kmeans
k 均值聚类
语法
说明
idx = kmeans(X,k)X 的观测值划分为 k 个聚类,并返回包含每个观测值的簇索引的 n×1 向量 (idx)。X 的行对应于点,列对应于变量。
默认情况下,kmeans 使用平方欧几里德距离度量,并用 k-means++ 算法进行簇中心初始化。
idx = kmeans(X,k,Name,Value)Name,Value 对组参量所指定的附加选项返回簇索引。
例如,指定余弦距离、使用新初始值重复聚类的次数或使用并行计算的次数。
示例
对数据进行 k 均值聚类,然后绘制簇区域。
加载 Fisher 鸢尾花数据集。使用花瓣长度和宽度作为预测变量。
load fisheriris X = meas(:,3:4); figure; plot(X(:,1),X(:,2),'k*','MarkerSize',5); title 'Fisher''s Iris Data'; xlabel 'Petal Lengths (cm)'; ylabel 'Petal Widths (cm)';
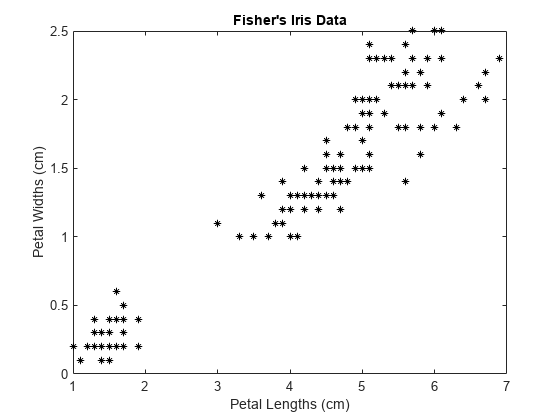
较大的簇似乎被分成两个区域:一个较低方差区域,一个较高方差区域。这可能表明较大的簇是两个重叠的簇。
对数据进行聚类。指定 k = 3 个簇。
rng(1); % For reproducibility
[idx,C] = kmeans(X,3);idx 是与 X 中的观测值对应的预测簇索引的向量。C 是包含最终质心位置的 3×2 矩阵。
使用 kmeans 计算从每个质心到网格上各点的距离。为此,将质心 (C) 和网格上的点传递给 kmeans,并实现算法的一次迭代。
x1 = min(X(:,1)):0.01:max(X(:,1)); x2 = min(X(:,2)):0.01:max(X(:,2)); [x1G,x2G] = meshgrid(x1,x2); XGrid = [x1G(:),x2G(:)]; % Defines a fine grid on the plot idx2Region = kmeans(XGrid,3,'MaxIter',1,'Start',C);
Warning: Failed to converge in 1 iterations.
% Assigns each node in the grid to the closest centroidkmeans 显示一条警告,指出算法未收敛,这是您应预料到的,因为软件只实现了一次迭代。
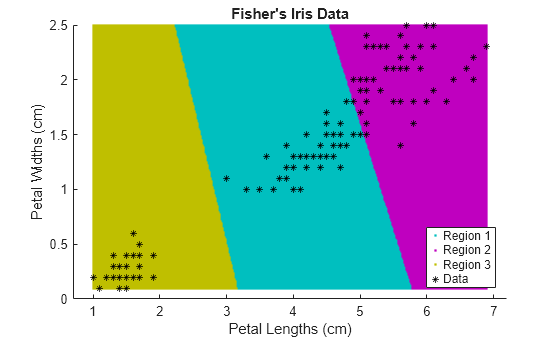
绘制簇区域。
figure; gscatter(XGrid(:,1),XGrid(:,2),idx2Region,... [0,0.75,0.75;0.75,0,0.75;0.75,0.75,0],'..'); hold on; plot(X(:,1),X(:,2),'k*','MarkerSize',5); title 'Fisher''s Iris Data'; xlabel 'Petal Lengths (cm)'; ylabel 'Petal Widths (cm)'; legend('Region 1','Region 2','Region 3','Data','Location','SouthEast'); hold off;
随机生成样本数据。
rng default; % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2)]; figure; plot(X(:,1),X(:,2),'.'); title 'Randomly Generated Data';
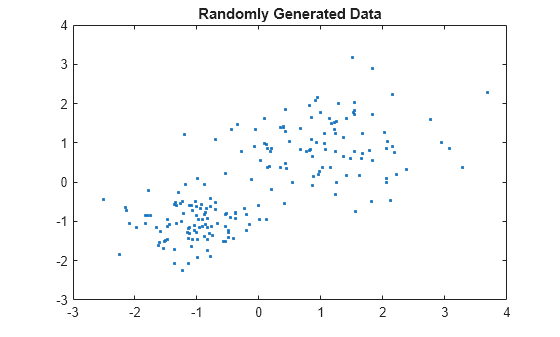
数据中似乎有两个簇。
将数据分成两个簇,并从五个初始化中选择最佳排列。显示最终输出。
opts = statset('Display','final'); [idx,C] = kmeans(X,2,'Distance','cityblock',... 'Replicates',5,'Options',opts);
