Deploy and Verify YOLO v2 Vehicle Detector on FPGA
This example shows how to deploy a you only look once (YOLO) v2 vehicle detector on FPGA and verify the end-to-end application using MATLAB®.
The end-to-end application includes preprocessing steps, image resize and normalization, followed by a YOLO v2 vehicle detection network.
The example deploys the algorithm to a Xilinx® Zynq® Ultrascale+(TM) MPSoC ZCU102 board. Set up the board's SD card using Guided SD Card Setup.
Introduction
A YOLO v2 vehicle detection application is composed of three main modules. The first module, preprocessing, accepts the input image frame and performs image resize and normalization. In the second module, the preprocessed data is consumed by the YOLO v2 vehicle detection network, which internally comprises a feature extraction network followed by a detection network. In the third module, the network output is postprocessed for identifying the strongest bounding boxes and the resulting bounding box is overlaid on the input image. In this example, as shown in the below block diagram, the first two modules are deployed on the FPGA and the postprocessing is done in MATLAB.

This example shows how to:
Configure the deep learning processor and generate IP core.
Model the design under test (DUT) that includes preprocessing modules (resize and normalization) and handshaking logic with the deep learning processor.
Generate and deploy bitstream to the FPGA.
Compile and deploy YOLO v2 deep learning network.
Verify the deployed YOLO v2 vehicle detector using MATLAB.
Configure Deep Learning Processor and Generate IP Core
The deep learning processor IP core accesses the preprocessed input from the DDR memory, performs the vehicle detection, and loads the output back into the memory. To generate a deep learning processor IP core that has the required interfaces, create a deep learning processor configuration by using the dlhdl.ProcessorConfigInputRunTimeControl and OutputRunTimeControl parameters. These parameters indicate the interface type for interfacing between the input and output of the deep learning processor. To learn about these parameters, see Interface with the Deep Learning Processor IP Core. In this example, the deep learning processor uses the register mode for input and output runtime control.
hPC = dlhdl.ProcessorConfig; hPC.InputRunTimeControl = "register"; hPC.OutputRunTimeControl = "register";
Specify the TargetPlatform property of the processor configuration object as Generic Deep Learning Processor. This option generates a custom generic deep learning processor IP core.
hPC.TargetPlatform = 'Generic Deep Learning Processor';
Use the setModuleProperty method to set the properties of the conv module of the deep learning processor. These properties can be tuned based on the design choice to ensure that the design fits on the FPGA. To learn more about these parameters, see setModulePropertyLRNBlockGeneration is turned on and SegmentationBlockGeneration is turned off to support YOLOv2 vehicle detection network. ConvThreadNumber is set to 9.
hPC.setModuleProperty('conv','LRNBlockGeneration', 'on'); hPC.setModuleProperty('conv','SegmentationBlockGeneration', 'off'); hPC.setModuleProperty('conv','ConvThreadNumber',9);
This example uses the Xilinx ZCU102 board to deploy the deep learning processor. Use the hdlsetuptoolpath function to add the Xilinx Vivado synthesis tool path to the system path.
hdlsetuptoolpath('ToolName','Xilinx Vivado','ToolPath','C:\Xilinx\Vivado\2022.1\bin\vivado.bat');
Use the dlhdl.buildProcessor function with the hPC object to generate the deep learning IP core. It takes some time to generate the deep learning processor IP core.
dlhdl.buildProcessor(hPC);
The generated IP core contains a standard set of registers and the generated IP core report. The IP core report is generated in the same folder as ip core with the name testbench_ip_core_report.html.

IP core name and IP core folder are required in a subsequent step in 'Set Target Reference Design' task of the IP core generation workflow of the DUT. The IP core report also has the address map of the registers that are needed for handshaking with input and output of deep learning processor IP core.

