Tobit
Description
Create and analyze a Tobit model object to calculate
the exposure at default (EAD) using this workflow:
Use
fitEADModelto create aTobitmodel object.Use
predictto predict the EAD.Use
modelDiscriminationto return AUROC and ROC data. You can plot the results usingmodelDiscriminationPlot.Use
modelCalibrationto return the R-squared, RMSE, correlation, and sample mean error of predicted and observed EAD data. You can plot the results usingmodelCalibrationPlot.
Creation
Description
TobitEADModel = fitEADModel(___,Name=Value)eadModel =
fitEADModel(EADData,ModelType,PredictorVars={'UtilizationRate','Age','Marriage'},ConversionMeasure="ccf",DrawnVar='Drawn',LimitVar='Limit',ResponseVar='EAD')
creates an eadModel object using a
Tobit model type.
Input Arguments
Name-Value Arguments
Properties
Object Functions
predict | Predict exposure at default |
modelDiscrimination | Compute AUROC and ROC data |
modelDiscriminationPlot | Plot ROC curve |
modelCalibration | Compute R-square, RMSE, correlation, and sample mean error of predicted and observed EADs |
modelCalibrationPlot | Scatter plot of predicted and observed EADs |
Examples
This example shows how to use fitEADModel to create a Tobit model for exposure at default (EAD).
Load EAD Data
Load the EAD data.
load EADData.mat
head(EADData) UtilizationRate Age Marriage Limit Drawn EAD
_______________ ___ ___________ __________ __________ __________
0.24359 25 not married 44776 10907 44740
0.96946 44 not married 2.1405e+05 2.0751e+05 40678
0 40 married 1.6581e+05 0 1.6567e+05
0.53242 38 not married 1.7375e+05 92506 1593.5
0.2583 30 not married 26258 6782.5 54.175
0.17039 54 married 1.7357e+05 29575 576.69
0.18586 27 not married 19590 3641 998.49
0.85372 42 not married 2.0712e+05 1.7682e+05 1.6454e+05
rng('default'); NumObs = height(EADData); c = cvpartition(NumObs,'HoldOut',0.4); TrainingInd = training(c); TestInd = test(c);
Select Model Type
Select a model type for Tobit or Regression.
ModelType =  "Tobit";
"Tobit";Select Conversion Measure
Select a conversion measure for the EAD response values.
ConversionMeasure =  "LCF";
"LCF";Create Tobit EAD Model
Use fitEADModel to create a Tobit model using the EADData.
eadModel = fitEADModel(EADData,ModelType,PredictorVars={'UtilizationRate','Age','Marriage'}, ...
ConversionMeasure=ConversionMeasure,DrawnVar="Drawn",LimitVar="Limit",ResponseVar="EAD");
disp(eadModel); Tobit with properties:
CensoringSide: "both"
LeftLimit: 0
RightLimit: 1
ModelID: "Tobit"
Description: ""
UnderlyingModel: [1×1 risk.internal.credit.TobitModel]
PredictorVars: ["UtilizationRate" "Age" "Marriage"]
ResponseVar: "EAD"
LimitVar: "Limit"
DrawnVar: "Drawn"
ConversionMeasure: "lcf"
Display the underlying model. The underlying model's response variable is the transformation of the EAD response data. Use the 'LimitVar' and 'DrawnVar' name-value arguments to modify the transformation.
disp(eadModel.UnderlyingModel);
Tobit regression model:
EAD_lcf = max(0,min(Y*,1))
Y* ~ 1 + UtilizationRate + Age + Marriage
Estimated coefficients:
Estimate SE tStat pValue
__________ __________ ________ ________
(Intercept) 0.22735 0.026076 8.7186 0
UtilizationRate 0.47364 0.016501 28.703 0
Age -0.0013929 0.00063179 -2.2048 0.027522
Marriage_not married -0.0068879 0.012273 -0.56124 0.57466
(Sigma) 0.36419 0.0038855 93.731 0
Number of observations: 4378
Number of left-censored observations: 0
Number of uncensored observations: 4377
Number of right-censored observations: 1
Log-likelihood: -1791.06
Predict EAD
EAD prediction operates on the underlying compact statistical model and then transforms the predicted values back to the EAD scale. You can specify the predict function with different options for the 'ModelLevel' name-vale argument.
predictedEAD = predict(eadModel,EADData(TestInd,:),ModelLevel="ead"); predictedConversion = predict(eadModel,EADData(TestInd,:),ModelLevel="ConversionMeasure");
Validate EAD Model
For model validation, use modelDiscrimination, modelDiscriminationPlot, modelCalibration, and modelCalibrationPlot.
Use modelDiscrimination and then modelDiscriminationPlot to plot the ROC curve.
ModelLevel ="ConversionMeasure"; [DiscMeasure1,DiscData1] = modelDiscrimination(eadModel,EADData(TestInd,:),ModelLevel=ModelLevel); modelDiscriminationPlot(eadModel,EADData(TestInd, :),ModelLevel=ModelLevel,SegmentBy="Marriage");

Use modelCalibration and then modelCalibrationPlot to show a scatter plot of the predictions.
YData =  "Observed";
[CalMeasure1,CalData1] = modelCalibration(eadModel,EADData(TestInd,:),ModelLevel=ModelLevel);
modelCalibrationPlot(eadModel,EADData(TestInd,:),ModelLevel=ModelLevel,YData=YData);
"Observed";
[CalMeasure1,CalData1] = modelCalibration(eadModel,EADData(TestInd,:),ModelLevel=ModelLevel);
modelCalibrationPlot(eadModel,EADData(TestInd,:),ModelLevel=ModelLevel,YData=YData);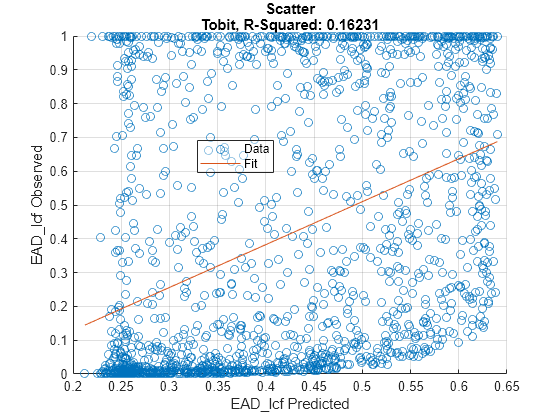
Plot a histogram of observed with respect to the predicted EAD.
figure; histogram(CalData1.Observed); hold on; histogram(CalData1.(('Predicted_' + ModelType))); legend('Observed','Predicted');

More About
References
[1] Baesens, Bart, Daniel Roesch, and Harald Scheule. Credit Risk Analytics: Measurement Techniques, Applications, and Examples in SAS. Wiley, 2016.
[2] Bellini, Tiziano. IFRS 9 and CECL Credit Risk Modelling and Validation: A Practical Guide with Examples Worked in R and SAS. San Diego, CA: Elsevier, 2019.
[3] Brown, Iain. Developing Credit Risk Models Using SAS Enterprise Miner and SAS/STAT: Theory and Applications. SAS Institute, 2014.
[4] Roesch, Daniel and Harald Scheule. Deep Credit Risk. Independently published, 2020.