OptimResults
Estimation results object for any supported algorithm except
nlinfit
Description
The OptimResults object contains estimation results from
fitting a SimBiology® model to data using the sbiofit function with any supported
algorithm except nlinfit. See the sbiofit function for a list of supported algorithms.
Creation
Use sbiofit with any supported estimation algorithm
except nlinfit to create an OptimResults object.
Properties
Object Functions
boxplot | Create box plot showing the variation of estimated SimBiology model parameters |
fitted | Return simulation results of SimBiology model fitted using least-squares regression |
plot | Compare simulation results to the training data, creating a time-course subplot for each group |
plotActualVersusPredicted | Compare predictions to actual data, creating a subplot for each response |
plotParameterStats | Show box plot, violin plot, and swarm scatter plots for parameter estimates |
plotResidualDistribution | Plot the distribution of the residuals |
plotResiduals | Plot residuals for each response, using time, group, or prediction as x-axis |
predict | Simulate and evaluate fitted SimBiology model |
random | Simulate SimBiology model, adding variations by sampling error model |
summary | Return parameter estimates and fit quality statistics from SimBiology least-squares estimation as structure array of tables |
Examples
Background
This example shows how to fit an individual's PK profile data to one-compartment model and estimate pharmacokinetic parameters.
Suppose you have drug plasma concentration data from an individual and want to estimate the volume of the central compartment and the clearance. Assume the drug concentration versus the time profile follows the monoexponential decline , where is the drug concentration at time t, is the initial concentration, and is the elimination rate constant that depends on the clearance and volume of the central compartment .
The synthetic data in this example was generated using the following model, parameters, and dose:
One-compartment model with bolus dosing and first-order elimination
Volume of the central compartment (
Central) = 1.70 literClearance parameter (
Cl_Central) = 0.55 liter/hourConstant error model
Bolus dose of 10 mg
Load Data and Visualize
The data is stored as a table with variables Time and Conc that represent the time course of the plasma concentration of an individual after an intravenous bolus administration measured at 13 different time points. The variable units for Time and Conc are hour and milligram/liter, respectively.
load("data15.mat") plot(data.Time,data.Conc,"b+") xlabel("Time (hour)"); ylabel("Drug Concentration (milligram/liter)");
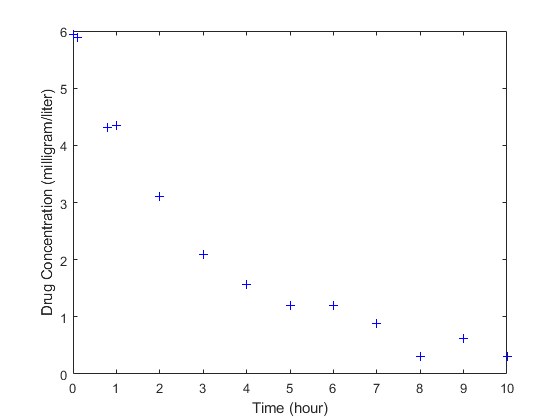
Convert to groupedData Format
Convert the data set to a groupedData object, which is the required data format for the fitting function sbiofit for later use. A groupedData object also lets you set independent variable and group variable names (if they exist). Set the units of the Time and Conc variables. The units are optional and only required for the UnitConversion feature, which automatically converts matching physical quantities to one consistent unit system.
gData = groupedData(data); gData.Properties.VariableUnits = ["hour","milligram/liter"]; gData.Properties
ans = struct with fields:
Description: ''
UserData: []
DimensionNames: {'Row' 'Variables'}
VariableNames: {'Time' 'Conc'}
VariableTypes: ["double" "double"]
VariableDescriptions: {}
VariableUnits: {'hour' 'milligram/liter'}
VariableContinuity: []
RowNames: {}
CustomProperties: [1×1 matlab.tabular.CustomProperties]
GroupVariableName: ''
IndependentVariableName: 'Time'
groupedData automatically set the name of the IndependentVariableName property to the Time variable of the data.
