GPU 上的模板操作
此示例使用康威的“生命游戏”来演示如何使用 GPU 执行模板操作。
许多数组操作可以表示为“模板操作”,其中输出数组的每个元素都依赖于输入数组的一小部分区域。示例包括有限差分、卷积、中值滤波和有限元方法。本示例使用康威的“生命游戏”演示了在 GPU 上运行模板操作的两种方法,从 Cleve Moler 的电子书 MATLAB 中的试验中的代码开始。
“生命游戏”遵循一些简单的规则:
细胞排列在二维网格中
每一步,每个细胞的命运都由其八个最近邻居的活力决定
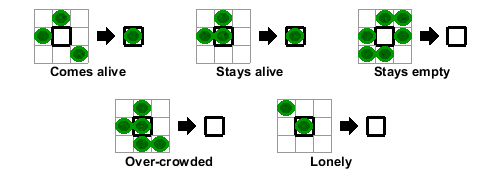
任何恰好有三个活邻居的细胞在下一步中都会复活
一个恰好有两个活邻居的活细胞在下一步中仍然活着
所有其他细胞(包括那些有三个以上邻居的细胞)在下一步中死亡或保持空置
因此,在这种情况下,“模板”是每个元素周围的 3x3 区域。以下是一些单元格如何更新的示例:
此示例是一个允许使用嵌套函数的函数:
function paralleldemo_gpu_stencil()
生成随机初始种群
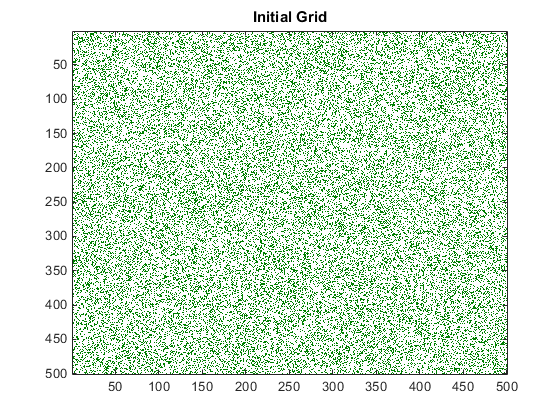
在二维网格上创建初始细胞群,其中大约 25% 的位置是存活的。
gridSize = 500; numGenerations = 100; initialGrid = (rand(gridSize,gridSize) > .75); gpu = gpuDevice(); % Draw the initial grid hold off imagesc(initialGrid); colormap([1 1 1;0 0.5 0]); title('Initial Grid');
玩生命游戏
电子书 MATLAB 中的试验提供了可用于比较的初步实现。此版本已完全向量化,每代一次更新网格中的所有单元。
function X = updateGrid(X, N) p = [1 1:N-1]; q = [2:N N]; % Count how many of the eight neighbors are alive. neighbors = X(:,p) + X(:,q) + X(p,:) + X(q,:) + ... X(p,p) + X(q,q) + X(p,q) + X(q,p); % A live cell with two live neighbors, or any cell with % three live neighbors, is alive at the next step. X = (X & (neighbors == 2)) | (neighbors == 3); end grid = initialGrid; % Loop through each generation updating the grid and displaying it for generation = 1:numGenerations grid = updateGrid(grid, gridSize); imagesc(grid); title(num2str(generation)); drawnow; end
现在重新运行游戏并测量每一代需要多长时间。
grid = initialGrid; timer = tic(); for generation = 1:numGenerations grid = updateGrid(grid, gridSize); end cpuTime = toc(timer); fprintf('Average time on the CPU: %2.3fms per generation.\n', ... 1000*cpuTime/numGenerations);
Average time on the CPU: 11.323ms per generation.
