FPGA 或 ASIC 部署:定点转换不再必选
作者 Jack Erickson, Kiran Kintali, and Jonathan Young, MathWorks
MATLAB® 和 Simulink® 使用基于浮点的建模方法来确保实现算法仿真的高精度计算。转换为定点会降低数学精度。而且,在转换过程中,可能很难在数据类型字长与数学精确度之间取得适当的平衡。对于要求高动态范围或高精度的计算(例如有反馈回路的设计),定点转换可能需要几周乃至数月的工程时间,可能还会导致定点字长较大。
自 R2016b 版起,您可以使用 HDL Coder™ 的本机浮点库,直接在 Simulink 中基于单精度浮点数据为 FPGA 或 ASIC 实现生成 HDL 代码。
在本文中,我们将以部署到 FPGA 的 IIR 滤波器为例介绍本机浮点工作流。然后,我们将了解使用定点所带来的挑战,并对使用单精度浮点或定点的面积和频率进行权衡比较。最后,我们还将说明组合使用浮点和定点如何在提供更高精度的同时,帮助您在实际设计中缩短转换和实现时间。您将会了解浮点是如何在有高动态范围要求的实际设计中显著减小面积并提高速度的。
本机浮点实现:深度解析
HDL Coder 通过在 FPGA 或 ASIC 资源上模拟基础数学来实现单精度算术运算(图 1)。生成的逻辑将输入浮点信号解包为符号、指数和尾数,它们分别是宽度为 1、8 和 23 位的整数。然后,生成的 VHDL® 或 Verilog® 逻辑执行浮点计算(图 1 所示的乘法):找出从输入符号位得到的符号位、模乘法、指数加法以及计算结果所需的对应归一化。该逻辑的最后一个阶段将符号、指数和尾数打包回浮点数据类型。
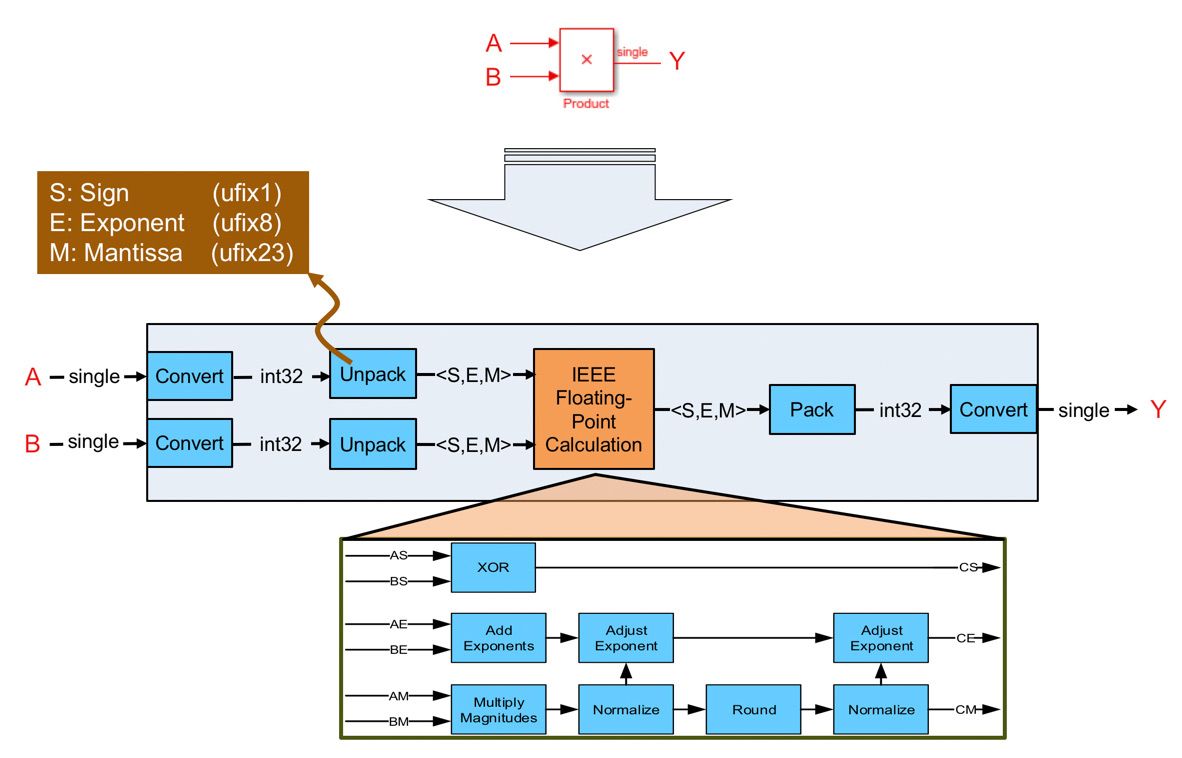
图 1. HDL Coder 如何将单精度浮点乘法映射到定点硬件资源。
