logp
Document log-probabilities and goodness of fit of LDA model
Syntax
Description
___ = logp(___,
specifies additional options using one or more name-value pair arguments.Name,Value)
Examples
To reproduce the results in this example, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3092
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ] (1×3092 string)
NumDocuments: 154
Fit an LDA model with 20 topics. To suppress verbose output, set 'Verbose' to 0.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0);Compute the document log-probabilities of the training documents and show them in a histogram.
logProbabilities = logp(mdl,documents); figure histogram(logProbabilities) xlabel("Log Probability") ylabel("Frequency") title("Document Log-Probabilities")
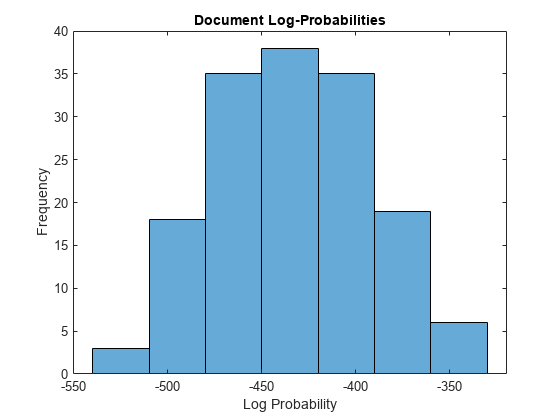
Identify the three documents with the lowest log-probability. A low log-probability may suggest that the document may be an outlier.
[~,idx] = sort(logProbabilities); idx(1:3)
ans = 3×1
146
19
65
documents(idx(1:3))
ans =
3×1 tokenizedDocument:
76 tokens: poor soul centre sinful earth sinful earth rebel powers array why dost thou pine suffer dearth painting thy outward walls costly gay why large cost short lease dost thou upon thy fading mansion spend shall worms inheritors excess eat up thy charge thy bodys end soul live thou upon thy servants loss let pine aggravate thy store buy terms divine selling hours dross fed rich shall thou feed death feeds men death once dead theres dying
76 tokens: devouring time blunt thou lions paws make earth devour own sweet brood pluck keen teeth fierce tigers jaws burn longlivd phoenix blood make glad sorry seasons thou fleets whateer thou wilt swiftfooted time wide world fading sweets forbid thee heinous crime o carve thy hours loves fair brow nor draw lines thine antique pen thy course untainted allow beautys pattern succeeding men yet thy worst old time despite thy wrong love shall verse ever live young
73 tokens: brass nor stone nor earth nor boundless sea sad mortality oersways power rage shall beauty hold plea whose action stronger flower o shall summers honey breath hold against wrackful siege battering days rocks impregnable stout nor gates steel strong time decays o fearful meditation alack shall times best jewel times chest lie hid strong hand hold swift foot back spoil beauty forbid o none unless miracle might black ink love still shine bright
Load the example data. sonnetsCounts.mat contains a matrix of word counts and a corresponding vocabulary of preprocessed versions of Shakespeare's sonnets.
load sonnetsCounts.mat
size(counts)ans = 1×2
154 3092
Fit an LDA model with 20 topics.
numTopics = 20; mdl = fitlda(counts,numTopics)
Initial topic assignments sampled in 0.210017 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.09 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.17 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.21 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.16 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.11 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.07 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.10 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23" "24" "25" "26" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Compute the document log-probabilities of the training documents. Specify to draw 500 samples for each document.
numSamples = 500; logProbabilities = logp(mdl,counts, ... 'NumSamples',numSamples);
Show the document log-probabilities in a histogram.
figure histogram(logProbabilities) xlabel("Log Probability") ylabel("Frequency") title("Document Log-Probabilities")
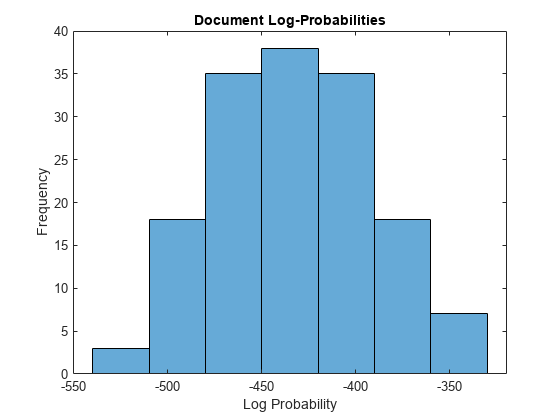
Identify the indices of the three documents with the lowest log-probability.
[~,idx] = sort(logProbabilities); idx(1:3)
ans = 3×1
146
19
65
Compare the goodness of fit for two LDA models by calculating the perplexity of a held-out test set of documents.
To reproduce the results, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Set aside 10% of the documents at random for testing.
numDocuments = numel(documents);
cvp = cvpartition(numDocuments,'HoldOut',0.1);
documentsTrain = documents(cvp.training);
documentsTest = documents(cvp.test);Create a bag-of-words model from the training documents.
bag = bagOfWords(documentsTrain)
bag =
bagOfWords with properties:
NumWords: 2909
Counts: [139×2909 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ] (1×2909 string)
NumDocuments: 139
Fit an LDA model with 20 topics to the bag-of-words model. To suppress verbose output, set 'Verbose' to 0.
numTopics = 20;
mdl1 = fitlda(bag,numTopics,'Verbose',0);View information about the model fit.
mdl1.FitInfo
ans = struct with fields:
TerminationCode: 1
TerminationStatus: "Relative tolerance on log-likelihood satisfied."
NumIterations: 26
NegativeLogLikelihood: 5.6915e+04
Perplexity: 742.7118
Solver: "cgs"
History: [1×1 struct]
Compute the perplexity of the held-out test set.
[~,ppl1] = logp(mdl1,documentsTest)
ppl1 = 781.6078
Fit an LDA model with 40 topics to the bag-of-words model.
numTopics = 40;
mdl2 = fitlda(bag,numTopics,'Verbose',0);View information about the model fit.
mdl2.FitInfo
ans = struct with fields:
TerminationCode: 1
TerminationStatus: "Relative tolerance on log-likelihood satisfied."
NumIterations: 37
NegativeLogLikelihood: 5.4466e+04
Perplexity: 558.8685
Solver: "cgs"
History: [1×1 struct]
Compute the perplexity of the held-out test set.
[~,ppl2] = logp(mdl2,documentsTest)
ppl2 = 808.6602
A lower perplexity suggests that the model may be better fit to the held-out test data.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The logp uses the iterated pseudo-count
method described in [1].
References
[1] Wallach, Hanna M., Iain Murray, Ruslan Salakhutdinov, and David Mimno. "Evaluation methods for topic models." In Proceedings of the 26th annual international conference on machine learning, pp. 1105–1112. ACM, 2009. Harvard
Version History
Introduced in R2017b