transform
Transform documents into lower-dimensional space
Syntax
Description
dscores = transform(___,Name,Value)ldaModel
object.
Examples
Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3092
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ] (1×3092 string)
NumDocuments: 154
Fit an LSA model with 20 components.
numCompnents = 20; mdl = fitlsa(bag,numCompnents)
mdl =
lsaModel with properties:
NumComponents: 20
ComponentWeights: [2.7866e+03 515.5889 443.6428 316.4191 295.4065 261.8927 226.1649 186.2160 170.6413 156.6033 151.5275 146.2553 141.6741 135.5318 134.1694 128.9931 124.2382 122.2931 116.5035 116.2590]
DocumentScores: [154×20 double]
WordScores: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" … ] (1×3092 string)
FeatureStrengthExponent: 2
Use transform to transform the first 10 documents into the semantic space of the LSA model.
dscores = transform(mdl,documents(1:10))
dscores = 10×20
5.6059 -1.8559 0.9286 -0.7086 -0.4652 0.8340 0.6751 -0.0611 -0.2268 1.9320 -0.7289 -1.0864 0.7131 -0.0571 -0.3401 0.0940 -0.4406 1.7507 -1.1534 0.1785
7.3069 -2.3578 1.8359 -2.3442 -1.5776 2.0310 0.7948 -1.3411 1.1700 1.8839 0.0883 0.4734 -1.1244 0.6795 1.3585 -0.0247 0.3627 -0.5414 -0.0272 -0.0114
7.1056 -2.3508 -2.8837 -1.0688 -0.3462 0.6962 0.0334 0.0472 -0.4916 0.6496 -1.1959 -1.0171 -0.4020 1.2953 -0.4583 0.5984 -0.3890 1.1780 0.6413 0.6575
8.6292 -3.0471 -0.8512 -0.4356 -0.3055 -0.4671 -1.4219 0.8454 0.8270 0.4122 2.2082 -1.1770 1.7775 -2.2344 -2.7813 1.4979 0.7486 -2.0593 0.6376 1.0721
1.0434 1.7490 0.8703 -2.2315 -1.1221 -0.2848 -2.0522 0.6975 -1.7191 -0.2852 0.8879 0.9950 -0.5555 0.8842 -0.0360 1.0050 0.4158 0.5061 0.9602 0.4672
6.8358 -2.0806 -3.3798 -1.0452 -0.2075 -2.0970 -0.4477 -0.2080 -0.9532 1.6203 0.6653 0.0036 1.0825 0.6396 -0.2154 -0.0794 0.7108 1.8007 -4.0326 -0.3872
2.3847 0.3923 -0.4323 -1.5340 0.4023 1.0396 -1.0326 -0.3776 -0.2101 -1.0944 -0.7513 -0.2894 0.4303 0.1864 0.4922 0.4844 0.5191 -0.2378 0.9528 0.4817
3.7925 -0.3941 -4.4610 -0.4930 0.4651 -0.3404 -0.5493 -0.1470 -0.5065 0.2566 0.3394 -1.1529 -0.0391 -0.8800 -0.4712 0.9672 0.5457 -0.3639 -0.3085 0.5637
4.6522 0.7188 -1.1787 -0.8996 0.3360 -0.4531 -0.1935 -0.3328 0.8640 -1.6679 -0.8056 -2.1993 0.1808 0.0163 -0.9520 -0.8982 0.6603 3.6451 1.2412 1.9621
8.8218 -0.8168 -2.5101 1.1197 -0.8673 1.2336 0.0768 -0.1943 0.7629 -0.1222 0.3786 1.1611 0.2326 0.3415 -0.3327 -0.3792 1.7554 0.2526 -2.1574 -0.0193
To reproduce the results in this example, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3092
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ] (1×3092 string)
NumDocuments: 154
Fit an LDA model with five topics.