如果在 HDL 工作流顾问中选择“本机浮点库”代码生成选项,HDL Coder 会自动为您的单精度运算执行所有这些工作。您还可以设置用于更好地控制如何在硬件中实现浮点运算的选项,例如针对特定延迟的选项,以及针对 FPGA 上特定 DSP 逻辑的选项。HDLCoder 还提供了用于将非规范数下溢为零和高效处理 INF 和 NaN 的选项。
通过定点转换解决动态范围问题
像 1-a/1+a 这样的简单表达式,如果需要在动态范围较大的情况下实现,则可以用单精度进行自然转换(图 2)。
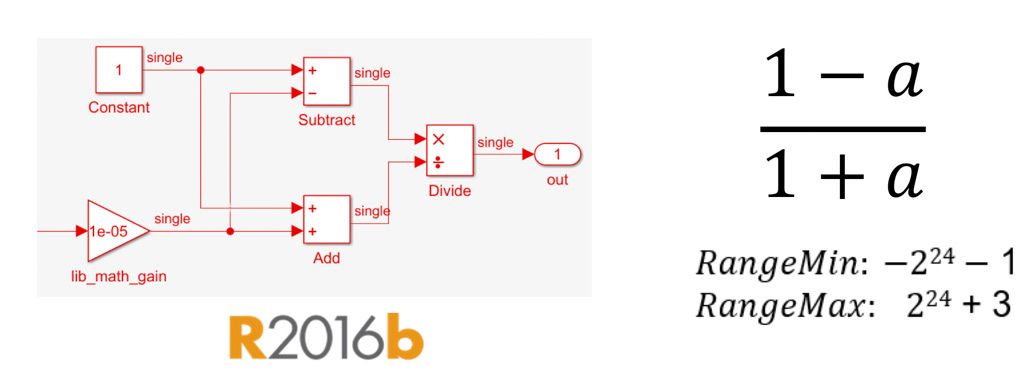
图 2. (1-a)/(1+a) 的单精度实现。
不过,用定点实现该方程需要许多步骤和数值方面的考虑(图 3)。例如,您必须执行以下操作:将除法转化为乘以倒数,使用牛顿-拉夫森或 LUT 等逼近方法进行非线性倒数运算,使用不同数据类型精细控制位增长,选择适当的分子和分母类型,对加法器和减法器使用特定的输出类型和累加器类型。
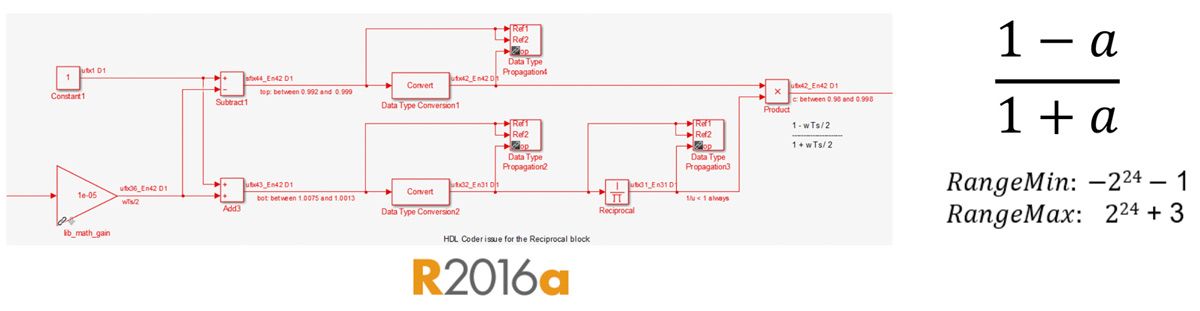
图 3. (1-a)/(1+a) 的定点实现。
探索 IIR 实现选项
我们来看一个无限冲激响应 (IIR) 滤波器的例子。IIR 滤波器具有反馈回路,需要进行高动态范围计算,这使得定点量化时难以实现收敛。图 4a 所示的测试环境对具有含噪正弦波输入的同一 IIR 滤波器的三个版本进行了比较。正弦波的幅值为 1,添加的噪声使幅值略有增加。该滤波器的第一个版本是双精度实现(图 4b)。第二个版本是单精度实现。第三个版本是定点实现(图 4c)。此实现使数据类型字长多达 22 位,其中 1 位分配给符号,而 21 位分配给小数。这种特殊的数据类型保留 0 位来表示整数值,这是有意义的,因为对于给定的激励,其值始终介于 -1 和 1 之间。如果设计必须使用不同输入值,则定点量化时需要将此考虑在内。

图 4a. 具有含噪正弦波输入的 IIR 滤波器的三种实现。

图 4b. IIR_filter 实现,以双精度数据类型显示。

图 4c. IIR_filter_fixpt 实现,使用字长为 18 位的有符号定点数据类型,其中 16 位表示小数长度。