Construct a One-Compartment Model
Use the built-in PK library to construct a one-compartment model with bolus dosing and first-order elimination where the elimination rate depends on the clearance and volume of the central compartment. Use the configset object to turn on unit conversion.
pkmd = PKModelDesign; pkc1 = addCompartment(pkmd,"Central"); pkc1.DosingType = "Bolus"; pkc1.EliminationType = "linear-clearance"; pkc1.HasResponseVariable = true; model = construct(pkmd); configset = getconfigset(model); configset.CompileOptions.UnitConversion = true;
For details on creating compartmental PK models using the SimBiology® built-in library, see Create Pharmacokinetic Models.
Define Dosing
Define a single bolus dose of 10 milligram given at time = 0. For details on setting up different dosing schedules, see Doses in SimBiology Models.
dose = sbiodose("dose"); dose.TargetName = "Drug_Central"; dose.StartTime = 0; dose.Amount = 10; dose.AmountUnits = "milligram"; dose.TimeUnits = "hour";
Map Response Data to the Corresponding Model Component
The data contains drug concentration data stored in the Conc variable. This data corresponds to the Drug_Central species in the model. Therefore, map the data to Drug_Central as follows.
responseMap = "Drug_Central = Conc";Specify Parameters to Estimate
The parameters to fit in this model are the volume of the central compartment (Central) and the clearance rate (Cl_Central). In this case, specify log-transformation for these biological parameters since they are constrained to be positive. The estimatedInfo object lets you specify parameter transforms, initial values, and parameter bounds if needed.
paramsToEstimate = ["log(Central)","log(Cl_Central)"]; estimatedParams = estimatedInfo(paramsToEstimate,InitialValue=[1 1],Bounds=[1 5;0.5 2]);
Estimate Parameters
Now that you have defined one-compartment model, data to fit, mapped response data, parameters to estimate, and dosing, use sbiofit to estimate parameters. The default estimation function that sbiofit uses will change depending on which toolboxes are available. To see which function was used during fitting, check the EstimationFunction property of the corresponding results object.
fitConst = sbiofit(model,gData,responseMap,estimatedParams,dose);
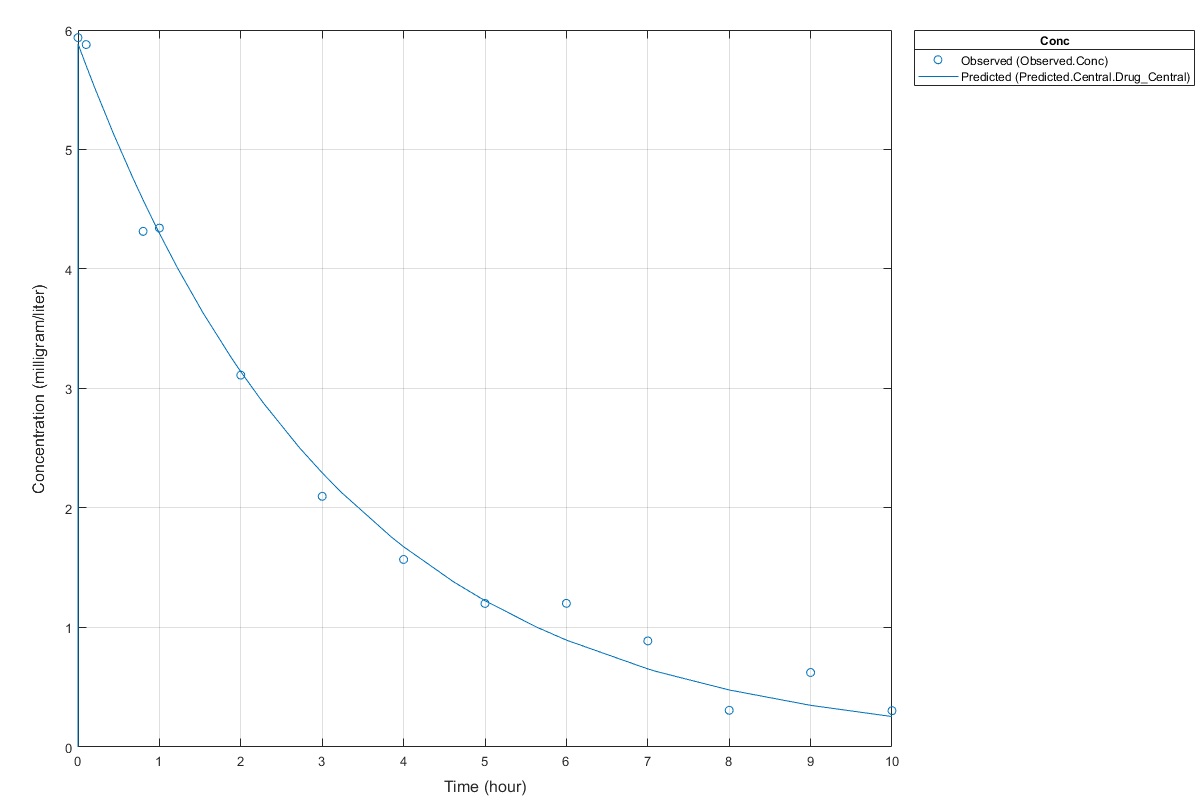
Display Estimated Parameters and Plot Results
Notice the parameter estimates were not far off from the true values (1.70 and 0.55) that were used to generate the data. You may also try different error models to see if they could further improve the parameter estimates.
