Adopting Model-Based Design for FPGA, ASIC, and SoC Development
Connecting MATLAB® and Simulink® to digital hardware design and verification has helped numerous customers (examples below) shorten their schedules, improve their verification productivity, and deliver higher quality of results in their FPGA, ASIC, or SoC design processes. While this workflow may seem very different from your existing workflow, you can adopt it incrementally while realizing immediate benefits.
Learn how to:
- Use the strengths of both MATLAB and Simulink together to collaborate to refine your algorithms with more implementation detail
- Build a reusable test bench infrastructure
- Generate SystemVerilog verification components to speed development of your RTL verification environment
- Collaborate between algorithm and digital hardware engineers to converge early on efficient hardware architectures
- Automate and manage the fixed-point conversion process, and even take advantage of native floating-point implementation where it’s more efficient
- Generate error-free synthesizable RTL to target any FPGA, ASIC, or SoC device
This overview outlines proven methods for getting started, along with typical adoption paths from there.
Examples:
Published: 6 Jun 2019
You may have heard one or more of our customers talk about the benefits of connecting MATLAB and Simulink to their FPGA, ASIC, or SoC design workflow. And you may look at it and think that it’s a long way from where you are today. But all of these customers started off adopting one or two capabilities that helped solve one of their most pressing challenges, and built out their full workflow incrementally.
We will first show the high-level benefits of building a more collaborative and connected chip design environment, but the main focus is on how to get started and some of the more common first steps that we see our customers taking, and where they go from there. Then we will wrap up with some real experiences from one of our customers.
If we look at chip design projects today, using the excellent survey data provided by Mentor Graphics and Wilson Research Group, 67% of these projects are behind schedule.
And looking at the top bottlenecks, the one that stands out is verification, which averages over 50% of project time – but most commonly, for ASIC it’s 60-70% while FPGA is about 50-60%.
Even with all that effort, 75% of ASIC projects still require a respin, which has direct costs in millions of dollars but, even worse, can cause your schedule to slip by months.
The same survey shows that 84% of FPGA projects still see non-trivial bugs escape into production. A lot of folks think that’s no big deal because FPGAs are “field programmable” after all, but if it’s on a satellite in space it’s pretty difficult to reprogram. If it’s in a product like inspection equipment in a factory, then it could cause the line to be shut down or you might have to recall a product. And finally, you really do not want hardware bugs escaping into airplanes and automobiles.
At the root of all this is the fact that chip design is a complex process that requires key contributions [and] a lot of specialized skill sets. But they each have their own tools and environments, and too many projects rely on manual communication techniques like handwritten specification documents or meetings in order to succeed. And when there’s incomplete information, assumptions get made or decisions get made locally and often lead to issues that only arise when the system comes together at the end of the project, and fixing them is costly. And this makes it near impossible to be agile in adapting to changing requirements, as noted by Jaimie at Allegro Microsystems, who designs mixed-signal automotive sensor ASICs—definitely a multi-disciplinary product with rigid quality requirements, but they also require the agility to develop customized functionality for each auto maker.
This might look familiar if you are familiar with Model-Based Design. If not, don’t worry.
Often today, this early part is only the system and algorithm designers, who are focused on “what am I making?” on the design side, and “am I making the right thing?” or validation. Then they hand off those specifications to the various implementation engineers to work independently to “make it” and verify that they’ve “made it right.” If one or more of the groups makes one of those local decisions for whatever reason, it causes issues that are not found out until it’s too late.
The key that’s missing is bringing the implementation knowledge into the early part to figure out early on “how will we make it” and “is it going to work” before they go do it, and of course constantly re-integrating as pieces get implemented. It’s making this connection that makes everything work, and this is what we’re focusing on here.
So let’s start with the general approach our customers typically take.
Fundamentally we want to get our algorithms onto hardware. First, we might need to adapt them to work on a continuous stream of data, and as much as possible to be efficient in terms of hardware resource usage while still meeting the functionality and throughput requirements, and that typically includes quantizing data to fixed-point. A lot of our signal processing, wireless, and video/image processing customers are primarily in MATLAB, which of course is great for exploring the mathematics, manipulating data sets, and programming control. But if you’re targeting hardware, which can process in parallel which requires that the timing of parallel paths be managed, Simulink is great for that. It’s also nice for visualization of the architecture and how fixed-point data types are propagated through operations. The nice thing is these two environments work nicely together so we can use the best of both and smoothly transition as we refine those algorithms.