保留此结果以验证下面各个版本的正确性。
expectedResult = grid;
将生命游戏转换为在 GPU 上运行
为了在 GPU 上运行生命游戏,需要使用 gpuArray 将初始种群发送到 GPU。算法保持不变。注意,wait 用于确保在计时器停止之前 GPU 已经完成计算。这只是为了准确计时才需要的。
grid = gpuArray(initialGrid); timer = tic(); for generation = 1:numGenerations grid = updateGrid(grid, gridSize); end wait(gpu); % Only needed to ensure accurate timing gpuSimpleTime = toc(timer); % Print out the average computation time and check the result is unchanged. fprintf(['Average time on the GPU: %2.3fms per generation ', ... '(%1.1fx faster).\n'], ... 1000*gpuSimpleTime/numGenerations, cpuTime/gpuSimpleTime); assert(isequal(grid, expectedResult));
Average time on the GPU: 1.655ms per generation (6.8x faster).
为 GPU 创建元素版本
查看 updateGrid 函数中的计算,显然相同的操作在每个网格位置独立应用。这表明可以使用arrayfun进行评估。然而,每个单元都需要了解它的八个邻居,从而破坏了元素间的独立性。每个元素都需要能够访问整个电网,同时也能独立工作。
解决方案是使用嵌套函数。嵌套函数(即使是与 arrayfun 一起使用的函数)可以访问其父函数中声明的变量。这意味着每个单元都可以从前一个时间步骤读取整个网格并将其编入索引。
grid = gpuArray(initialGrid);
function X = updateParentGrid(row, col, N)
% Take account of boundary effects
rowU = max(1,row-1); rowD = min(N,row+1);
colL = max(1,col-1); colR = min(N,col+1);
% Count neighbors
neighbors ...
= grid(rowU,colL) + grid(row,colL) + grid(rowD,colL) ...
+ grid(rowU,col) + grid(rowD,col) ...
+ grid(rowU,colR) + grid(row,colR) + grid(rowD,colR);
% A live cell with two live neighbors, or any cell with
% three live neighbors, is alive at the next step.
X = (grid(row,col) & (neighbors == 2)) | (neighbors == 3);
end
timer = tic();
rows = gpuArray.colon(1, gridSize)';
cols = gpuArray.colon(1, gridSize);
for generation = 1:numGenerations
grid = arrayfun(@updateParentGrid, rows, cols, gridSize);
end
wait(gpu); % Only needed to ensure accurate timing
gpuArrayfunTime = toc(timer);
% Print out the average computation time and check the result is unchanged.
fprintf(['Average time using GPU arrayfun: %2.3fms per generation ', ...
'(%1.1fx faster).\n'], ...
1000*gpuArrayfunTime/numGenerations, cpuTime/gpuArrayfunTime);
assert(isequal(grid, expectedResult));
Average time using GPU arrayfun: 0.795ms per generation (14.2x faster).
注意我们在这里还使用了arrayfun的另一个新功能:维度扩展。我们只需要传递行和列向量,它们会自动扩展为完整网格。其效果就像我们调用:
[cols,rows] = meshgrid(cols,rows);
作为 arrayfun 调用的一部分。这为我们节省了一些计算以及 CPU 内存和 GPU 内存之间的一些数据传输。
结论
在此示例中,已经使用 arrayfun 和父函数中声明的变量在 GPU 上实现了一个简单的模板操作,即康威的“生命游戏”。该技术可用于实现一系列模板操作,包括有限元算法、卷积和过滤器。它还可用于访问父函数中定义的查找表中的元素。
fprintf('CPU: %2.3fms per generation.\n', ... 1000*cpuTime/numGenerations); fprintf('Simple GPU: %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuSimpleTime/numGenerations, cpuTime/gpuSimpleTime); fprintf('Arrayfun GPU: %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuArrayfunTime/numGenerations, cpuTime/gpuArrayfunTime);
CPU: 11.323ms per generation. Simple GPU: 1.655ms per generation (6.8x faster). Arrayfun GPU: 0.795ms per generation (14.2x faster).
end
另请参阅
gpuArray | mexcuda | gputimeit