knnsearch
使用输入数据查找 k 最近邻点
说明
示例
根据年龄和体重,在 hospital 数据集中找到与 Y 中的患者最相似的患者。
加载 hospital 数据集。
load hospital; X = [hospital.Age hospital.Weight]; Y = [20 162; 30 169; 40 168; 50 170; 60 171]; % New patients
在 X 和 Y 之间执行 knnsearch 以找到最近邻点的索引。
Idx = knnsearch(X,Y);
在 X 中找到与 Y 中患者的年龄和体重最接近的患者。
X(Idx,:)
ans = 5×2
25 171
25 171
39 164
49 170
50 172
在 X 中找到与 Y 中每个点最接近的 10 个最近邻点,首先使用闵可夫斯基距离度量,然后使用切比雪夫距离度量。
加载费舍尔鸢尾花数据集。
load fisheriris X = meas(:,3:4); % Measurements of original flowers Y = [5 1.45;6 2;2.75 .75]; % New flower data
使用闵可夫斯基距离度量和切比雪夫距离度量,在 X 和查询点 Y 之间执行 knnsearch。
[mIdx,mD] = knnsearch(X,Y,'K',10,'Distance','minkowski','P',5); [cIdx,cD] = knnsearch(X,Y,'K',10,'Distance','chebychev');
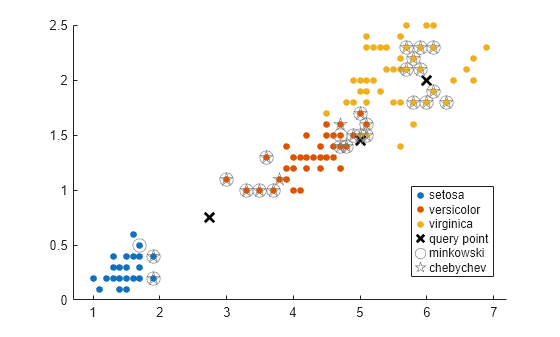
可视化两个最近邻搜索的结果。绘制训练数据。用标记 X 绘制查询点。使用圆圈表示闵可夫斯基最近邻点。使用五角星表示切比雪夫最近邻点。
gscatter(X(:,1),X(:,2),species) line(Y(:,1),Y(:,2),'Marker','x','Color','k',... 'Markersize',10,'Linewidth',2,'Linestyle','none') line(X(mIdx,1),X(mIdx,2),'Color',[.5 .5 .5],'Marker','o',... 'Linestyle','none','Markersize',10) line(X(cIdx,1),X(cIdx,2),'Color',[.5 .5 .5],'Marker','p',... 'Linestyle','none','Markersize',10) legend('setosa','versicolor','virginica','query point',... 'minkowski','chebychev','Location','best')
创建两个由点组成的大型矩阵,然后测量 knnsearch 采用默认的 "euclidean" 距离度量时所用的时间。
rng default % For reproducibility N = 10000; X = randn(N,1000); Y = randn(N,1000); Idx = knnsearch(X,Y); % Warm up function for more reliable timing information tic Idx = knnsearch(X,Y); standard = toc
standard = 25.3805
接下来,测量 knnsearch 采用 "fasteuclidean" 距离度量时所用的时间。指定缓存大小为 100。
Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); % Warm up function tic Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); accelerated = toc
accelerated = 2.4388
计算加速后的计算比标准计算快多少倍。
standard/accelerated
ans = 10.4071
对于此示例,加速版本快三倍以上。
输入参数
名称-值参数
输出参量
提示
对于固定正整数 k,
knnsearch在X中找到 k 个最接近Y中每个点的点。要找到X中在固定距离内接近Y中每个点的所有点,请使用rangesearch。knnsearch不保存搜索对象。要创建一个搜索对象,请使用createns。
算法
替代功能
如果您将 knnsearch 函数的 'NSMethod' 名称-值对组参量设置为合适的值('exhaustive' 用于穷举搜索算法,或 'kdtree' 用于 Kd 树算法),则搜索结果等效于使用 knnsearch 对象函数进行距离搜索得到的结果。与 knnsearch 函数不同,knnsearch 对象函数需要 ExhaustiveSearcher 或 KDTreeSearcher 模型对象。
Simulink 模块
要将 k 最近邻搜索集成到 Simulink® 中,您可以使用 Statistics and Machine Learning Toolbox™ 库中的 KNN Search 模块或具有 knnsearch 函数的 MATLAB Function 模块。有关示例,请参阅Predict Class Labels Using MATLAB Function Block。
在决定要使用的方法时,请考虑以下因素:
如果使用 Statistics and Machine Learning Toolbox 库模块,可以使用定点工具 (Fixed-Point Designer)将浮点模型转换为定点。
必须为具有
knnsearch函数的 MATLAB Function 模块启用对可变大小数组的支持。
参考
[1] Friedman, J. H., J. Bentley, and R. A. Finkel. “An Algorithm for Finding Best Matches in Logarithmic Expected Time.” ACM Transactions on Mathematical Software 3, no. 3 (1977): 209–226.