pdist2
两组观测值之间的两两距离
语法
说明
D = pdist2(X,Y,Distance,DistParameter)Distance 和 DistParameter 指定的度量返回该距离。仅当 Distance 是 'seuclidean'、'minkowski' 或 'mahalanobis' 时,您才能指定 DistParameter。
对于任何以前的参量,D = pdist2(___,Name,Value)
D = pdist2(X,Y,Distance,'Smallest',K)使用Distance指定的度量计算距离,并以升序返回X中观测值与Y中每个观测值的前K个最小两两距离。D = pdist2(X,Y,Distance,DistParameter,'Largest',K)使用Distance和DistParameter指定的度量计算距离,并以降序返回K个最大的两两距离。
示例
创建包含三个观测值和两个变量的两个矩阵。
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
计算欧几里德距离。输入参量 Distance 的默认值为 'euclidean'。在不使用名称-值对组参量的情况下计算欧几里德距离时,不需要指定 Distance。
D = pdist2(X,Y)
D = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
D(i,j) 对应于 X 中的观测值 i 与 Y 中的观测值 j 之间的两两距离。
创建包含三个观测值和两个变量的两个矩阵。
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
使用默认指数 2 计算闵可夫斯基距离。
D1 = pdist2(X,Y,'minkowski')D1 = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
用指数 1 计算闵可夫斯基距离,它等于城市街区距离。
D2 = pdist2(X,Y,'minkowski',1)D2 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
D3 = pdist2(X,Y,'cityblock')D3 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
创建两个包含五个观测值和两个变量的矩阵。
rng(0,"twister") % For reproducibility X = rand(5,2); Y = rand(5,2);
使用 pdist2 函数计算马氏距离。
D = pdist2(X,Y,"mahalanobis")D = 5×5
2.0012 0.9926 2.1767 1.9656 2.2036
2.3429 0.4318 1.6528 1.7564 1.7453
1.0330 2.5697 2.7833 1.3093 2.3936
3.2463 1.3676 0.1638 1.4094 0.3452
2.6608 1.6585 0.9895 0.6572 0.5121
计算 X 的均值与观测值 Y 之间的马氏距离。使用 X 的协方差作为距离度量参数。
D2 = pdist2(mean(X),Y,"mahalanobis",cov(X))D2 = 1×5
2.0090 0.9377 1.2824 0.7850 1.0966
使用 mahal 函数计算平方马氏距离。
SqMahalDist = mahal(Y,X)'
SqMahalDist = 1×5
4.0360 0.8792 1.6445 0.6162 1.2025
计算每个值的平方根。
MahalDist = SqMahalDist.^0.5
MahalDist = 1×5
2.0090 0.9377 1.2824 0.7850 1.0966
马氏距离值与 pdist2 函数返回的值相同。
创建包含三个观测值和两个变量的两个矩阵。
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
为 Y 中的每个观测值求出 X 中观测值的两个最小的两两欧几里德距离。
[D,I] = pdist2(X,Y,'euclidean','Smallest',2)
D = 2×3
0.5387 0.4242 0.1538
0.7100 0.5951 0.3422
I = 2×3
1 3 1
2 2 2
对于 Y 中的每个观测值,pdist2 通过计算距离值并将其与 X 中的所有观测值进行比较,求出两个最小的距离。然后,该函数按升序对 D 的每列中的距离进行排序。I 包含与 D 中的距离对应的 X 中的观测值的索引。
创建两个由点组成的大型矩阵,然后测量 pdist2 采用默认的 "euclidean" 距离度量时所用的时间。
