plotconfusion
(即将删除)绘制分类混淆矩阵
以后的版本中将会删除 plotconfusion。有关详细信息,请参阅Transition Legacy Neural Network Code to dlnetwork Workflows。
有关更新代码的建议,请参阅版本历史记录。
语法
说明
plotconfusion( 绘制真实标签 targets,outputs)targets 和预测标签 outputs 的混淆矩阵。将标签指定为分类向量,或以一对 N (one-hot) 形式指定。
提示
不推荐将 plotconfusion 用于分类标签。请改用 confusionchart。
在混淆矩阵图上,行对应于预测类(输出类),列对应于真实类(目标类)。对角线上的单元格对应于正确分类的观测值。非对角线上的单元格对应于未正确分类的观测值。每个单元格中都显示观测值数目和观测值数目占总观测值数目的百分比。
绘图最右侧的列显示预测属于正确分类和未正确分类的每个类的示例占所有示例的百分比。这些度量通常分别称为精确度(或正预测值)和假发现率。绘图底部的行显示属于正确分类和未正确分类的每个类的示例占所有示例的百分比。这些度量通常分别称为召回率(或真正率)和假负率。绘图右下角的单元格显示整体准确度。
plotconfusion(targets1,outputs1,name1,targets2,outputs2,name2,...,targetsn,outputsn,namen) 在一个图窗中绘制多个混淆矩阵,并将 name 参量添加到对应绘图标题的开头。
示例
加载由手写数字的合成图像组成的数据。XTrain 是一个 28×28×1×5000 图像数组,labelsTrain 是一个包含图像标签的分类向量。
load DigitsDataTrain
classNames = categories(labelsTrain);定义一个卷积神经网络的架构。
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
convolution2dLayer(3,16,'Padding','same','Stride',2)
batchNormalizationLayer
reluLayer