Replicate 1, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 2, 5 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 3, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 4, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 5, 2 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Best total sum of distances = 201.533
默认情况下,软件使用 k-means++ 分别对每次重复进行初始化。
绘制簇和簇质心。
figure; plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12) hold on plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12) plot(C(:,1),C(:,2),'kx',... 'MarkerSize',15,'LineWidth',3) legend('Cluster 1','Cluster 2','Centroids',... 'Location','NW') title 'Cluster Assignments and Centroids' hold off
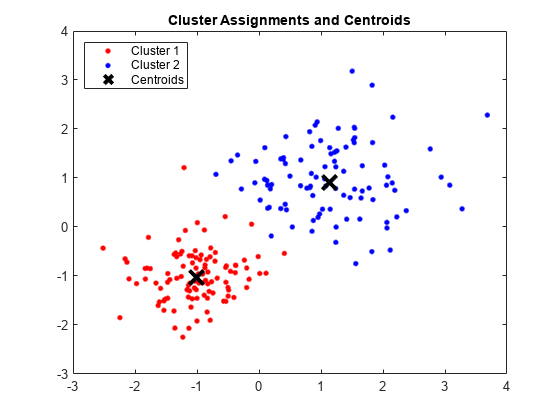
通过将 idx 传递给 silhouette,您可以确定簇之间的分离程度。
对大型数据集进行聚类可能需要大量时间,尤其是在您使用在线更新(默认设置)时。如果您拥有 Parallel Computing Toolbox™ 许可证并设置了并行计算的选项,则 kmeans 将并行运行每个聚类任务(或副本)。而且,如果 Replicates > 1,则并行计算会减少收敛时间。
从高斯混合模型中随机生成一个大型数据集。
rng(1); % For reproducibility Mu = ones(20,30).*(1:20)'; % Gaussian mixture mean rn30 = randn(30,30); Sigma = rn30'*rn30; % Symmetric and positive-definite covariance Mdl = gmdistribution(Mu,Sigma); % Define the Gaussian mixture distribution X = random(Mdl,10000);
Mdl 是一个 30 维 gmdistribution 模型,包含 20 个分量。X 是一个 10000×30 矩阵,其数据出自 Mdl 模型。
指定并行计算的选项。
stream = RandStream('mlfg6331_64'); % Random number stream options = statset('UseParallel',1,'UseSubstreams',1,... 'Streams',stream);
RandStream 的输入参量 'mlfg6331_64' 指定使用乘法滞后斐波那契生成器算法。options 是一个结构体数组,其字段指定控制估算的选项。
对数据进行 k 均值聚类。指定数据中有 k = 20 个簇,并增加迭代次数。通常,目标函数包含局部最小值。指定 10 个副本以帮助找到更低的局部最小值。
tic; % Start stopwatch timer [idx,C,sumd,D] = kmeans(X,20,'Options',options,'MaxIter',10000,... 'Display','final','Replicates',10);
