bioinfo.pipeline.block.SRAFasterqDump
Description
An SRAFasterqDump block enables you to download sequence read
data in the FASTQ or FASTA format from SRA (Sequence Read Archive) [1].
bioinfo.pipeline.block.SRAFasterqDump requires the SRA Toolkit for Bioinformatics Toolbox™. If this support package is not installed, then the function provides a download
link. For details, see Bioinformatics Toolbox Software Support Packages.
Creation
Syntax
Description
b = bioinfo.pipeline.block.SRAFasterqDumpSRAFasterqDump block.
b = bioinfo.pipeline.block.SRAFasterqDump(options)options.
b = bioinfo.pipeline.block.SRAFasterqDump(Name=Value)FastaOutput
name-value argument. The name-value arguments sets the property names and values of an
SRAFasterqDumpOptions object. These property values are assigned to the
Options property of the block.
Input Arguments
Name-Value Arguments
Properties
Object Functions
compile | Perform block-specific additional checks and validations |
copy | Copy array of handle objects |
emptyInputs | Create input structure for use with run method |
eval | Evaluate block object |
run | Run block object |
Examples
Import the pipeline and block objects needed for the example so that you can create these objects without specifying the entire namespace.
import bioinfo.pipeline.Pipeline import bioinfo.pipeline.block.*
Create a pipeline.
P = Pipeline;
Create an SRAFasterqDump block and specify the accession number SRR11846824 as the block input. SRR11846824 has two reads per spot and no unaligned reads.
SRAFQDump = SRAFasterqDump;
SRAFQDump.Inputs.SRRID.Value = "SRR11846824";
addBlock(P,SRAFQDump);Run the pipeline to download the corresponding FASTQ files from SRA for the specified accession number.
run(P);
Get the results of the SRAFQDump block.
R = results(P,SRAFQDump)
R = struct with fields:
Reads: [1×1 bioinfo.pipeline.datatype.Incomplete]
Reads_1: [1×1 bioinfo.pipeline.datatype.File]
Reads_2: [1×1 bioinfo.pipeline.datatype.File]
Reads_3: [1×1 bioinfo.pipeline.datatype.Incomplete]
Reads_4: [1×1 bioinfo.pipeline.datatype.Incomplete]
Reads_5: [1×1 bioinfo.pipeline.datatype.Incomplete]
View the names of the downloaded files by using the unwrap function.
unwrap(R.Reads_1) unwrap(R.Reads_2)
By default, the block uses the SplitType="SplitThree" option and downloads only biological reads. Specifically, the block splits spots into reads. For spots with two reads, the block produces *_1.fastq and *_2.fastq and displays them in the Reads_1 and Reads_2 fields, respectively. The block saves any unaligned reads in a *.fastq file and displays it in the Reads field. Because this accession has no unaligned reads, the block did not produce a *.fastq file, and the Reads field is returned as Incomplete. Reads_3, Reads_4, and Reads_5 are also Incomplete because of the usage of SplitType="SplitThree". For more details on the block output behavior, see Outputs.
You can specify other download options using the SRAFasterqDumpOptions. For instance, to download the FASTA-formatted file, specify FastaOutput=true and rerun the block.
opt = SRAFasterqDumpOptions; opt.FastaOutput = true; SRAFQDump.Options = opt;
You can also download SAM files from SRA using the SRASAMDump block.
SRASDump = SRASAMDump;
Specify the accession number to download.
SRASDump.Inputs.SRRID.Value = "SRR11846824";Specify the options using an SRASAMDumpOptions object. For instance, set the output filename and compress the output file using bzip2.
samdumpopt = SRASAMDumpOptions;
samdumpopt.BZip2 = 1;
samdumpopt.OutputFileName = "SRR11846824.sam.bz2"samdumpopt =
SRASAMDumpOptions with properties:
Default properties:
ExtraCommand: ""
FastaOutput: 0
FastqOutput: 0
GZip: 0
HideIdentical: 0
IncludeAll: 0
MinMapQuality: 0
OutputPrimary: 0
OutputUnaligned: 0
Version: "3.0.6"
Modified properties:
BZip2: 1
OutputFileName: "SRR11846824.sam.bz2"
SRASDump.Options = samdumpopt;
Add the block to the pipeline and run the pipeline.
addBlock(P,SRASDump); run(P);
Get the block results.
