使用 MEX 访问高级 CUDA 功能
此示例展示了如何使用 MEX 文件访问 GPU 的高级功能。它以示例 GPU 上的模板操作 为基础。前面的示例使用康威的“生命游戏”来演示如何使用在 GPU 上运行的 MATLAB® 代码执行模板操作。本示例演示如何使用 GPU 的高级功能(共享内存)进一步提高模板操作的性能。您可以通过在 MEX 文件中编写自己的 CUDA® 代码并从 MATLAB 调用 MEX 文件来实现此目的。您可以在 运行包含 CUDA 代码的 MEX 函数 中找到有关 MEX 文件中使用 GPU 的介绍。
正如前面的示例所定义的,在“模板操作”中,输出数组的每个元素都依赖于输入数组的一小部分区域。示例包括有限差分、卷积、中值滤波和有限元方法。如果模板操作是您工作流的关键部分,则可以将其转换为手写的 CUDA 内核。此示例使用康威的“生命游戏”作为我们的模板操作,并将计算移至 MEX 文件中。因此,在这种情况下,“模板”是每个元素周围的 3x3 区域。
“生命游戏”遵循一些简单的规则:
细胞排列在二维网格中
每一步,每个细胞的命运都由其八个最近邻居的活力决定
任何恰好有三个活邻居的细胞在下一步中都会复活
一个恰好有两个活邻居的活细胞在下一步中仍然活着
所有其他细胞(包括那些有三个以上邻居的细胞)在下一步中死亡或保持空置
生成随机初始种群
在二维网格上创建初始细胞群,大约 25% 的位置为活细胞。
gridSize = 500;
numGenerations = 200;
initialGrid = (rand(gridSize,gridSize) > .75);
hold off
imagesc(initialGrid);
colormap([1 1 1;0 0.5 0]);
title('Initial Grid');
在 MATLAB 中创建基线 GPU 版本
要获得性能基准,请从MATLAB 中的试验中描述的初始实现开始。通过确保初始种群使用 gpuArray 在 GPU 上,在 GPU 上运行此实现。函数 updateGrid 在本示例的末尾提供。updateGrid 统计有多少邻居存活,并决定单元格在下一步是否存活。
currentGrid = gpuArray(initialGrid); % Loop through each generation updating the grid and displaying it for generation = 1:numGenerations currentGrid = updateGrid(currentGrid, gridSize); imagesc(currentGrid); title(num2str(generation)); drawnow; end

重新运行游戏并测量每一代需要多长时间。为了使用 gputimeit 对整个游戏进行计时,在本示例的末尾提供了一个调用每一代的函数 callUpdateGrid。
gpuInitialGrid = gpuArray(initialGrid); % Retain this result to verify the correctness of each version below expectedResult = callUpdateGrid(gpuInitialGrid, gridSize, numGenerations); gpuBuiltinsTime = gputimeit(@() callUpdateGrid(gpuInitialGrid, ... gridSize, numGenerations)); fprintf('Average time on the GPU: %2.3fms per generation \n', ... 1000*gpuBuiltinsTime/numGenerations);
Average time on the GPU: 0.521ms per generation
创建一个使用共享内存的 MEX 版本
在编写 CUDA 内核版本的模板操作时,您必须将输入数据分成每个线程块都可以操作的块。块中的每个线程都将读取块中其他线程所需的数据。减少读取操作次数的一种方法是在处理之前将所需的输入数据复制到共享内存中。此副本必须包含一些相邻元素,以便正确计算块边缘。对于生命游戏,其中模板只是一个 3x3 的元素方块,因此需要一个元素边界。例如,对于使用 3x3 块处理的 9x9 网格,第五个块将对橙色突出显示的区域进行操作,其中黄色元素是它也必须读取的“光环”。
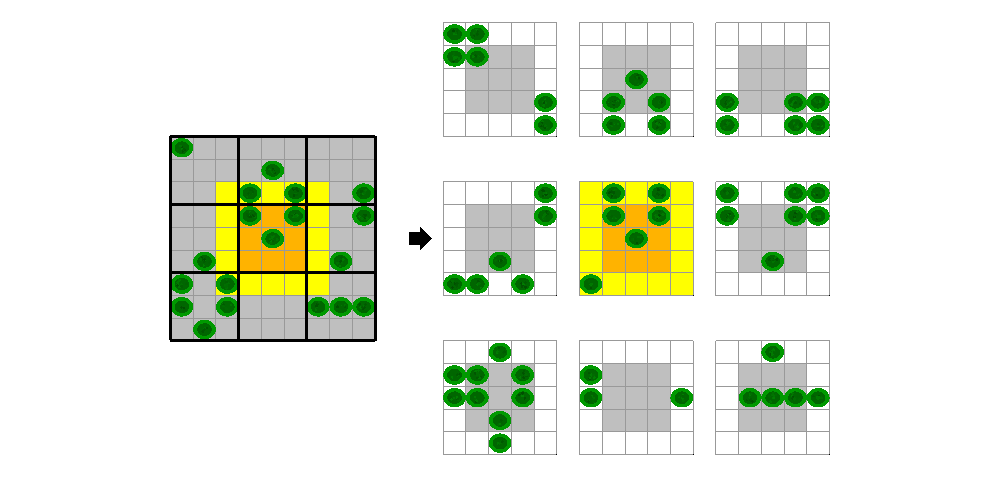
说明此方法的 CUDA 代码显示在支持文件 pctdemo_life_cuda_shmem.cu 中。要访问此支持文件,请将此示例作为实时脚本打开。此文件中的 CUDA 设备函数操作如下:
所有线程将输入网格的相关部分复制到共享内存中,包括光环。
线程彼此同步以确保共享内存已准备就绪。
适合输出网格的线程执行生命游戏计算。