建立测试环境是为了将单精度滤波器和定点滤波器的结果与双精度滤波器的结果进行比较,其中双精度滤波器被视为黄金参考。在这两种情况下,都会造成精度损失,从而带来一定的误差。问题在于此误差是否在我们应用的可接受范围内。
在运行 Fixed-Point Designer™ 来执行转换时,我们指定了 1% 的误差容限。图 5 显示比较的结果。单精度版本的误差约为 10-8,而定点数据类型的误差约为 10-5。它们都在我们指定的误差容限内。如果您的应用需要更高的精度,您可能需要增加定点字长。

图 5. 使用双精度 IIR 滤波器的仿真结果与单精度仿真结果的比较(上图),和定点仿真结果的比较(下图)。
若要在定点量化时实现收敛,需要硬件设计经验、全面了解可能的系统输入、清晰的精度要求,以及借助 Fixed-Point Designer。如果这有助于简化用于生产部署的算法,则是值得一试的做法。但是,如果只需简单地部署到原型硬件,或精度要求使得很难减少物理占用空间,那该怎么办?
在这些情况下,一种解决办法就是使用单精度本机浮点。
使用本机浮点简化流程
使用本机浮点有下面两个好处:
- 您不必花时间尝试分析至少需要多少位数才能满足各种输入数据的精度要求。
- 单精度浮点运算的动态范围以 32 位的固定硬件资源成本进行更高效的扩展。
设计过程现在简单多了。而且,我们也知道了用符号位、指数位和尾数位就可以表示较大的数字动态范围。图 6 中的表比较了利用图 5 所示数据类型选项的 IIR 滤波器的浮点实现和定点实现的资源使用量。

图 6. IIR 滤波器的定点实现和浮点实现之间的资源使用量比较。
在比较从浮点实现和定点实现获得的结果时,请记住浮点计算需要的运算比简单的定点算术运算要多。在部署到 FPGA 或 ASIC 时,使用单精度将会增加物理资源使用量。如果电路面积是必须考虑的问题,则您需要在更高精度与资源使用量之间进行权衡。您还可以在使用浮点和定点的组合来减少电路面积的同时保留单精度,以在数值密集型计算孤岛中实现高动态范围。
通过本机浮点管理资源使用量