The registers InputValid, InputAddr, and InputSize contain the values of the corresponding handshaking signals that are required to write the preprocessed frame into DDR memory. The register InputNext is used by the DUT to pulse the InputNext signal after the data is written into memory. These register addresses are setup in the helperSLYOLOv2PreprocessSetup.m script. The other registers listed in the report are read/written using MATLAB. For more details on interface signals, see the Design Processing Mode Interface Signals section of Interface with the Deep Learning Processor IP Core.
Model Design Under Test (DUT)
This section describes the design of the preprocessing modules (image resize and image normalization) and the handshaking logic in a DUT.
open_system('YOLOv2PreprocessTestbench');

The figure shows the top level view of the YOLOv2PreprocessTestbench.slx model. The InitFcn callback of the model configures the required workspace variables for the model using helperSLYOLOv2PreprocessSetup.m script. The Select Image subsystem selects the input frame from the Input Images block. A Frame To Pixels block converts the input image frame from the Select Image block to a pixel stream and pixelcontrol bus. The Pack subsystem concatenates the R, G, B components of the pixel stream and the five control signals of the pixelcontrol bus to form uint32 data. The packed data is fed to the YOLO v2 Preprocess DUT for resizing and normalization. This preprocessed data is then written to the DDR using the handshaking signals from deep learning IP core. The DDR memory and the deep learning processor IP core is modeled by using the Deep Learning HDL Processing System block. The model also includes a Verify Output subsystem which logs the signals required for the verification of the preprocessed data being written to memory using preprocessDUTVerify.m script.
open_system('YOLOv2PreprocessTestbench/YOLO v2 Preprocess DUT');

The YOLO v2 Preprocess DUT contains subsystems for unpacking, preprocessing (resize and normalization) and handshaking logic. The Unpack subsystem returns the packed input to the pixel stream and pixelcontrol bus. In the YOLO v2 Preprocess Algorithm subsystem, the input pixel stream is resized and rescaled as required by the deep learning network. This preprocessed frame is then passed to the DL Handshake Logic Ext Mem subsystem to be written into the PL DDR. This example models two AXI4 Master interfaces to write the preprocessed frame to the DDR memory and to read and write the registers of deep learning IP Core.
open_system('YOLOv2PreprocessDUT/YOLO v2 Preprocess Algorithm');

The YOLO v2 Preprocess Algorithm subsystem comprises of resizing, and normalization operations. The pixel stream is passed to the Resize subsystem for resizing to the dimensions expected by the deep learning network. The input image dimensions and the network input dimensions are setup using helperSLYOLOv2PreprocessSetup.m script. The resized input is passed to Normalization subsystem for rescaling the pixel values to [0, 1] range. The resize and normalization algorithms used in this example are described in the Change Image Size (Vision HDL Toolbox) and Image Normalization Using External Memory (Vision HDL Toolbox) examples respectively.
open_system('YOLOv2PreprocessDUT/DL Handshake Logic Ext Mem');

The DL Handshake Logic Ext Mem subsystem contains the finite state machine (FSM) logic for handshaking with DL IP and a subsystem to write the frame to DDR. The Read DL Registers subsystem has the FSM logic to read the handshaking signals (InputValid, InputAddr, and InputSize) from the DL IP core for multiple frames. The Write to DDR subsystem uses these handshaking signals to write the preprocessed frame to the memory using AXI stream protocol. The output write control bus from the DDR memory contains a signal wr_done which indicates that the frame write operation is done successfully. The TriggerDLInputNext subsystem pulses the InputNext signal after the preprocessed frame is written into the DDR to indicate to the DL IP core that the input data frame is available for processing.
In the next section, the IP core is generated for the YOLO v2 Preprocess DUT subsystem and is integrated into the reference design.
Generate and Deploy Bitstream to FPGA
This example uses the Deep Learning with Preprocessing Interface reference design that is provided by the SoC Blockset™ Support Package for Xilinx Devices.
pathToRefDesign = fullfile(... matlabshared.supportpkg.getSupportPackageRoot,... "toolbox","soc","supportpackages","zynq_vision","target",.... "+visionzynq", "+ZCU102", "plugin_rd.m"); if (~exist(pathToRefDesign, 'file')) error(['This example requires you to download and install '... 'SoC Blockset Support Package for Xilinx Devices']); end
The reference design contains the ADI AXI DMA Controller to move the data from processor to FPGA fabric. The data is sent from the ARM processing system, through the DMA controller and AXI4-Stream interface, to the generated DUT Preprocessing IP core. The DUT contains two AXI Master interfaces. One AXI interface is connected to the Deep Learning Processor IP core and the other is connected to the DDR memory interface generator (MIG) IP.

