使用共存分布式数组
MATLAB 软件如何分配数组
当您对一个数组分区,划分多个工作单元时,MATLAB® 软件会将数组划分为多个段,并将该数组的一个段分配给每个工作单元。您可以对二维数组进行水平分区,将原始数组的列分配给不同的工作单元,或垂直分割,分配行。具有 N 个维度的数组可以沿着其 N 维中的任意一个进行分区。您可以通过在数组构造函数命令中指定来选择要对数组的哪个维度进行分区。
例如,要将一个 80×1000 的数组分配给四个工作单元,您可以按列对其进行分区,为每个工作单元提供一个 80×250 的段,或者按行对其进行分区,为每个工作单元提供一个 20×1000 的段。如果数组维度不能均匀地划分工作单元数量,则 MATLAB 会尽可能均匀地对其进行划分。
下面的示例创建一个 80×1000 的复制数组并将其分配给变量 A。在这样做时,每个工作单元在自己的工作区中创建一个相同的数组,并将其分配给变量 A,其中 A 是该工作单元的本地。第二条命令分发 A,创建一个跨越所有四个工作单元的 80×1000 的数组 D。工作单元 1 存储第 1 列到第 250 列,工作单元 2 存储第 251 列到第 500 列,依此类推。默认分布是按最后一个非单一维度进行的,因此,在这种情况下是二维数组的列。
spmd
A = zeros(80, 1000);
D = codistributed(A)
end
Worker 1: This worker stores D(:,1:250).
Worker 2: This worker stores D(:,251:500).
Worker 3: This worker stores D(:,501:750).
Worker 4: This worker stores D(:,751:1000).
每个工作单元都可以访问数组的所有段。访问本地地段比访问远程段更快,因为后者需要在工作单元之间发送和接收数据,因此需要更多时间。
MATLAB 如何显示共存分布式数组
对于每个工作单元,MATLAB 并行命令行窗口显示有关共存分布式数组、本地部分和共存分布器的信息。例如,一个 8×8 的单位矩阵在四个工作单元之间共存分布,每个工作单元有两列,显示如下:
>> spmd
II = eye(8,"codistributed")
end
Worker 1:
This worker stores II(:,1:2).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 2:
This worker stores II(:,3:4).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 3:
This worker stores II(:,5:6).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 4:
This worker stores II(:,7:8).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]要查看数组本地地段中的实际数据,请使用 getLocalPart 函数。
分配给每个工作单元多少
在分配 N 行数组时,如果 N 可以被工作单元数量整除,则 MATLAB 会在每个工作单元上存储相同数量的行 (N/spmdSize)。当该数字不能被工作单元数量整除时,MATLAB 会尽可能均匀地对数组进行分区。
MATLAB 提供了称为 Dimension 和 Partition 的 codistributor 对象属性,您可以使用它们来确定数组的精确分布。有关使用共存分布式数组进行索引的更多信息,请参阅 索引到共存分布式数组。
其他数据类型的分布
您可以分发任何 MATLAB 内置数据类型的数组,也可以分发复杂或稀疏的数值数组,但不能分发函数句柄或对象类型的数组。
创建共存分布式数组
您可以通过以下任一方式创建共存分布式数组:
对较大的数组进行分区 - 从在所有工作单元上复制的大型数组开始,然后对其进行分区,以便将各个部分分布在各个工作单元上。当您有足够的内存来存储初始复制数组时,这非常有用。
从较小的数组构建 - 从存储在每个工作单元上的较小的变体或复制数组开始,然后将它们组合起来,以便每个数组成为更大的共存分布式数组的一部分。这种方法允许您从较小的部分构建共存分布式数组,从而减少内存要求。