R2 = results(P,SRASDump);
View the names of the output files by using the unwrap function.
unwrap(R2.OutputFiles)
After downloading the files, you can use them for downstream analyses. For instance, you can run bowtie2 to map the reads to the reference sequence, and then visualize the mapped reads in the Genomics Viewer app.
First, download the C. elegans reference sequence.
celegans_refseq = fastaread("https://s3.amazonaws.com/igv.broadinstitute.org/genomes/seq/ce11/ce11.fa");Save the Chromosome 3 reference data in a FASTA file.
celegans_chr3 = celegans_refseq(3).Sequence;
fastawrite("celegans_chr3.fa",celegans_chr3);Create a FileChooser block to select the Chromosome 3 reference file.
fcRef = FileChooser;
fcRef.Files = fullfile(pwd,"celegans_chr3.fa");
addBlock(P,fcRef);Build a set of index files using the Bowtie2Build block. Set the base name of the index files and the name of the reference FASTA file.
buildIndex = Bowtie2Build; buildIndex.Inputs.IndexBaseName.Value = "celegans_chr3_index"; addBlock(P,buildIndex); connect(P,fcRef,buildIndex,["Files","ReferenceFASTAFiles"]); run(P);
Align reads to the reference using the Bowtie2 block. Create the block and then connect it to buildIndex and SRAFQDump blocks.
alignReads = Bowtie2; alignReads.OutFilename = "SRR11846824_mapped.sam"; addBlock(P,alignReads); connect(P,buildIndex,alignReads,["IndexBaseName","IndexBaseName"]); connect(P,SRAFQDump,alignReads,["Reads_1","Reads1Files";"Reads_2","Reads2Files"]); run(P);
Bowtie2 produces a SAM file. To visualize the mapped reads in the Genomics Viewer app, convert the SAM file to a BAM file.
First, make a UserFunction block to create a BioMap object from the SAM file.
biomapObj = UserFunction; biomapObj.Function = "BioMap"; biomapObj.RequiredArguments = "inputSAM"; biomapObj.OutputArguments = "biomapObject"; addBlock(P,biomapObj);
Next, connect the biomapObj block to the alignReads block, which provides the SAM file needed. Suppress two informational warnings issued during the creation of a BioMap object.
connect(P,alignReads,biomapObj,["SAMFile","inputSAM"]); w = warning; warning("off","bioinfo:BioMap:BioMap:UnsortedReadsInSAMFile"); warning("off","bioinfo:saminfo:InvalidTagField"); run(P); warning(w); % Restore warnings
Use the write method of the BioMap object to convert the SAM file to a BAM file.
sam2bam = UserFunction; sam2bam.Function = "write"; sam2bam.RequiredArguments = ["biomapObj","BAMFileName"]; sam2bam.NameValueArguments = "Format"; sam2bam.Inputs.BAMFileName.Value = "../../../SRR11846824_mapped.bam"; sam2bam.Inputs.Format.Value = "BAM"; addBlock(P,sam2bam); connect(P,biomapObj,sam2bam,["biomapObject","biomapObj"]); run(P);
Create a FileChooser block to select the generated BAM file.
fcBAM = FileChooser;
fcBAM.Files = fullfile(pwd,"SRR11846824_mapped.bam");
addBlock(P,fcBAM);Create a FileChooser block to select the C. elegans cytoband file, which is provided with the toolbox.