Start the targeting workflow by right clicking the YOLO v2 Preprocess DUT subsystem and selecting HDL Code > HDL Workflow Advisor.
In step 1.1, select IP Core Generation workflow and the platform 'Xilinx Zynq Ultrascale+ MPSoC ZCU102 Evaluation Kit'.
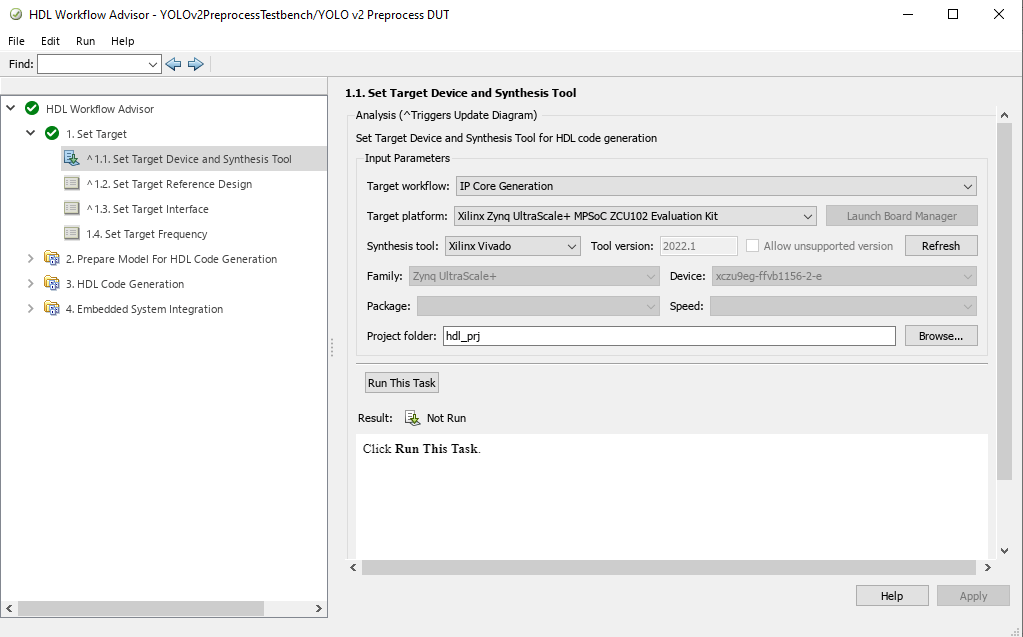
In step 1.2, the reference design is set to "Deep Learning with Preprocessing Interface". The DL Processor IP name and the DL Processor IP location specify the name and location of the generated deep learning processor IP core, and are obtained from the IP core report. The vendor name should be same as the vendor name in the component.xml file for the Deep Learning processor IP core.

In step 1.3, map the target platform interfaces to the input and output ports of the DUT.