本机浮点便于为高动态范围应用生成代码,以对 FPGA 进行编程或部署到 ASIC。但是,使用本机浮点时的资源使用量如果超出您的资源预算,则可通过下面几种方法来减少:
- 使用 HDL Coder 优化。资源共享和其他算法级优化支持本机浮点代码生成。例如,这些优化可通过时分多路复用以及其他共享和流式传输方法共享占用大量电路面积的复杂数学运算(例如
exp、atan2)来减少面积。 - 酌情使用定点转换过程。对于没有高动态范围要求或反馈回路的设计,定点转换简单直接。Fixed-Point Designer 有助于实现此过程的自动化。对于某些类型的设计,可能很难在不增加额外位数的情况下实现收敛。在这种情况下,有选择地使用本机浮点是个不错的做法。这种方法在大部分设计中使用定点转换,同时支持在数据路径的高动态范围部分中使用浮点。
- 在设计中创建浮点和定点“孤岛”。一旦确定了设计中难以实现收敛的部分,就可以使用 Data Type Conversion 模块将输入转换为单精度,然后再将运算的输出转换回适当的定点类型,从而隔离这些部分。图 7 显示某电机控制设计的一部分,其中增益运算和 sincos 运算隔离为本机浮点区域,而输出转换回定点值。
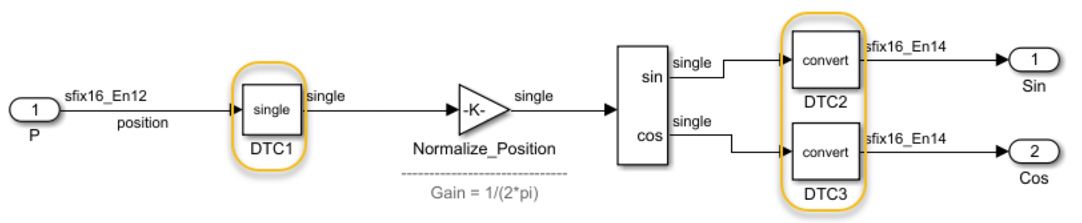
图 7. 在同一设计中混合使用定点和本机浮点。
下面是在设计中选择浮点或定点的快速指南:
在以下情况中,对整个设计使用浮点:
- 您缺乏定点量化经验。
- 您的算法中混合使用非常大和非常小的数值。
- 您的设计大量使用多于 32 位的定点类型。
- 您的设计包括
divide、mod、rem、log、exp和atan等非线性运算,这些运算很难转换为定点。 - 您可以灵活地使用更大的面积和延迟(例如,在电机控制或音频处理等带宽较小的应用中)。
在以下情况中,对整个设计使用定点:
- 您有定点量化经验。
- 将您的算法转换为定点简单直接。
- 您有严格的面积和延迟要求。
在以下情况中,混合使用浮点和定点:
- 您的设计混合使用控制逻辑和动态范围较大的数据路径。
