silhouette
Silhouette plot
Syntax
Description
silhouette(
accepts one or more additional distance metric parameter values when you specify
X,clust,Distance,DistParameter)Distance as a custom distance function handle
@ that accepts the additional
parameter values.distfun
Examples
Create silhouette plots from clustered data using different distance metrics.
Generate random sample data.
rng('default') % For reproducibility X = [randn(10,2)+3;randn(10,2)-3];
Create a scatter plot of the data.
scatter(X(:,1),X(:,2));
title('Randomly Generated Data');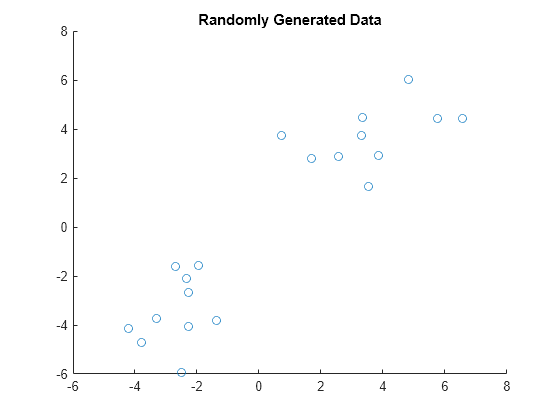
The scatter plot shows that the data appears to be split into two clusters of equal size.
Partition the data into two clusters using kmeans with the default squared Euclidean distance metric.
clust = kmeans(X,2);
clust contains the cluster indices of the data.
Create a silhouette plot from the clustered data using the default squared Euclidean distance metric.
silhouette(X,clust)

The silhouette plot shows that the data is split into two clusters of equal size. All the points in the two clusters have large silhouette values (0.8 or greater), indicating that the clusters are well separated.
Create a silhouette plot from the clustered data using the Euclidean distance metric.
silhouette(X,clust,'Euclidean')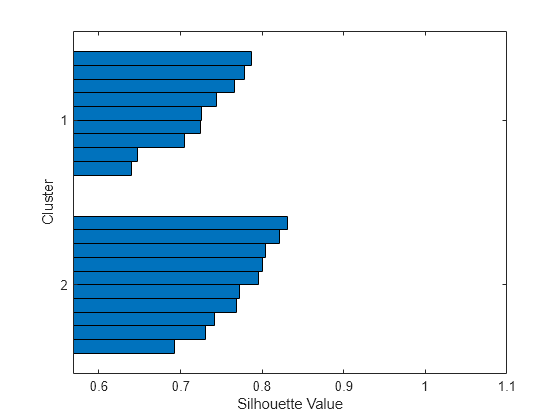
The silhouette plot shows that the data is split into two clusters of equal size. All the points in the two clusters have large silhouette values (0.6 or greater), indicating that the clusters are well separated.
Compute the silhouette values from clustered data.
Generate random sample data.
rng('default') % For reproducibility X = [randn(10,2)+1;randn(10,2)-1];
Cluster the data in X based on the sum of absolute differences in distance by using kmeans.
clust = kmeans(X,2,'distance','cityblock');
clust contains the cluster indices of the data.
Compute the silhouette values from the clustered data. Specify the distance metric as 'cityblock' to indicate that the kmeans clustering is based on the sum of absolute differences.
s = silhouette(X,clust,'cityblock')s = 20×1
0.0816
0.5848
0.1906
0.2781
0.3954
0.4050
0.0897
0.5416
0.6203
0.6664
0.5814
0.6022
0.6540
0.5223
0.5566
⋮
Find silhouette values from clustered data using a custom chi-square distance metric. Verify that the chi-square distance metric is equivalent to the Euclidean distance metric, but with an optional scaling parameter.
Generate random sample data.
rng('default'); % For reproducibility X = [randn(10,2)+3;randn(10,2)-3];
Cluster the data in X using kmeans with the default squared Euclidean distance metric.
clust = kmeans(X,2);
Find silhouette values and create a silhouette plot from the clustered data using the Euclidean distance metric.
[s,h] = silhouette(X,clust,'Euclidean')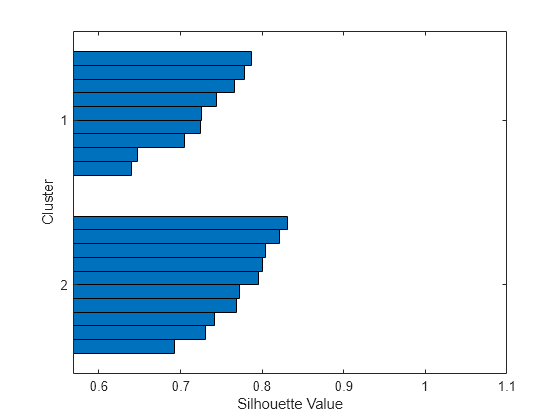
s = 20×1
0.6472
0.7241
0.5682
0.7658
0.7864
0.6397
0.7253
0.7783
0.7054
0.7442
0.7719
0.7957
0.8213
0.7680
0.7418
⋮
h =
Figure (1) with properties:
Number: 1
Name: ''
Color: [1 1 1]
Position: [161 234 560 337.1114]
Units: 'pixels'
Show all properties
The chi-square distance between J-dimensional points x and z is
where is the weight associated with dimension j.
Set weights for each dimension and specify the chi-square distance function. The distance function must:
Take as input arguments the n-by-p input data matrix
X, one row ofX(for example,x), and a scaling (or weight) parameterw.Calculate the distance from
xto each row ofX.Return a vector of length n. Each element of the vector is the distance between the observation corresponding to
xand the observations corresponding to each row ofX.
w = [0.4; 0.6]; % Set arbitrary weights for illustration
chiSqrDist = @(x,Z,w)sqrt(((x-Z).^2)*w);Find silhouette values from the clustered data using the custom distance metric chiSqrDist.
s1 = silhouette(X,clust,chiSqrDist,w)
s1 = 20×1
0.6288
0.7239
0.6244
0.7696
0.7957
0.6688
0.7386
0.7865
0.7223
0.7572
0.7579
0.7996
0.8207
0.7786
0.7334
⋮
Set the weight for both dimensions to 1 to use chiSqrDist as the Euclidean distance metric. Find silhouette values and verify that they are the same as the values in s.
w2 = [1; 1]; s2 = silhouette(X,clust,chiSqrDist,w2); AreValuesEqual = isequal(s2,s)
AreValuesEqual = logical
1
The silhouette values are the same in s and s2.
Input Arguments
Output Arguments
More About
References
[1] Kaufman L., and P. J. Rousseeuw. Finding Groups in Data: An Introduction to Cluster Analysis. Hoboken, NJ: John Wiley & Sons, Inc., 1990.
Version History
Introduced before R2006a