Starting parallel pool (parpool) using the 'Processes' profile ... 08-Nov-2024 15:52:23: Job Queued. Waiting for parallel pool job with ID 2 to start ... Connected to parallel pool with 4 workers. Replicate 2, 56 iterations, total sum of distances = 7.62036e+06. Replicate 4, 79 iterations, total sum of distances = 7.62412e+06. Replicate 3, 76 iterations, total sum of distances = 7.62583e+06. Replicate 1, 94 iterations, total sum of distances = 7.60746e+06. Replicate 5, 103 iterations, total sum of distances = 7.61753e+06. Replicate 7, 77 iterations, total sum of distances = 7.61939e+06. Replicate 6, 96 iterations, total sum of distances = 7.6258e+06. Replicate 8, 113 iterations, total sum of distances = 7.60741e+06. Replicate 10, 66 iterations, total sum of distances = 7.62582e+06. Replicate 9, 80 iterations, total sum of distances = 7.60592e+06. Best total sum of distances = 7.60592e+06
toc % Terminate stopwatch timerElapsed time is 86.846475 seconds.
命令行窗口指示有六个工作单元可用。您的系统中的工作单元数量可能会有所不同。命令行窗口显示迭代次数和每个副本的最终目标函数值。输出参量包含副本 9 的结果,因为它的总距离最低。
kmeans 执行 k 均值聚类以将数据划分为 k 个簇。当您有要进行聚类的新数据集时,可以使用 kmeans 创建包含现有数据和新数据的新簇。kmeans 函数支持 C/C++ 代码生成,因此您可以生成接受训练数据并返回聚类结果的代码,然后将代码部署到设备上。在此工作流中,您必须传递训练数据,训练数据有可能相当大。为了节省设备上的内存,您可以分别使用 kmeans 和 pdist2 来分离训练和预测。
使用 kmeans 在 MATLAB® 中创建簇,并在生成的代码中使用 pdist2 将新数据分配给现有簇。对于代码生成,定义接受簇质心位置和新数据集的入口函数,并返回最近邻簇的索引。然后,为入口函数生成代码。
生成 C/C++ 代码需要 MATLAB® Coder™。
执行 k 均值聚类
使用三种分布生成训练数据集。
rng('default') % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2); randn(100,2)*0.75];
使用 kmeans 将训练数据分成三个簇。
[idx,C] = kmeans(X,3);
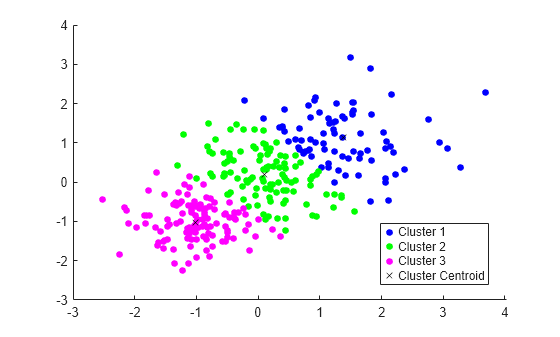
绘制簇和簇质心。
figure gscatter(X(:,1),X(:,2),idx,'bgm') hold on plot(C(:,1),C(:,2),'kx') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')
将新数据分配给现有簇
生成测试数据集。
Xtest = [randn(10,2)*0.75+ones(10,2);
randn(10,2)*0.5-ones(10,2);
randn(10,2)*0.75];使用现有簇对测试数据集进行分类。使用 pdist2 找到距离每个测试数据点最近的质心。
[~,idx_test] = pdist2(C,Xtest,'euclidean','Smallest',1);
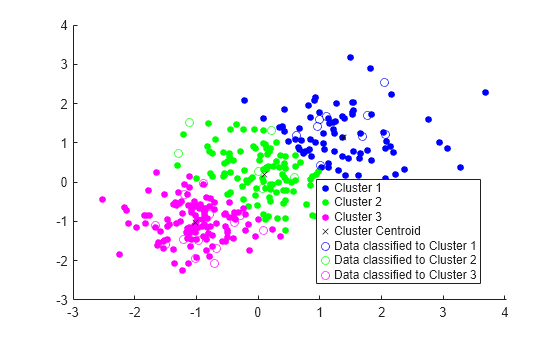
使用 idx_test 和 gscatter 绘制测试数据并对测试数据加标签。