使用 MATLAB 构造函数 - 使用任何 MATLAB 构造函数(例如
rand或zeros)以及 codistributor 对象参量。这些函数提供了一种快速构建任意大小的共存分布式数组的方法,只需一步。
对较大的数组进行分区
如果内存中已经有一个大型数组,并且您希望 MATLAB 能够更快地处理它,则可以将其划分成几个较小的段,然后使用 codistributed 函数将这些段分发给所有工作单元。然后,每个工作单元都会拥有一个数组仅为原始大小一小部分的数组,从而减少了访问每个工作单元本地数据所需的时间。
举一个简单的示例,下面的代码行在分配给变量 A 的每个工作单元上创建一个 4×8 的复制矩阵:
spmd, A = [11:18; 21:28; 31:38; 41:48], end
A =
11 12 13 14 15 16 17 18
21 22 23 24 25 26 27 28
31 32 33 34 35 36 37 38
41 42 43 44 45 46 47 48下一行使用 codistributed 函数构造一个沿数组的第二个维度分布的单个 4×8 矩阵 D:
spmd
D = codistributed(A);
getLocalPart(D)
end
1: Local Part | 2: Local Part | 3: Local Part | 4: Local Part
11 12 | 13 14 | 15 16 | 17 18
21 22 | 23 24 | 25 26 | 27 28
31 32 | 33 34 | 35 36 | 37 38
41 42 | 43 44 | 45 46 | 47 48数组 A 和 D 大小相同(4×8)。数组 A 的完整大小在每个工作单元上都存在,而数组 D 仅存在一部分在每个工作单元上。
spmd, size(A), size(D), end
检查客户端工作区中的变量,在 spmd 语句内部的工作单元之间共存分布的数组,从 spmd 语句外部的客户端的角度来看是一个分布式数组。Spmd 内部的非共存分布式变量是 spmd 外部客户端中的 Composite。
whos Name Size Bytes Class Attributes A 1x4 489 Composite D 4x8 256 distributed
有关语法和使用信息,请参阅 codistributed 函数参考页。
从较小的数组构建
当您首先在一个工作区中构建完整数组,然后将其划分为分布式段时,codistributed 函数对于减少存储数据所需的内存量不太有用。为了节省内存,您可以首先在每个工作单元上构建较小的片段(本地部分),然后使用 codistributed.build 将它们组合成分布在各个工作单元上的单个数组。
此示例在 4 个工作单元上分别创建一个 4×250 的变体数组 A,然后使用 codistributor 将这些段分布在 4 个工作单元上,从而创建一个 16×250 的共存分布式数组。这是变体数组,A:
spmd
A = [1:250; 251:500; 501:750; 751:1000] + 250 * (spmdIndex - 1);
end
WORKER 1 WORKER 2 WORKER 3
1 2 ... 250 | 251 252 ... 500 | 501 502 ... 750 | etc.
251 252 ... 500 | 501 502 ... 750 | 751 752 ...1000 | etc.
501 502 ... 750 | 751 752 ...1000 | 1001 1002 ...1250 | etc.
751 752 ...1000 | 1001 1002 ...1250 | 1251 1252 ...1500 | etc.
| | |现在将这些段组合成按第一个维度(行)分布的数组。该数组现在为 16×250,每个工作单元上都有一个 4×250 的段:
spmd
D = codistributed.build(A, codistributor1d(1,[4 4 4 4],[16 250]))
end
Worker 1:
This worker stores D(1:4,:).