Often the first step is partitioning. A lot of times algorithms and their tests become intertwined in the same MATLAB script. So we need to separate out what will be targeted to hardware. This is also good practice to help build a more robust and automated testing environment. In this example we’re using a pulse detection algorithm, which is pretty simple—it correlates a signal with a matched filter, which will produce a peak where there’s a match. That will be the hardware design. The rest of it will be test bench—the input stimulus, which we won’t get into detail, and the analysis, which for now is just some visualization and fprintf statements.
Focusing on the algorithm—it takes a full signal, runs it through the filter, and then the max function finds the global peak. But in hardware, we have data continuously streaming in. So we need to adapt the algorithm to handle that.
We will build this in Simulink while using some MATLAB too. We can still use the same test environment, getting the input from the “From Workspace” block and sending it back via “To Workspace” blocks. For the filter, we have a streaming FIR block—that’s easy. Then we need to find the magnitude squared, and we can architect it to square both the real and imaginary in parallel. Now, to find the max, we’re going to just store a rolling buffer of the most recent 11 samples.
This is easy to program in MATLAB, so we can use a MATLAB function block, which will find the peak of those 11 samples by checking if the middle sample is larger than the others and also above a minimum threshold to be identified as a “peak.” Because this is constantly streaming, it outputs a pulse to signify that this middle sample is the identified peak.
Now, from a verification standpoint, we have partitioned the design from the stimulus and analysis. This will allow us to swap in any of the versions of the refined design and still compare against the golden reference algorithm. The verification engineers usually call this functionality a “scoreboard.” And notice we’ve added some self-checking capability; this will allow us to run simulations in batch and easily check the results.
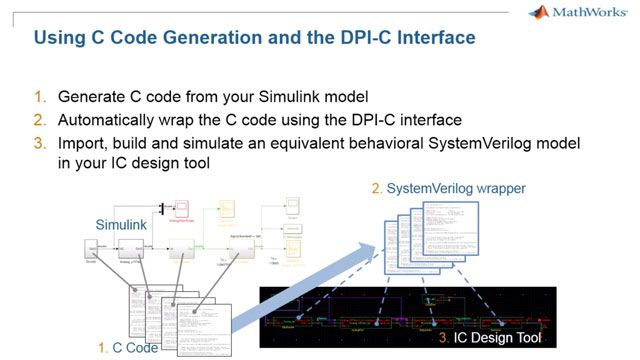
At this point, you can actually generate components to jump-start the RTL verification process. Remember how much of the schedule is consumed by verification? Helping this process along by automatically generating tests and golden reference models helps them get started much earlier, not having to develop and debug their own versions. This is C code wrapped with SystemVerilog, so it runs natively in any SystemVerilog simulator. Because it’s automatically generated, you can think of it as an executable version of the specification, and when the design changes, you just re-generate. This is one really easy way to get started with generating models—it works anywhere C code can be generated from MATLAB or Simulink.
If the RTL simulations identify a mismatch, you can debug by co-simulating MATLAB or Simulink connected to an RTL simulation. Since you have live simulators for both the algorithm and the RTL, you have debug visibility into both sides and they run in lockstep. Given all that, you probably would not be running your regressions this way, but it’s really helpful to debug issues when you need to compare to the actual golden reference algorithm.
Similar to adapting your algorithm for streaming behavior, the next level of refinement is to add hardware architecture. There are a lot of architectural-level decisions that will affect hardware performance and resource usage, and this really requires the expertise of hardware designers. Some examples are shown here—to find the magnitude of the complex filter output, you use the Pythagorean theorem, but a square root operation is very expensive in hardware resources and latency. Knowing we only need to find the largest of a set of values, we can just skip that step – so this is where knowledge of hardware implementation working together with knowledge of the algorithm can get you good results more efficiently.
A simpler example is choosing FFT implementation options, on the FFT block—you can set the radix, how to implement complex multiplication, and adding pipeline stages.