gscatter(Xtest(:,1),Xtest(:,2),idx_test,'bgm','ooo') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid', ... 'Data classified to Cluster 1','Data classified to Cluster 2', ... 'Data classified to Cluster 3')
生成代码
生成将新数据分配给现有簇的 C 代码。请注意,生成 C/C++ 代码需要 MATLAB® Coder™。
定义名为 findNearestCentroid 的入口函数,该函数接受质心位置和新数据,然后使用 pdist2 找到最近的簇。
在入口函数的函数签名后面添加 %#codegen 编译器指令(即 pragma),以指示您要为此 MATLAB 算法生成代码。添加此指令指示 MATLAB 代码分析器帮助您诊断和修复在代码生成过程中可能导致错误的违规。
type findNearestCentroid % Display contents of findNearestCentroid.m
function idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'euclidean','Smallest',1); % Find the nearest centroid
注意:如果您点击位于此页右上角的按钮,并在 MATLAB® 中打开此示例,则 MATLAB® 将打开示例文件夹。该文件夹包括入口函数文件。
使用 codegen (MATLAB Coder) 生成代码。由于 C 和 C++ 是静态类型语言,因此必须在编译时确定入口函数中所有变量的属性。要指定 findNearestCentroid 的输入的数据类型和数组大小,请使用 -args 选项传递表示具有特定数据类型和数组大小的值集的 MATLAB 表达式。有关详细信息,请参阅 Specify Variable-Size Arguments for Code Generation of Machine Learning Models。
codegen findNearestCentroid -args {C,Xtest}
Code generation successful.
codegen 生成 MEX 函数 findNearestCentroid_mex,扩展名因平台而异。
验证生成的代码。
myIndx = findNearestCentroid(C,Xtest); myIndex_mex = findNearestCentroid_mex(C,Xtest); verifyMEX = isequal(idx_test,myIndx,myIndex_mex)
verifyMEX = logical
1
isequal 返回逻辑值 1 (true),这意味着所有输入都相等。这一比较结果确认 pdist2 函数、findNearestCentroid 函数和 MEX 函数均返回相同的索引。
您还可以使用 GPU Coder™ 生成优化的 CUDA® 代码。
cfg = coder.gpuConfig('mex'); codegen -config cfg findNearestCentroid -args {C,Xtest}
有关代码生成的详细信息,请参阅。有关 GPU Coder 的详细信息,请参阅Get Started with GPU Coder (GPU Coder) 和Supported Functions (GPU Coder)。
kmeans 函数忽略包含缺失值的表行。要对输入数据中的所有行进行 k 均值聚类,您可以使用回归模型估算缺失值。
加载 carbig 数据集并创建一个包含 Weight、Displacement 和 Horsepower 预测变量的表。
load carbig
X = table(Weight,Displacement,Horsepower);显示 X 的每列中的缺失值数目。
MissingValues = sum(ismissing(X))
MissingValues = 1×3
0 0 6