convolution2dLayer(3,32,'Padding','same','Stride',2)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];指定训练选项并训练网络。
options = trainingOptions('sgdm', ... 'MaxEpochs',5, ... 'Verbose',false, ... 'Plots','training-progress', ... 'Metrics','accuracy'); net = trainnet(XTrain,labelsTrain,layers,"crossentropy",options);
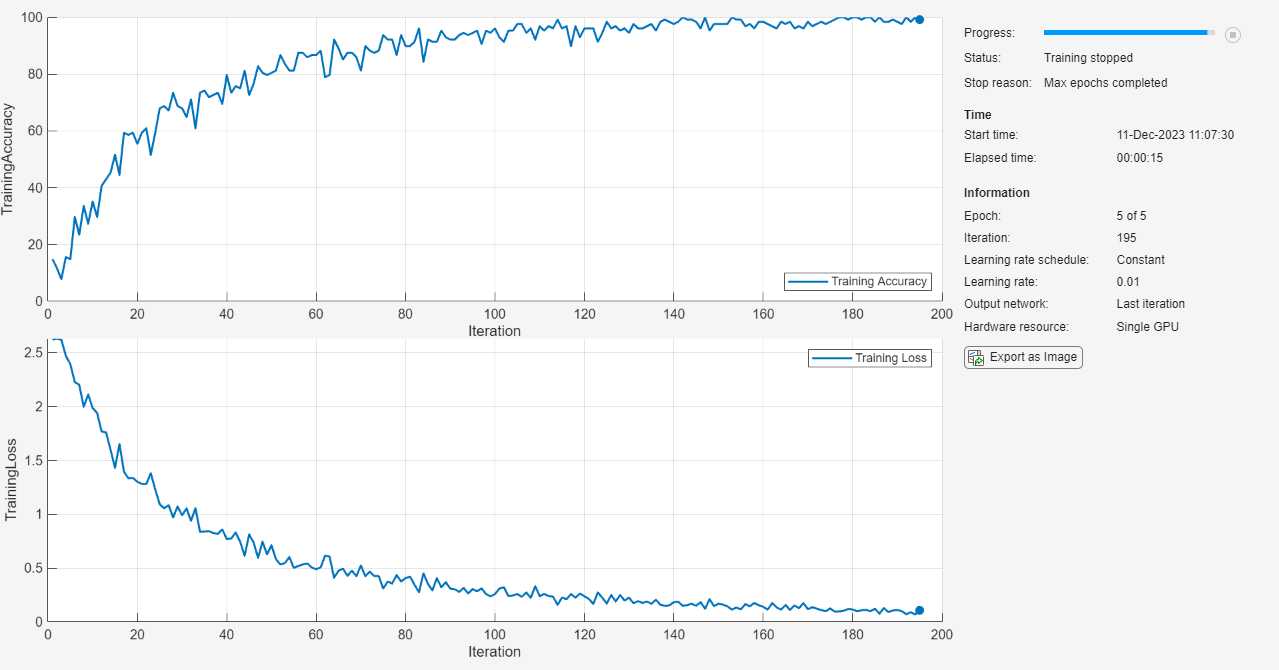
使用经过训练的网络加载测试数据并对其分类。
load DigitsDataTest
scores = minibatchpredict(net,XTest);
YTest = scores2label(scores,classNames);绘制由测试标签和预测标签组成的混淆矩阵。
plotconfusion(labelsTest,YTest)
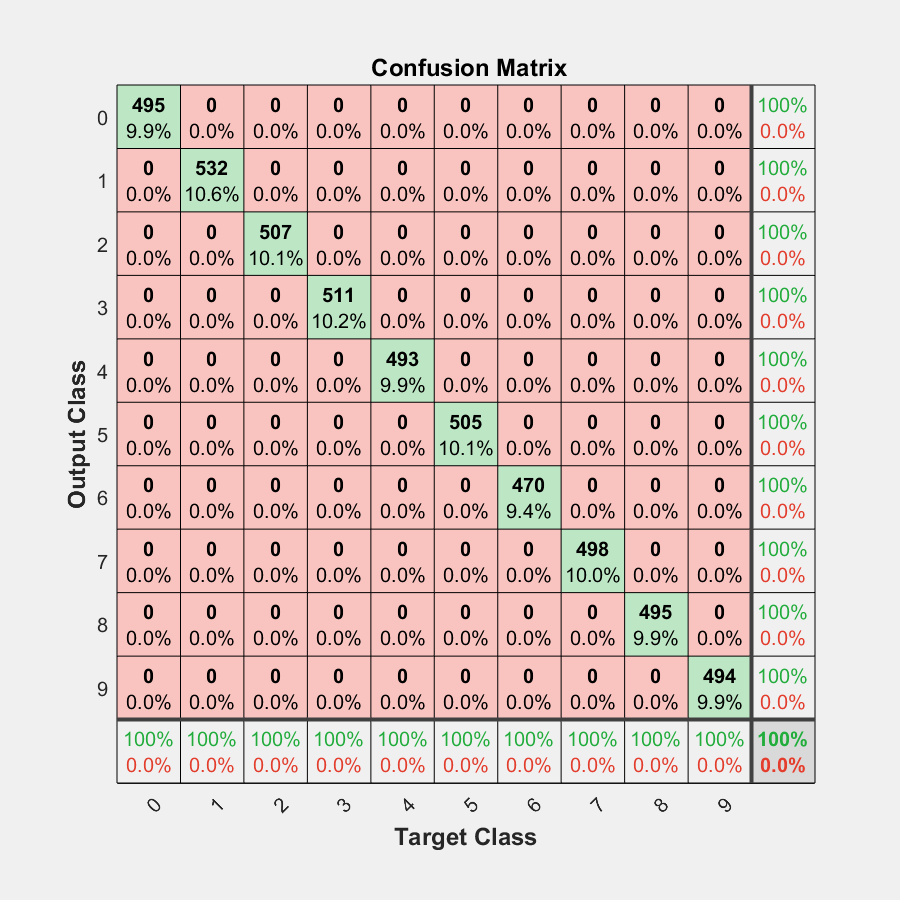
行对应于预测类(输出类),列对应于真实类(目标类)。对角线上的单元格对应于正确分类的观测值。非对角线上的单元格对应于未正确分类的观测值。每个单元格中都显示观测值数目和观测值数目占总观测值数目的百分比。
绘图最右侧的列显示预测属于正确分类和未正确分类的每个类的示例占所有示例的百分比。这些度量通常分别称为精确度(或正预测值)和假发现率。绘图底部的行显示属于正确分类和未正确分类的每个类的示例占所有示例的百分比。这些度量通常分别称为召回率(或真正率)和假负率。绘图右下角的单元格显示整体准确度。
关闭所有图窗。
close(findall(groot,'Type','figure'))
输入参数
版本历史记录
在 R2008a 中推出另请参阅
confusionchart | 时间序列建模器 | fitrnet (Statistics and Machine Learning Toolbox) | fitcnet (Statistics and Machine Learning Toolbox) | trainnet | trainingOptions | dlnetwork