LocalPart: [4x250 double]
Codistributor: [1x1 codistributor1d]
whos
Name Size Bytes Class Attributes
A 1x4 489 Composite
D 16x250 32000 distributed 如果您想要创建一个各段一开始都相同的共存分布式数组,那么您也可以以相同的方式使用复制数组。有关语法和使用信息,请参阅 codistributed 函数参考页。
使用 MATLAB 构造函数
MATLAB 提供了几个数组构造函数,您可以使用它们来构建特定值、大小和类的共存分布式数组。这些函数的操作方式与 MATLAB 语言中的非分布式对应函数相同,不同之处在于它们使用指定的协同分布器对象 codist 将结果数组分配给各个工作单元。
构造函数. 共存分布式构造函数列于此处。使用 codist 参量(由 codistributor 函数创建:codist=codistributor())来指定在哪个维度上分布数组。有关更多语法和使用信息,请参阅这些函数的单独参考页。
eye(___,codist)false(___,codist)Inf(___,codist)NaN(___,codist)ones(___,codist)rand(___,codist)randi(___,codist)randn(___,codist)true(___,codist)zeros(___,codist)codistributed.cell(m,n,...,codist)codistributed.colon(a,d,b) codistributed.linspace(m,n,...,codist) codistributed.logspace(m,n,...,codist)sparse(m,n,codist)codistributed.speye(m,...,codist)codistributed.sprand(m,n,density,codist)codistributed.sprandn(m,n,density,codist)
本地数组
驻留在每个工作单元上的共存分布式数组的一部分是一个更大数组的一部分。每个工作单元可以在公共数组的自己的段上进行工作,或者可以在自己的变体或私有数组中复制该段。这个共存分布式数组段的本地副本称为本地数组。
从共存分布式数组创建本地数组
getLocalPart 函数将共存分布式数组的各段复制到单独的变体数组。此示例为共存分布式数组 L 的每个段创建了一份本地副本 D。L 的大小表明它仅包含每个工作单元的 D 的本地部分。假设您将一个数组分配给四个工作单元:
spmd(4)
A = [1:80; 81:160; 161:240];
D = codistributed(A);
size(D)
L = getLocalPart(D);
size(L)
end
每个工作单元的返回值:
3 80 3 20
每个工作单元都认识到共存分布式数组 D 是 3×80 的。但是,请注意本地部分 L 的大小在每个工作单元上都是 3×20,因为 D 的 80 列分布在 4 个工作单元上。
从本地数组创建共存分布式数组
使用 codistributed.build 函数执行反向操作。该函数在 从较小的数组构建 中描述,将本地变体变量数组组合成沿指定维度分布的单个数组。
继续前面的示例,取本地变体数组 L 并将它们作为段放在一起以构建新的共存分布式数组 X。
spmd codist = codistributor1d(2,[20 20 20 20],[3 80]); X = codistributed.build(L,codist); size(X) end
每个工作单元的返回值:
3 80
获取有关数组的信息
MATLAB 提供了几个函数,可以提供任何特定数组的信息。除了这些标准函数之外,还有两个仅对共存分布式数组有用的函数。
确定数组是否为共存分布式
如果输入数组是共存分布的,则 iscodistributed 函数返回逻辑 1 (true),否则返回逻辑 0 (false)。语法是
spmd, TF = iscodistributed(D), end
其中 D 是任何 MATLAB 数组。
确定分布的维度
Codistributor 对象决定数组的分区方式及其分布的维度。要访问数组的协同分布器,请使用 getCodistributor 函数。这将返回两个属性,Dimension 和 Partition:
spmd, getCodistributor(X), end
Dimension: 2
Partition: [20 20 20 20]
Dimension 的 2 值表示数组 X 按列分布(维度 2);Partition 的 [20 20 20 20] 值表示 4 个工作单元上各有 20 列。
要以编程方式获取这些属性,请将 getCodistributor 的输出返回给变量,然后使用点符号访问每个属性:
spmd
C = getCodistributor(X);
part = C.Partition
dim = C.Dimension
end其他数组函数
提供有关标准数组信息的其他函数也适用于共存分布式数组并使用相同的语法。
改变分布的维度