AXI4-Stream Slave interface: The
inputDataandvalidports of the DUT are mapped to the data and valid ports of the AXI4-Stream Slave interface respectively.AXI4-Lite Interface: The
DUTProcStartregister is mapped to the AXI4-Lite register. When this register is written, it triggers the process of input handshaking logic. Choosing the AXI4-Lite interface directs HDL Coder to generate a memory-mapped register in the FPGA fabric. You can access this register from software running on the ARM processor.AXI4 Master DDR interface: The
AXIWriteCtrlInDDR,AXIReadCtrlInDDR,AXIReadDataDDR,AXIWriteCtrlOutDDR,AXIWriteDataDDRandAXIReadCtrlOutDDRports of DUT are mapped to AXI4 Master DDR interface. The Read Channel of the AXI4 Master DDR interface is mapped to the AXI4 Master DDR Read interface, and the Write Channel of the AXI4 Master DDR interface is mapped to the AXI4 Master DDR Write interface. This interface is used for the data transfer between the Preprocess DUT and the PL DDR. Using the Write Channel of this interface, the preprocessed data is written to the PL DDR which can then be accessed by the Deep Learning Processor IP.AXI4 Master DL interface: The
AXIReadDataDL,AXIReadCtrlInDL,AXIWriteCtrlInDL,AXIReadCtrlOutDL,AXIWriteDataDLandAXIWriteCtrlOutDLports of DUT are mapped to AXI4 Master DL interface. The Read Channel of the AXI4 Master DL interface is mapped to the AXI4 Master DL Read interface, and the Write Channel of the AXI4 Master DL interface is mapped to the AXI4 Master DL Write interface. This interface is used for the communication between Preprocess DUT and the Deep Learning Processor IP. In this example, this interface is used for implementing input handshaking logic with Deep Learning Processor IP.Step 2 prepares the design for hdl code generation.
Step 3 generates HDL code for the IP core.
Step 4.1 integrates the newly generated IP core into the reference design.
In step 4.2, the host interface script and Zynq software interface model is created. Since this example uses the interface script, and not the model, uncheck Generate Simulink software interface model. The host interface script,
gs_YOLOv2PreprocessTestbench_interface, generated in this step is parameterized and provided assetupPreprocessIPInterfaces.mfunction as part of this example.

Step 4.3 generates the bitstream. The bit file is named
block_design_wrapper.bitand located at hdl_prj\vivado_ip_prj\vivado_prj.runs\impl_1. This bitstream is downloaded to FPGA in the next section.
Compile and Deploy Yolo v2 Deep Learning Network
Now that the bitstream is generated for the IP core of the DUT integrated with the reference design that contains the DL IP core, you can deploy the end to end deep learning application onto an FPGA.
Create a target object to connect your target device to the host computer. Use the installed Xilinx Vivado Design Suite over an Ethernet connection to program the device.
hTarget = dlhdl.Target('Xilinx','Interface','Ethernet','IpAddr','192.168.1.101');
Load the pretrained YOLO v2 object detection network.
vehicleDetector = load('yolov2VehicleDetector.mat');
detector = vehicleDetector.detector;
net = detector.Network;
Update the bitstream build information in the MAT file generated during the IP core generation. The name of the MAT file is dlprocessor.mat and is located in cwd\dlhdl_prj\, where cwd is your current working folder. Copy the file to the present working folder. This MAT file generated using the target platfom Generic Deep Learning Processor does not contain the Board/Vendor information. Use updateBitstreamBuildInfo.m function to update the Board/Vendor information and generate a new MAT file with the same name as generated bitstream.
bitstreamName = 'block_design_wrapper'; updateBitstreamBuildInfo('dlprocessor.mat',[bitstreamName,'.mat']);
Create a deep learning HDL workflow object using the dlhdl.Workflow class.
hW = dlhdl.Workflow('Network',net,'Bitstream',[bitstreamName,'.bit'],'Target',hTarget);
Compile the network, net using the dlhdl.Workflow object.
frameBufferCount = 3;
compile(hW, 'InputFrameNumberLimit', frameBufferCount);
Create a Xilinx processor hardware object and connect to the processor on-board the Xilinx SoC board.
hSOC = xilinxsoc('192.168.1.101', 'root', 'root');
Call the xilinxsoc object function ProgramFPGA to program the FPGA and set the device tree to use the processor on the SoC board.
programFPGA(hSOC, [bitstreamName,'.bit'], 'devicetree_vision_dlhdl.dtb');
Run the deploy function of the dlhdl.Workflow object to download the network weights and biases on the Zynq UltraScale+ MPSoC ZCU102 board.
deploy(hW, 'ProgramBitStream', false);
Clear the DLHDL workflow object and hardware target.
clear hW; clear hTarget;
Verify Deployed YOLO v2 Vehicle Detector Using MATLAB
The function YOLOv2DeployAndVerifyDetector takes hSOC object as input and performs vehicle detection using the YOLO v2 network deployed on FPGA and verifies the end-to-end application using MATLAB.
YOLOv2DeployAndVerifyDetector(hSOC);
This flowchart shows the operations performed in the function.