numTopics = 5; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.023008 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.00 | | 1.212e+03 | 1.250 | 0 | | 1 | 0.01 | 1.2300e-02 | 1.112e+03 | 1.250 | 0 | | 2 | 0.01 | 1.3254e-03 | 1.102e+03 | 1.250 | 0 | | 3 | 0.01 | 2.9402e-05 | 1.102e+03 | 1.250 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 5
WordConcentration: 1
TopicConcentration: 1.2500
CorpusTopicProbabilities: [0.2000 0.2000 0.2000 0.2000 0.2000]
DocumentTopicProbabilities: [154×5 double]
TopicWordProbabilities: [3092×5 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
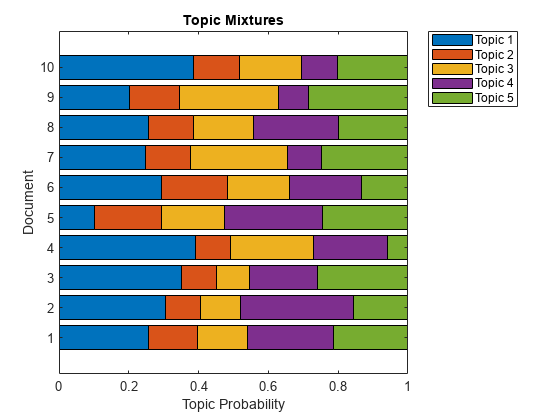
Use transform to transform the documents into a vector of topic probabilities. You can visualize these mixtures using stacked bar charts. View the topic mixtures of the first 10 documents.
topicMixtures = transform(mdl,documents(1:10)); figure barh(topicMixtures,'stacked') xlim([0 1]) title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend("Topic " + string(1:numTopics),'Location','northeastoutside')
Load the example data. sonnetsCounts.mat contains a matrix of word counts and a corresponding vocabulary of preprocessed versions of Shakespeare's sonnets.
load sonnetsCounts.mat
size(counts)ans = 1×2
154 3092
Fit an LDA model with 20 topics. To reproduce the results in this example, set rng to 'default'.
rng('default')
numTopics = 20;
mdl = fitlda(counts,numTopics)Initial topic assignments sampled in 0.016452 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.00 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.01 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.02 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.01 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.01 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.01 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.01 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23" "24" "25" "26" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Use transform to transform the documents into a vector of topic probabilities.
topicMixtures = transform(mdl,counts(1:10,:))
topicMixtures = 10×20
0.0167 0.0035 0.1645 0.0977 0.0433 0.0833 0.0987 0.0033 0.0299 0.0234 0.0033 0.0345 0.0235 0.0958 0.0667 0.0167 0.0300 0.0519 0.0833 0.0300
0.0711 0.0544 0.0116 0.0044 0.0033 0.0033 0.0431 0.0053 0.0145 0.0421 0.0971 0.0033 0.0040 0.1632 0.1784 0.0937 0.0683 0.0398 0.0954 0.0037
0.0293 0.0482 0.1078 0.0322 0.0036 0.0036 0.0464 0.0036 0.0064 0.0612 0.0036 0.0176 0.0036 0.0464 0.0906 0.1169 0.0888 0.1115 0.1180 0.0607
0.0055 0.0962 0.2403 0.0033 0.0296 0.1613 0.0164 0.0955 0.0163 0.0045 0.0172 0.0033 0.0415 0.0404 0.0342 0.0176 0.0417 0.0642 0.0033 0.0676
0.0341 0.0224 0.0341 0.0645 0.0948 0.0038 0.0189 0.1099 0.0187 0.0560 0.1045 0.0356 0.0668 0.1196 0.0038 0.0931 0.0493 0.0038 0.0038 0.0626
0.0445 0.0035 0.1167 0.0034 0.0446 0.0583 0.1268 0.0169 0.0034 0.1135 0.0034 0.0034 0.0047 0.0993 0.0909 0.0582 0.0308 0.0887 0.0856 0.0034
0.1720 0.0764 0.0090 0.0180 0.0325 0.1213 0.0036 0.0036 0.0505 0.0472 0.0348 0.0477 0.0039 0.0038 0.0122 0.0041 0.0036 0.1605 0.1487 0.0465
0.0043 0.0033 0.1248 0.0033 0.0299 0.0033 0.0690 0.1699 0.0695 0.0982 0.0033 0.0039 0.0620 0.0833 0.0040 0.0700 0.0033 0.1479 0.0033 0.0433
0.0412 0.0387 0.0555 0.0165 0.0166 0.0433 0.0033 0.0038 0.0048 0.0033 0.0473 0.0474 0.1290 0.1107 0.0089 0.0112 0.0167 0.1555 0.2423 0.0040
0.0362 0.0035 0.1117 0.0304 0.0034 0.1248 0.0439 0.0340 0.0168 0.0714 0.0034 0.0214 0.0056 0.0449 0.1438 0.0036 0.0290 0.1437 0.0980 0.0304
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2017b