fitConst.ParameterEstimates
ans=2×4 table
Name Estimate StandardError Bounds
______________ ________ _____________ __________
{'Central' } 1.6993 0.034821 1 5
{'Cl_Central'} 0.53358 0.01968 0.5 2
s.Labels.XLabel = "Time (hour)"; s.Labels.YLabel = "Concentration (milligram/liter)"; plot(fitConst,AxesStyle=s);
Use Different Error Models
Try three other supported error models (proportional, combination of constant and proportional error models, and exponential).
fitProp = sbiofit(model,gData,responseMap,estimatedParams,dose,... ErrorModel="proportional"); fitExp = sbiofit(model,gData,responseMap,estimatedParams,dose,... ErrorModel="exponential"); fitComb = sbiofit(model,gData,responseMap,estimatedParams,dose,... ErrorModel="combined");
Use Weights Instead of an Error Model
You can specify weights as a numeric matrix, where the number of columns corresponds to the number of responses. Setting all weights to 1 is equivalent to the constant error model.
weightsNumeric = ones(size(gData.Conc)); fitWeightsNumeric = sbiofit(model,gData,responseMap,estimatedParams,dose,Weights=weightsNumeric);
Alternatively, you can use a function handle that accepts a vector of predicted response values and returns a vector of weights. In this example, use a function handle that is equivalent to the proportional error model.
weightsFunction = @(y) 1./y.^2; fitWeightsFunction = sbiofit(model,gData,responseMap,estimatedParams,dose,Weights=weightsFunction);
Display Estimated Parameter Values
Show the estimated parameter values of each model.
allResults = [fitConst,fitWeightsNumeric,fitWeightsFunction,fitProp,fitExp,fitComb]; Estimated_Central = zeros(6,1); Estimated_Cl_Central = zeros(6,1); t2 = table(Estimated_Central,Estimated_Cl_Central); errorModelNames = ["constant error model","equal weights","proportional weights", ... "proportional error model","exponential error model",... "combined error model"]; t2.Properties.RowNames = errorModelNames; for i = 1:height(t2) t2{i,1} = allResults(i).ParameterEstimates.Estimate(1); t2{i,2} = allResults(i).ParameterEstimates.Estimate(2); end t2
t2=6×2 table
Estimated_Central Estimated_Cl_Central
_________________ ____________________
constant error model 1.6993 0.53358
equal weights 1.6993 0.53358
proportional weights 1.9045 0.51734
proportional error model 1.8777 0.51147
exponential error model 1.7872 0.51701
combined error model 1.7008 0.53271
Conclusion
This example showed how to estimate PK parameters, namely the volume of the central compartment and clearance parameter of an individual, by fitting the PK profile data to one-compartment model. It showed how to use different error models and numeric weights instead of an error model.
Version History
Introduced in R2014a
See Also
LeastSquaresResults object | NLINResults object | sbiofit | sbiofitmixed