构造数组时,可以沿数组的某个维度分布数组的各个部分。您可以使用具有不同 codistributor 对象的 redistribute 函数来更改现有数组上此分布的方向。
构建一个 8×16 的共存分布式数组 D,其中包含按四个工作单元上的列分布的随机值:
spmd
D = rand(8,16,codistributor());
size(getLocalPart(D))
end每个工作单元的返回值:
8 4
从现有的按列分布的数组中创建一个按行分布的新共存分布式数组:
spmd
X = redistribute(D, codistributor1d(1));
size(getLocalPart(X))
end每个工作单元的返回值:
2 16
恢复整个数组
您可以使用 gather 函数将共存分布式数组恢复为其未分布形式。gather 获取位于不同工作单元上的数组的各个段,并将它们组合成所有工作单元上的复制数组,或组合成一个工作单元上的单个数组。
沿第二个维度将一个 4×10 的数组发给四个工作单元:
spmd, A = [11:20; 21:30; 31:40; 41:50], end
A =
11 12 13 14 15 16 17 18 19 20
21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40
41 42 43 44 45 46 47 48 49 50
spmd, D = codistributed(A), end
WORKER 1 WORKER 2 WORKER 3 WORKER 4
11 12 13 | 14 15 16 | 17 18 | 19 20
21 22 23 | 24 25 26 | 27 28 | 29 30
31 32 33 | 34 35 36 | 37 38 | 39 40
41 42 43 | 44 45 46 | 47 48 | 49 50
| | |
spmd, size(getLocalPart(D)), end
Worker 1:
4 3
Worker 2:
4 3
Worker 3:
4 2
Worker 4:
4 2通过收集各段将未分布的段恢复为完整数组形式:
spmd, X = gather(D), end
X =
11 12 13 14 15 16 17 18 19 20
21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40
41 42 43 44 45 46 47 48 49 50
spmd, size(X), end
4 10索引到共存分布式数组
虽然对非分布式数组进行索引相当简单,但共存分布式数组需要额外的考虑。非分布式数组的每个维度的索引范围是 1 到最终下标,在 MATLAB 中由 end 关键字表示。可以使用 size 或 length 函数轻松确定任何维度的长度。
对于共存分布式数组,这些值不太容易获得。例如,数组的第二段(位于工作单元 2 的工作区中)具有取决于数组分布的起始索引。对于一个 200×1000 的数组,其默认按列分布在四个工作单元身上,工作单元 2 的起始索引是 251。对于同样按列分布的 1000×200 数组,相同索引为 51。至于结束索引,它不是通过使用 end 关键字给出的,因为在这种情况下 end 指的是整个数组的末尾;也就是最后一段的最后一个下标。使用 length 或 size 函数也无法给出每个段的长度,因为它们只返回整个数组的长度。
MATLAB colon 运算符和 end 关键字是索引非分布式数组的两个基本工具。对于共存分布式数组,MATLAB 提供了 colon 运算符的一个版本,称为 codistributed.colon。这实际上是一个函数,而不是像 colon 这样的符号运算符。
注意
当使用数组对共存分布式数组进行索引时,只能使用复制或共存分布式数组进行索引。工具箱不会检查以确保索引被复制,因为这需要全局通信。因此,使用不受支持的变体(例如 spmdIndex)来索引共存分布式数组可能会产生意外结果。
示例:在共存分布式数组中查找特定元素
假设您有一个包含 100 万个元素的行向量,分布在几个工作单元之间,并且您想要找到其元素编号 225,000。也就是说,您想知道哪个工作单元包含此元素,以及在该工作单元的向量本地部分的什么位置。globalIndices 函数提供了共存分布式数组的本地和全局索引之间的关联。
D = rand(1,1e6,"distributed"); %Distributed by columns
spmd
globalInd = globalIndices(D,2);
pos = find(globalInd == 225e3);
if ~isempty(pos)
fprintf(...
'Element is in position %d on worker %d.\n', pos, spmdIndex);
end
end如果您在有四个工作单元的池子里运行此代码,则会得到以下结果:
Worker 1: Element is in position 225000 on worker 1.
如果您在有 5 个工作单元的池子里运行此代码,则会得到以下结果:
Worker 2: Element is in position 25000 on worker 2.