This section describes the steps in the flowchart in detail.
Load the vehicle data set
unzip('vehicleDatasetImages.zip'); data = load('vehicleDatasetGroundTruth.mat'); vehicleDataset = data.vehicleDataset;
The vehicle data is stored in a two-column table, where the first column contains the image file paths and the second column contains the vehicle bounding boxes. Add the fullpath to the local vehicle data folder.
vehicleDataset.imageFilename = fullfile(pwd,vehicleDataset.imageFilename);
Select images from the vehicle dataset. Each image present in inputDataTbl has 224 rows and 340 columns.
inputDataTbl = vehicleDataset(153:259,:);
Setup deep learning and preprocessing interfaces
Connect to the FPGA on-board the SoC board by using the fpga function. Use the processor hardware object hSOC as an input to the fpga function.
hFPGA = fpga(hSOC);
Get network input and output size. The networkOutputSize is the output size of yolov2ClassConv obtained from analyzeNetwork(net).
networkInputSize = net.Layers(1, 1).InputSize; networkOutputSize = [16,16,24];
The deep learning processor writes the yolov2ClassConv layer output to the external memory in a specified data format. This data format depends on the chosen ConvThreadNumber of the deep learning processor. readLengthFromDLIP contains the output data size. For more information, see External Memory Data Format
readLengthFromDLIP = (networkOutputSize(1)*networkOutputSize(2)*networkOutputSize(3)*4)/3;
Setup the deep learning IP interfaces using setupDLIPInterfaces.m function. This function uses BitstreamManager class to obtain the address map of the deep learning IP core registers.
addrMap = setupDLIPInterfaces(hFPGA, [bitstreamName,'.bit'], readLengthFromDLIP); ddrbaseAddr = dec2hex(addrMap('ddrbase'));
Get image dimensions and create visionhdl.FrameToPixels System object™
frm = imread(inputDataTbl.imageFilename{1});
frmActivePixels = size(frm,2);
frmActiveLines = size(frm,1);
frm2pix = visionhdl.FrameToPixels(...
'NumComponents',size(frm,3),...
'VideoFormat','custom',...
'ActivePixelsPerLine',frmActivePixels,...
'ActiveVideoLines',frmActiveLines,...
'TotalPixelsPerLine',frmActivePixels+10,...
'TotalVideoLines',frmActiveLines+10,...
'StartingActiveLine',6,...
'FrontPorch',5);
Setup the preprocess IP interfaces using setupPreprocessIPInterfaces.m function.
inputFrameLength = frm2pix.TotalPixelsPerLine * frm2pix.TotalVideoLines; setupPreprocessIPInterfaces(hFPGA, inputFrameLength);
Configure deep learning IP core
Set data processing mode to continuous streaming mode by setting StreamingMode register to true and FrameCount register to 0.
writePort(hFPGA, "StreamingMode", 1); writePort(hFPGA, "FrameCount", 0);
Pulse the inputStart signal to indicate to the deep learning IP core to start processing the data.
writePort(hFPGA, "inputStart", 0); writePort(hFPGA, "inputStart", 1); writePort(hFPGA, "inputStart", 0);
Assert DUTProcStart to signal preprocess DUT to start writing the preprocessed data to the DDR.
writePort(hFPGA, "DUTProcStart", 1);
Send input video frame to YOLO v2 Preprocess DUT
Use packPixelAndControlBus.m function to pack the pixel and control bus data. The frm2pix object converts the input video frame to a pixel stream and pixelcontrol bus. Then, the R, G, B components of the pixel data and the hStart, hEnd, vStart, vEnd, and valid signals of the pixelcontrol bus are packed to generate 32 bit data, as shown.
inputImagePacked = packPixelAndControlBus(inputImage, frm2pix);