And targeting hardware typically requires fixed-point quantization to reduce resource usage. But this reduces precision, so there’s an efficiency versus accuracy tradeoff that can become a time-consuming back-and-forth process. But we have a couple of approaches that help automate this process and drive it toward convergence, so this is another capability that we see customers adopt as a first step.
The first way is to convert the inputs manually and let Simulink propagate appropriately through the logic. In this example we set the inputs to the multiply at 18 bits to ensure they map to a DSP slice on an FPGA. The outputs can grow through default propagation, but we reduce the output of the sum back down to 18 bits for the next stage. This is where Simulink’s visualization really comes in handy. This approach is a good balanced starting point, and you might be able to converge with some small adjustments.
If you need finer-grained control over your data types, Fixed-Point Designer can help automate and manage things. It will guide you through the steps of simulating a representative sample of tests, collecting data ranges, then it will propose fixed-point types for those data ranges, which you can use as-is or adjust, then simulate using these types to compare to the double-precision to see if the result is within tolerance. And it will also look at overflow/underflow conditions as displayed graphically here.
And the third option is to generate hardware with native floating-point operations using HDL Coder. This is useful for speeding up quantization of the more sensitive operations. Take this simple example here, where someone clearly spent a lot of time building a lookup table to calculate a sine-cosine operation for a 32-bit input with 30 bits of precision. To save a lot of time, you can just use single-precision data types here and generate hardware that performs a native floating-point sine-cosine calculation. Yes, the lookup table will be more efficient in terms of hardware resources, but if you’re just looking to get onto hardware and you have plenty of resources, this approach takes much less time.
And in this case, HDL Coder can actually share the sine and cosine hardware resources. It supports a wide range of operators and optimizations, so you can implement these in hardware without sacrificing accuracy. This is especially helpful for high-dynamic range calculations. You can use this for your whole design, or just isolated regions as shown here. And it generates target-independent RTL.
Demcon used this capability for a precise motor control algorithm for a surgical instrument. You can see their results here, where it did use more hardware resources, but five times less development effort. For more details, you can check out their user story on the MathWorks web site.
Yes, once you get to the point where you have a streaming algorithm with hardware architecture and the numerics that work for your implementation, it’s pretty easy to generate synthesizable VHDL or Verilog using HDL Coder. There are hundreds of hardware-ready blocks, and you can use embedded MATLAB code or Stateflow charts where it’s more efficient—for instance, for complex control logic. You have a lot of options for applying hardware expertise to explore and control optimizations, or just use the defaults to get started quickly. We have a lot of built-in targets set up, including mapping to various AXI bus interfaces, and we have the ability to create custom targets. The really nice part about designing at a high level is exploring, making changes, and generating code without having to worry about making manual coding mistakes.
Those AXI bus interfaces are typically how hardware subsystems communicate with other chip-level subsystems and the software on the processor, and the latency of communicating using these protocols often needs to be modeled. Similarly, using external memory requires reading and writing through a memory controller with latency that might affect how your hardware architecture and algorithm functions. SoC Blockset provides simulation models of these effects so you can simulate the realistic context and get it right before you get onto hardware or even before you partition between hardware and software.
Finally let’s revisit our customer example.
These are the results that Allegro saw; they now design and simulate their analog and digital functionality together in Simulink, debugging issues early, and refine it with implementation detail, continuously integrating the refined models for verification. This allows them to still parallelize their development while constantly verifying everything together to eliminate late surprises. Once they get to an implementation-ready model, they generate synthesizable RTL to go into implementation and they also generate DPI components for their verification environment. Jaimie provides a lot more detail in the recorded MATLAB Expo video. I encourage you to check it out.
To get started with Model-Based Design for implementing hardware, it’s best to take an incremental approach, partitioning and refining your algorithms with implementation detail by collaborating between algorithm and hardware design, and starting with verification models or maybe fixed-point conversion to get some early return on a small investment. This will not only eliminate those communication issues but by getting these folks working together, you’ll get a better overall design. As you get more comfortable and move toward designs you can generate synthesizable RTL for, you will have the agility to easily re-generate for changing requirements.
If you’re interested in learning more about how best to get started, for instance with verification with fixed-point conversion, or with refining a MATLAB algorithm toward hardware implementation, you can get more detail these techniques from these resources, or you can talk to us directly by contacting sales as shown here.

Featured Product