rng default % For reproducibility N = 10000; X = randn(N,1000); Y = randn(N,1000); D = pdist2(X,Y); % Warm up function for more reliable timing information tic D = pdist2(X,Y); standard = toc
standard = 12.2637
接下来,使用 "fasteuclidean" 距离度量来测量 pdist2 所用的时间。指定缓存大小为 100。
D = pdist2(X,Y,"fasteuclidean",CacheSize=100); % Warm up function tic D2 = pdist2(X,Y,"fasteuclidean",CacheSize=100); accelerated = toc
accelerated = 2.2260
计算加速后的计算比标准计算快多少倍。
standard/accelerated
ans = 5.5094
在此示例中,加速版本的速度提高了一倍多。
定义一个忽略 NaN 值坐标的自定义距离函数,并使用该自定义距离函数计算两两距离。
创建包含三个观测值和三个变量的两个矩阵。
rng('default') % For reproducibility X = rand(3,3) Y = [X(:,1:2) rand(3,1)]
X =
0.8147 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
Y =
0.8147 0.9134 0.9649
0.9058 0.6324 0.1576
0.1270 0.0975 0.9706
X 和 Y 的前两列是相同的。假设缺少 X(1,1)。
X(1,1) = NaN
X =
NaN 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
计算汉明距离。
D1 = pdist2(X,Y,'hamming')
D1 =
NaN NaN NaN
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
如果 X 中的观测值 i 或 Y 中的观测值 j 包含 NaN 值,则对于 i 和 j 之间的两两距离,函数 pdist2 返回 NaN。因此,D1(1,1)、D1(1,2) 和 D1(1,3) 为 NaN 值。
定义一个自定义距离函数 nanhamdist,该函数忽略 NaN 值的坐标并计算汉明距离。当处理大量观测值时,您可以通过遍历数据的坐标来更快地计算距离。
function D2 = nanhamdist(XI,XJ) %NANHAMDIST Hamming distance ignoring coordinates with NaNs [m,p] = size(XJ); nesum = zeros(m,1); pstar = zeros(m,1); for q = 1:p notnan = ~(isnan(XI(q)) | isnan(XJ(:,q))); nesum = nesum + ((XI(q) ~= XJ(:,q)) & notnan); pstar = pstar + notnan; end D2 = nesum./pstar;
将函数句柄作为输入参量传递给 pdist2,以使用 nanhamdist 计算该距离。
D2 = pdist2(X,Y,@nanhamdist)
D2 =
0.5000 1.0000 1.0000
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
kmeans 执行 k 均值聚类以将数据划分为 k 个簇。当您有要进行聚类的新数据集时,可以使用 kmeans 创建包含现有数据和新数据的新簇。kmeans 函数支持 C/C++ 代码生成,因此您可以生成接受训练数据并返回聚类结果的代码,然后将代码部署到设备上。在此工作流中,您必须传递训练数据,训练数据有可能相当大。为了节省设备上的内存,您可以分别使用 kmeans 和 pdist2 来分离训练和预测。
使用 kmeans 在 MATLAB® 中创建簇,并在生成的代码中使用 pdist2 将新数据分配给现有簇。对于代码生成,定义接受簇质心位置和新数据集的入口函数,并返回最近邻簇的索引。然后,为入口函数生成代码。
生成 C/C++ 代码需要 MATLAB® Coder™。
执行 k 均值聚类
使用三种分布生成训练数据集。
rng('default') % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2); randn(100,2)*0.75];
使用 kmeans 将训练数据分成三个簇。
[idx,C] = kmeans(X,3);
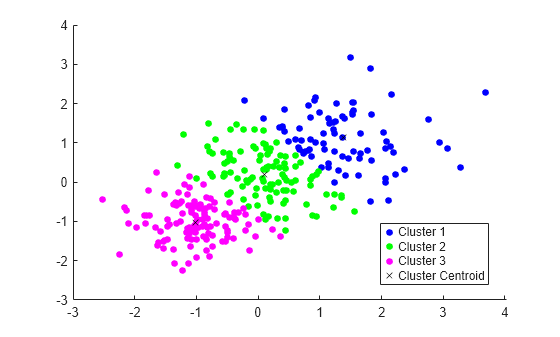