第 3 列 (Horsepower) 有六个缺失值。其他列不包含任何缺失值。
使用不包含缺失值的行训练一个多元回归模型。将 Horsepower 指定为响应变量。
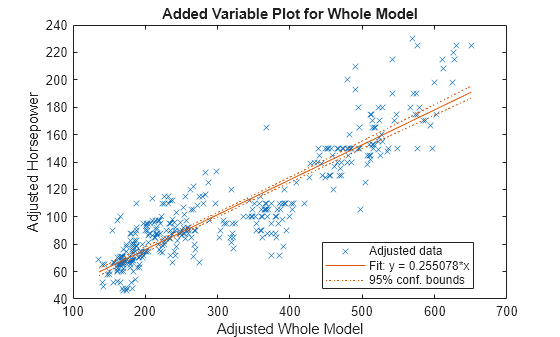
HPmodel = fitlm(rmmissing(X),"Horsepower");显示回归模型的绘图。
plot(HPmodel)
使用线性回归模型估算 X 中缺失的 Horsepower 值。
imputedHP = predict(HPmodel,X(any(ismissing(X),2),1:2))
imputedHP = 6×1
70.6749
105.0360
65.2328
90.0460
73.9490
94.1612
用估算的值替换缺失的 Horsepower 值。
X(any(ismissing(X),2),3) = table(imputedHP);
对数据进行 k 均值聚类。指定数据有三个簇。
[idx,C] = kmeans(table2array(X),3);
绘制数据和簇分配。
scatter3(X.Weight,X.Displacement,X.Horsepower,15,idx,"filled")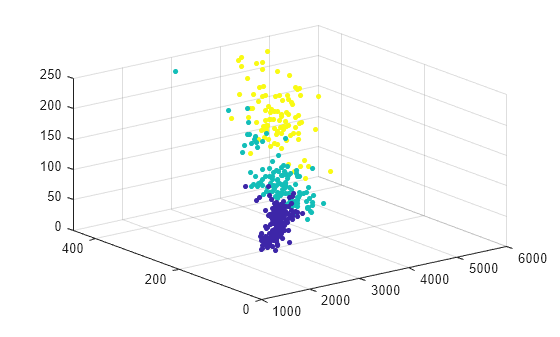
输入参数
名称-值参数
输出参量
详细信息
算法
kmeans使用两阶段迭代算法来最小化点到质心的距离总和,该距离总和覆盖所有k个簇。第一阶段使用批量更新,其中每次迭代都包括一次性将点重新分配给其最近邻的簇质心,然后重新计算簇质心。此阶段有时候不会收敛至局部最小值解。也就是说,将任一点移至不同簇都会增加总距离的数据分区。尤其是对小数据集来说,更容易出现这种情况。批量更新阶段速度很快,但在该阶段逼近的解可能只能作为第二阶段的起点。
第二阶段使用在线更新,即只要单独重新分配点可减少距离的总和,则进行重新分配,并在每次重新分配后重新计算簇质心。此阶段中的每次迭代都对所有点进行一次遍历。此阶段会收敛至一个局部最小值,尽管可能存在总距离更低的其他局部最小值。一般情况下,需要穷尽选择起始点才能求解全局最小值,但是,使用具有随机起始点的几个副本通常也会得到全局最小值解。
如果
Replicates= r > 1 且Start是plus(默认值),则软件根据 k-means++ 算法选择 r 个可能不同的种子集。如果您在
Options中启用UseParallel选项且Replicates> 1,则每个工作单元会以并行方式选择种子和进行聚类。
参考
[1] Arthur, David, and Sergi Vassilvitskii. K-means++: The Advantages of Careful Seeding. In SODA ‘07: Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 1027–1035. Society for Industrial and Applied Mathematics, 2007.
[2] Lloyd, S. Least Squares Quantization in PCM. IEEE Transactions on Information Theory 28, no. 2 (March 1982): 129–37.
[3] Seber, G. A. F. Multivariate Observations. Hoboken, NJ: John Wiley & Sons, Inc., 1984.
[4] Spath, H. Cluster Dissection and Analysis: Theory, FORTRAN Programs, Examples. Translated by J. Goldschmidt. New York: Halsted Press, 1985.
扩展功能
版本历史记录
在 R2006a 之前推出
另请参阅
linkage | clusterdata | incrementalKMeans | silhouette | parpool (Parallel Computing Toolbox) | statset | gmdistribution | kmedoids