- 只有一部分设计难以量化到定点。
- 浮点算术运算耗用的资源不多,因此,满足您的面积要求绰绰有余。
使用本机浮点的真实示例
如图 8 所示,如果您要处理动态范围问题,并计划采用更大的字长,则定点实现耗用的资源可能远远超过浮点实现。

图 8. Sqrt 函数的资源使用量。如果使用的字长较大,sqrt 耗用的 FPGA 资源比采用固定字长的单精度实现要多。
我们以下面的电动汽车模型(图 9)为例,了解一下在这种情况下本机浮点是如何发挥作用的。这是一个由多个组件组成的复杂模型,其中包括电池模型、逆变器、PMSM 和车辆模型。

图 9. 电动汽车模型。
图 10 显示用于实现这些组件的数学方程。
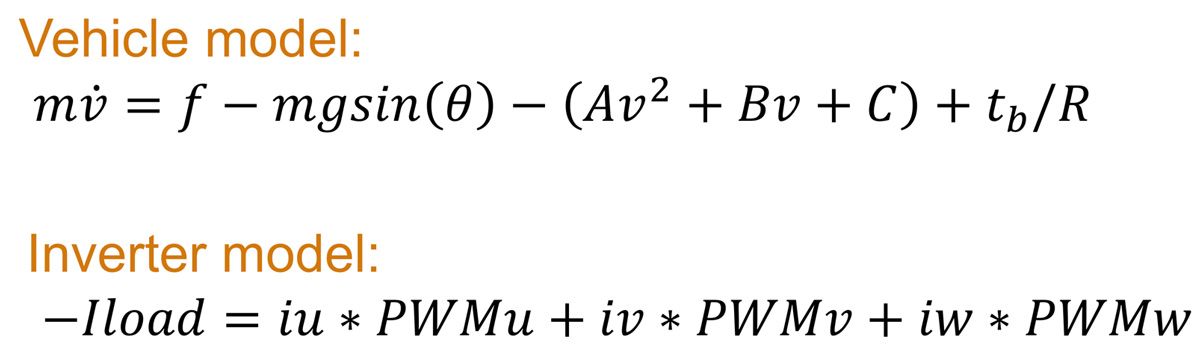
图 10. 电动汽车模型中使用的数学方程。
组件之间存在着各种反馈回路,这可能使得通过定点将这种模型用于硬件变得困难重重。对于 PMSM 和逆变器之间存在复杂反馈回路的组件系统,找到减少量化误差的方法可能需要数月的时间。为了减少误差,您必须使用非常大的字长。但是,借助浮点支持,您可以直接将此模型用于硬件,而无需将其转换为定点。
如图 11 所示,对于具有反馈回路的算法,浮点是正确的数据类型选择,因为浮点实现占用的面积更少,性能也更好,而该算法的定点版本需要的字长较大。
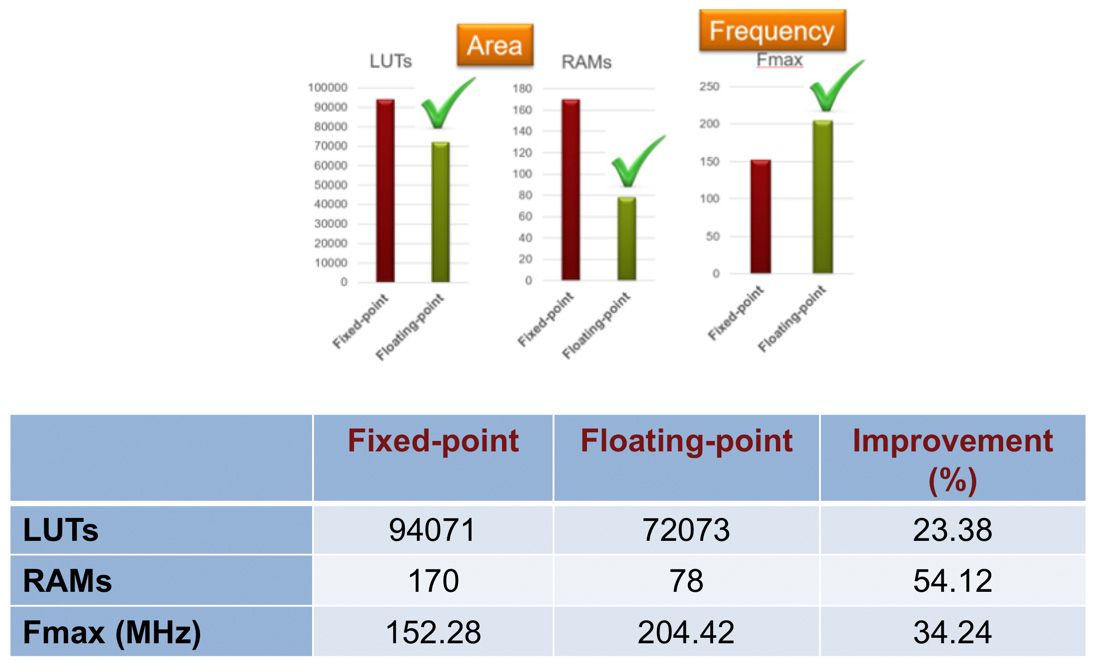
图 11. 电动汽车模型定点实现和浮点实现的比较。
结束语
定点量化一直是根据目标 FPGA 或 ASIC 硬件调整算法中最具挑战性的任务之一。通过本机浮点 HDL 代码生成,您无需进行定点转换,即可在硬件中为浮点实现生成 VHDL 或 Verilog。如果您创建的是 FPGA 实现,这种方法可以节省大量时间。它还可以加速将算法应用于 Xilinx® Zynq® SoC 或 Intel® SoC FPGA。
对于需要两全其美的设计,既具有定点的控制逻辑,又不乏浮点的高动态范围数据路径,您可以轻松做到二者兼顾。
2018年发布