GPUtime/GPUtimeVectorized
GPUspeedup = 34.9468
bar(categorical(["CPU" "GPU"]), ... [CPUtime CPUtimeVectorized; GPUtime GPUtimeVectorized], ... "grouped") ylabel("Execution Time (s)") legend("Unvectorized","Vectorized") grid on
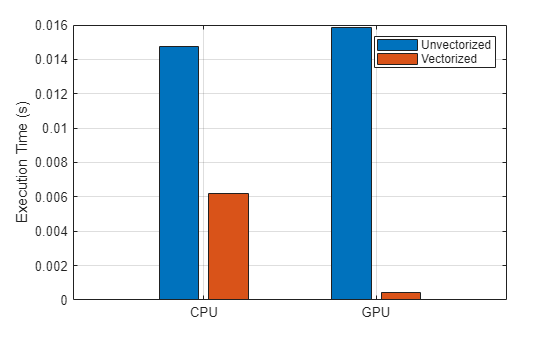
对代码进行向量化可以提高 CPU 和 GPU 的性能。然而,向量化对 GPU 性能的提升远大于对 CPU 性能的提升。向量化的函数在 CPU 上的运行速度大约是基于循环的函数的 2.4 倍,而在 GPU 上的运行速度大约是基于循环的函数的 34.9 倍。基于循环的函数在 GPU 上的运行速度比在 CPU 上慢 7%,但向量化的函数在 GPU 上的运行速度比在 CPU 上快约 13.6 倍。
当您将本示例中描述的技术应用到您自己的代码中时,性能的提升将在很大程度上取决于您的硬件和您运行的代码。
支持函数
通过将每列数据从时间域转换到频域,将其乘以滤波器向量的变换,再转换回时间域,并将结果存储在输出矩阵中,执行快速卷积运算。
function y = fastConvolution(data,filter) % Zero-pad filter to the column length of data, and transform. [rows,cols] = size(data); filter_f = fft(filter,rows); % Create an array of zeros of the same size and class as data. y = zeros(rows,cols,like=data); for idx = 1:cols % Transform each column of data data_f = fft(data(:,idx)); % Multiply each column by filter and compute inverse transform. y(:,idx) = ifft(filter_f.*data_f); end end
执行快速卷积运算,用向量运算替换 for 循环。
function y = fastConvolutionVectorized(data,filter) % Zero-pad filter to the length of data, and transform. [rows,~] = size(data); filter_f = fft(filter,rows); % Transform each column of the input. data_f = fft(data); % Multiply each column by filter and compute inverse transform. y = ifft(filter_f.*data_f); end
另请参阅
gpuArray | gputimeit | fft | ifft