此文件中的主机代码使用 CUDA 运行时 API 对每一代调用一次 CUDA 设备函数。它使用两个不同的可写缓冲区进行输入和输出。在每次迭代中,MEX 文件都会交换输入和输出指针,因此不需要复制。
为了从 MATLAB 调用该函数,您需要一个 MEX 网关来解开来自 MATLAB 的输入数组,在 GPU 上构建工作区,并返回输出。MEX 网关函数可以在支持文件 pctdemo_life_mex_shmem.cpp 中找到。
要调用您自己的 MEX 文件,您必须首先使用 mexcuda 进行编译。将 pctdemo_life_cuda_shmem.cu 和 pctdemo_life_mex_shmem.cpp 编译为名为 pctdemo_life_mex_shmem 的 MEX 函数。
mexcuda -output pctdemo_life_mex_shmem pctdemo_life_cuda_shmem.cu pctdemo_life_mex_shmem.cpp
Building with 'NVIDIA CUDA Compiler'. MEX completed successfully.
% Calculate the output value using the MEX file with shared memory. The % initial input value is copied to the GPU inside the MEX file grid = pctdemo_life_mex_shmem(initialGrid, numGenerations); gpuMexTime = gputimeit(@()pctdemo_life_mex_shmem(initialGrid, ... numGenerations)); % Print out the average computation time and check the result is unchanged fprintf('Average time of %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuMexTime/numGenerations, gpuBuiltinsTime/gpuMexTime);
Average time of 0.007ms per generation (72.5x faster).
assert(isequal(grid, expectedResult));
结论
此示例说明了一种通过在处理之前明确将块复制到共享内存中来减少读取操作次数的方法。使用此方法获得的性能改进取决于模板的大小、重叠区域的大小以及 GPU 的功能。您可以将此方法与 MATLAB 代码结合使用来优化您的应用程序。
fprintf('Using gpuArrays: %2.3fms per generation.\n', ... 1000*gpuBuiltinsTime/numGenerations);
Using gpuArrays: 0.521ms per generation.
fprintf(['Using MEX with shared memory: %2.3fms per generation ',... '(%1.1fx faster).\n'], 1000*gpuMexTime/numGenerations, ... gpuBuiltinsTime/gpuMexTime);
Using MEX with shared memory: 0.007ms per generation (72.5x faster).
支持函数
此 updateGrid 函数根据存活的邻居数量更新 2-D 网格。
function X = updateGrid(X, N) p = [1 1:N-1]; q = [2:N N]; % Count how many of the eight neighbors are alive neighbors = X(:,p) + X(:,q) + X(p,:) + X(q,:) + ... X(p,p) + X(q,q) + X(p,q) + X(q,p); % A live cell with two live neighbors, or any cell with % three live neighbors, is alive at the next step X = (X & (neighbors == 2)) | (neighbors == 3); end
callUpdateGrid 函数调用 updateGrid 进行多代。
function grid=callUpdateGrid(grid, gridSize, N) for gen = 1:N grid = updateGrid(grid, gridSize); end end
另请参阅
gpuArray | mexcuda | gputimeit