trainBERTDocumentClassifier
Syntax
Description
A Bidirectional Encoder Representations from Transformer (BERT) model is a transformer neural network that can be fine-tuned for natural language processing tasks such as document classification and sentiment analysis. The network uses attention layers to analyze text in context and capture long-range dependencies between words.
mdlTrained = trainBERTDocumentClassifier(documents,targets,mdl,options)
mdlTrained = trainBERTDocumentClassifier(tbl,mdl,options)
Examples
Read the training data from the factoryReports CSV file. The file contains factory reports, including a text description and categorical label for each report.
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); head(data)
Description Category Urgency Resolution Cost
_____________________________________________________________________ ____________________ ________ ____________________ _____
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200
"Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352
"Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55
"Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371
"A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441
"Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
Convert the labels in the Category column of the table to categorical values.
data.Category = categorical(data.Category);
Partition the data into a training set and a test set. Specify the holdout percentage as 10%.
cvp = cvpartition(data.Category,Holdout=0.1); dataTrain = data(cvp.training,:); dataTest = data(cvp.test,:);
Extract the text data and labels from the tables.
textDataTrain = dataTrain.Description; textDataTest = dataTest.Description; TTrain = dataTrain.Category; TTest = dataTest.Category;
Load a pretrained BERT-Base document classifier using the bertDocumentClassifier function.
classNames = categories(data.Category); mdl = bertDocumentClassifier(ClassNames=classNames)
mdl =
bertDocumentClassifier with properties:
Network: [1×1 dlnetwork]
Tokenizer: [1×1 bertTokenizer]
ClassNames: ["Electronic Failure" "Leak" "Mechanical Failure" "Software Failure"]
Specify the training options. Choosing among training options requires empirical analysis. To explore different training option configurations by running experiments, you can use the Experiment Manager (Deep Learning Toolbox) app.
Train using the Adam optimizer.
Train for eight epochs.
For fine-tuning, lower the learning rate. Train using a learning rate of 0.0001.
Shuffle the data every epoch.
Monitor the training progress in a plot and monitor the accuracy metric.
Disable the verbose output.
options = trainingOptions("adam", ... MaxEpochs=8, ... InitialLearnRate=1e-4, ... Shuffle="every-epoch", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
Train the neural network using the trainBERTDocumentClassifier function. By default, the trainBERTDocumentClassifier function uses a GPU if one is available. Training on a GPU requires a Parallel Computing Toolbox™ license and a supported GPU device. For information about supported devices, see GPU Computing Requirements (Parallel Computing Toolbox). Otherwise, the trainBERTDocumentClassifier function uses the CPU. To specify the execution environment, use the ExecutionEnvironment training option.
mdl = trainBERTDocumentClassifier(textDataTrain,TTrain,mdl,options);
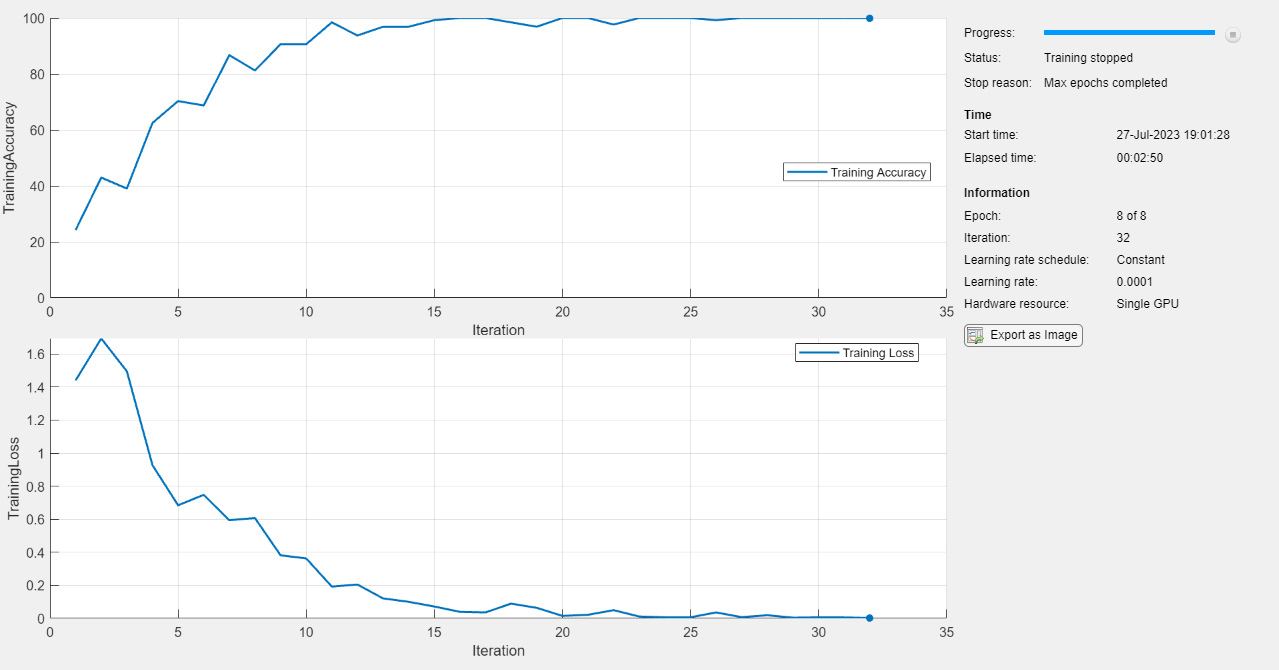
Make predictions using the test data.
YTest = classify(mdl,textDataTest);
Calculate the classification accuracy of the test predictions.
accuracy = mean(TTest == YTest)
accuracy = 0.9375
Input Arguments
Output Arguments
References
[1] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding" Preprint, submitted May 24, 2019. https://doi.org/10.48550/arXiv.1810.04805.
[2] Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. "Dropout: A Simple Way to Prevent Neural Networks from Overfitting." The Journal of Machine Learning Research 15, no. 1 (January 1, 2014): 1929–58
[3] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." Communications of the ACM 60, no. 6 (May 24, 2017): 84–90. https://doi.org/10.1145/3065386.
Version History
Introduced in R2023b
See Also
classify | bertDocumentClassifier | bert | dlnetwork (Deep Learning Toolbox) | bertTokenizer