This packed input is fed to the YOLO v2 Preprocess DUT using the writePort function of fpga object. The input is preprocessed and written to the memory by the DUT. The deep learning IP core reads the data from memory, performs the vehicle detection, and writes the output back to the memory.
writePort(hFPGA, "InputData", inputImagePacked);
Read output data and perform postprocessing
The deep learning IP core returns handshaking signals indicating address, size, and validity of the output. When the outputValid signal becomes true, the script reads the processed output data frame using the outputAddr and outputSize signals. The readDataFromPLDDR.m function reads the output data using the readPort function of fpga object.
outputValid = readPort(hFPGA, "OutputValid"); while(outputValid~=1) pause(0.1); outputValid = readPort(hFPGA, "OutputValid"); end
outData = readDataFromPLDDR(hFPGA, ddrbaseAddr);
After reading the output data from DDR, pulse the OutputNext signal by using the hFPGA object
writePort(hFPGA, "OutputNext", 0); writePort(hFPGA, "OutputNext", 1); writePort(hFPGA, "OutputNext", 0);
The yolov2TransformLayerAndPostProcess.m function performs the transform layer processing and postprocessing on the outData, and returns the bounding boxes.
anchorBoxes = detector.AnchorBoxes; [bboxes, scores] = yolov2TransformLayerAndPostProcess(outData, inputImage, networkInputSize, networkOutputSize, anchorBoxes);
Verify postprocessed output
The bounding boxes obtained from the post-processing and the ground truth are overlaid on the input image along with the overlap ratio.
bboxesGT = inputDataTbl.vehicle{imIndex};
overlapRatio = bboxOverlapRatio(bboxes, bboxesGT);
bbOverlap = sprintf("Overlap with Ground Truth = %0.2f", overlapRatio); outputImage = insertObjectAnnotation(inputImage,'rectangle',bboxes,bbOverlap); outputImage = insertObjectAnnotation(outputImage,'rectangle',bboxesGT, '', 'Color', 'green'); imshow(outputImage);

Pulse inputStop signal
After processing all the frames, pulse the inputStop signal by using the hFPGA object.
writePort(hFPGA, "InputStop", 0); writePort(hFPGA, "InputStop", 1); writePort(hFPGA, "InputStop", 0);
Resource Information
T = table(... categorical({'LUT';'LUTRAM';'FF';'BRAM';'DSP';'IO';'BUFG';'MMCM';'PLL'}),... categorical({'204395 (74.57%)';'26211 (18.20%)';'224939 (41.03%)';'565 (61.95%)';'305 (12.10%)';'52 (15.85%)';'21 (5.19%)';'2 (50.0%)';'1 (12.5%)'}),... 'VariableNames',{'Resource','Utilization'})
T =
9×2 table
Resource Utilization
________ _______________
LUT 204395 (74.57%)
LUTRAM 26211 (18.20%)
FF 224939 (41.03%)
BRAM 565 (61.95%)
DSP 305 (12.10%)
IO 52 (15.85%)
BUFG 21 (5.19%)
MMCM 2 (50.0%)
PLL 1 (12.5%)
Conclusion
This example deployed the YOLO v2 vehicle detector application comprising of preprocessing steps (image resize and normalization) and handshaking logic on FPGA, performed vehicle detection, and verified the results using MATLAB.
For information about debugging the design deployed on the FPGA, see the Debug YOLO v2 Vehicle Detector on FPGA (Vision HDL Toolbox) example. This example shows how to use FPGA data capture and AXI manager features of the HDL Verifier™ product to capture the required data for debugging from the FPGA.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)