请注意,如果您使用不同大小的池,元素最终会位于不同工作单元上的不同位置,但可以使用相同的代码来定位元素。
二维分布
作为按行或列的单一维度进行分布的替代方法,您可以使用 '2dbc' 或二维块循环分布按块分布矩阵。共存分布式数组的段不是由矩阵的多个完整行或列组成的,而是二维方块。
例如,考虑一个简单的 8×8 矩阵,其元素值按上升顺序排列。您可以在 spmd 语句或通信作业中创建此数组。
spmd
A = reshape(1:64, 8, 8)
end结果是复制的数组:
1 9 17 25 33 41 49 57
2 10 18 26 34 42 50 58
3 11 19 27 35 43 51 59
4 12 20 28 36 44 52 60
5 13 21 29 37 45 53 61
6 14 22 30 38 46 54 62
7 15 23 31 39 47 55 63
8 16 24 32 40 48 56 64假设您想要将此数组分配给四个工作单元,每个工作单元上使用一个 4×4 的块作为本地部分。在这种情况下,工作单元网格是 2×2 的工作单元排列,块大小是一边有 4 个元素的正方形(即,每个块都是 4×4 的正方形)。利用这些信息,您可以定义 codistributor 对象:
spmd
DIST = codistributor2dbc([2 2], 4);
end现在您可以使用这个 codistributor 对象来分发原始矩阵:
spmd
AA = codistributed(A, DIST)
end根据以下方案将数组分配给工作单元:
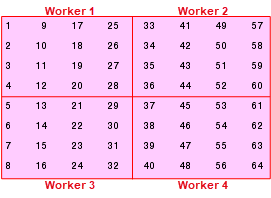
如果工作单元网格没有完美地覆盖共存分布式数组的维度,您仍然可以使用块循环的 '2dbc' 分布。在这种情况下,您可以想象工作单元网格在两个维度上被重复叠加,直到所有原始矩阵元素都包含在内。
使用相同的原始 8×8 矩阵和 2×2 工作单元网格,考虑将块大小设为 3 而不是 4,以便 3×3 方块分布在工作单元之间。代码如下:
spmd
DIST = codistributor2dbc([2 2], 3)
AA = codistributed(A, DIST)
end工作单元网格的第一“行”分配给工作单元 1 和工作单元 2,但仅包含原始矩阵八列中的六列。因此,接下来的两列分配给工作单元 1。这个进程持续到前几行的所有列都分布完毕。然后,当您沿着矩阵向下移动时,类似的过程将应用于行,如下面的分布方案所示:
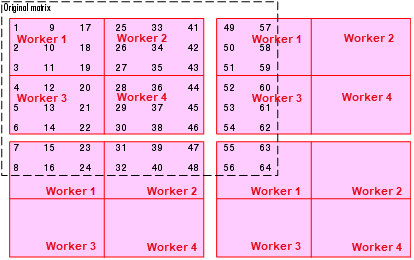
上图显示了需要四层工作单元网格覆盖才能容纳整个原始矩阵的方案。以下代码显示了最终数据分配给每个工作单元的结果。
spmd
getLocalPart(AA)
endWorker 1:
ans =
1 9 17 49 57
2 10 18 50 58
3 11 19 51 59
7 15 23 55 63
8 16 24 56 64
Worker 2:
ans =
25 33 41
26 34 42
27 35 43
31 39 47
32 40 48
Worker 3:
ans =
4 12 20 52 60
5 13 21 53 61
6 14 22 54 62
Worker 4:
ans =
28 36 44
29 37 45
30 38 46以下几点值得注意:
除非块大小至少为几十个,否则
'2dbc'分布可能不会提供任何性能增强。默认块大小为 64。工作单元网格应尽可能接近正方形。
并非所有增强以在
'1d'共存分布式数组上起作用的函数都能在'2dbc'共存分布式数组上起作用。