绘制簇和簇质心。
figure gscatter(X(:,1),X(:,2),idx,'bgm') hold on plot(C(:,1),C(:,2),'kx') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')
将新数据分配给现有簇
生成测试数据集。
Xtest = [randn(10,2)*0.75+ones(10,2);
randn(10,2)*0.5-ones(10,2);
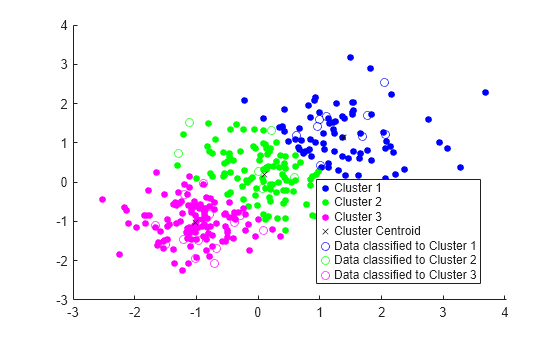
randn(10,2)*0.75];使用现有簇对测试数据集进行分类。使用 pdist2 找到距离每个测试数据点最近的质心。
[~,idx_test] = pdist2(C,Xtest,'euclidean','Smallest',1);
使用 idx_test 和 gscatter 绘制测试数据并对测试数据加标签。
gscatter(Xtest(:,1),Xtest(:,2),idx_test,'bgm','ooo') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid', ... 'Data classified to Cluster 1','Data classified to Cluster 2', ... 'Data classified to Cluster 3')
生成代码
生成将新数据分配给现有簇的 C 代码。请注意,生成 C/C++ 代码需要 MATLAB® Coder™。
定义名为 findNearestCentroid 的入口函数,该函数接受质心位置和新数据,然后使用 pdist2 找到最近的簇。
在入口函数的函数签名后面添加 %#codegen 编译器指令(即 pragma),以指示您要为此 MATLAB 算法生成代码。添加此指令指示 MATLAB 代码分析器帮助您诊断和修复在代码生成过程中可能导致错误的违规。
type findNearestCentroid % Display contents of findNearestCentroid.m
function idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'euclidean','Smallest',1); % Find the nearest centroid
注意:如果您点击位于此页右上角的按钮,并在 MATLAB® 中打开此示例,则 MATLAB® 将打开示例文件夹。该文件夹包括入口函数文件。
使用 codegen (MATLAB Coder) 生成代码。由于 C 和 C++ 是静态类型语言,因此必须在编译时确定入口函数中所有变量的属性。要指定 findNearestCentroid 的输入的数据类型和数组大小,请使用 -args 选项传递表示具有特定数据类型和数组大小的值集的 MATLAB 表达式。有关详细信息,请参阅 Specify Variable-Size Arguments for Code Generation of Machine Learning Models。
codegen findNearestCentroid -args {C,Xtest}
Code generation successful.
codegen 生成 MEX 函数 findNearestCentroid_mex,扩展名因平台而异。
验证生成的代码。
myIndx = findNearestCentroid(C,Xtest); myIndex_mex = findNearestCentroid_mex(C,Xtest); verifyMEX = isequal(idx_test,myIndx,myIndex_mex)
verifyMEX = logical
1
isequal 返回逻辑值 1 (true),这意味着所有输入都相等。这一比较结果确认 pdist2 函数、findNearestCentroid 函数和 MEX 函数均返回相同的索引。
您还可以使用 GPU Coder™ 生成优化的 CUDA® 代码。
cfg = coder.gpuConfig('mex'); codegen -config cfg findNearestCentroid -args {C,Xtest}
有关代码生成的详细信息,请参阅。有关 GPU Coder 的详细信息,请参阅Get Started with GPU Coder (GPU Coder) 和Supported Functions (GPU Coder)。
输入参数
名称-值参数
输出参量
详细信息
算法
扩展功能
版本历史记录
在 R2010a 中推出另请参阅
pdist | createns | knnsearch | ExhaustiveSearcher | KDTreeSearcher