fcCyto = FileChooser;
fcCyto.Files = fullfile(pwd,"celegans_cytoBandIdeo.txt.gz");
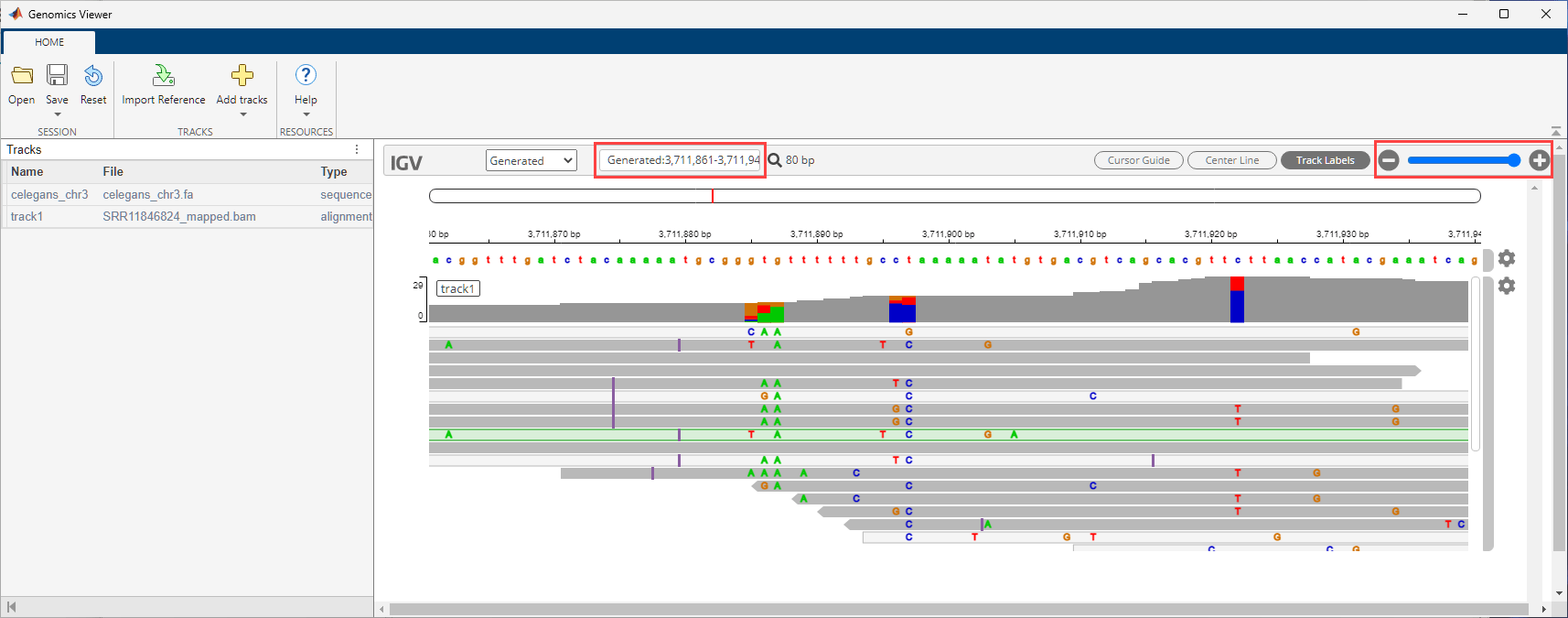
addBlock(P,fcCyto);View the alignment data using the Genomics Viewer app.
gv = GenomicsViewer; addBlock(P,gv); connect(P,fcRef,gv,["Files","Reference"]); connect(P,fcCyto,gv,["Files","Cytoband"]); connect(P,fcBAM,gv,["Files","Tracks"]); run(P);
Use the zoom slider to zoom in and see the features. Or you can enter the following in the search text box: Generated:3,711,861-3,711,940.
Delete the pipeline results and downloaded files.
deleteResults(P,IncludeFiles=true);
References
[1] SRA Toolkit Development Team https://github.com/ncbi/sra-tools/wiki/01.-Downloading-SRA-Toolkit
Version History
Introduced in R2024a