训练残差网络进行图像分类
此示例说明如何创建包含残差连接的深度学习神经网络,并针对 CIFAR-10 数据对其进行训练。残差连接是卷积神经网络架构中的常见元素。使用残差连接可以改善网络中的梯度流,从而可以训练更深的网络。
对于许多应用来说,使用由一个简单的层序列组成的网络就已足够。但是,某些应用要求网络具有更复杂的层图结构,其中的层可接收来自多个层的输入,也可以输出到多个层。这些类型的网络通常称为有向无环图 (DAG) 网络。残差网络 (ResNet) 就是一种 DAG 网络,其中的残差(或快捷)连接会绕过主网络层。在 MATLAB 中,DAG 网络由 dlnetwork 对象表示。残差连接让参数梯度可以更轻松地从输出层传播到较浅的网络层,从而能够训练更深的网络。增加网络深度可在执行更困难的任务时获得更高的准确度。
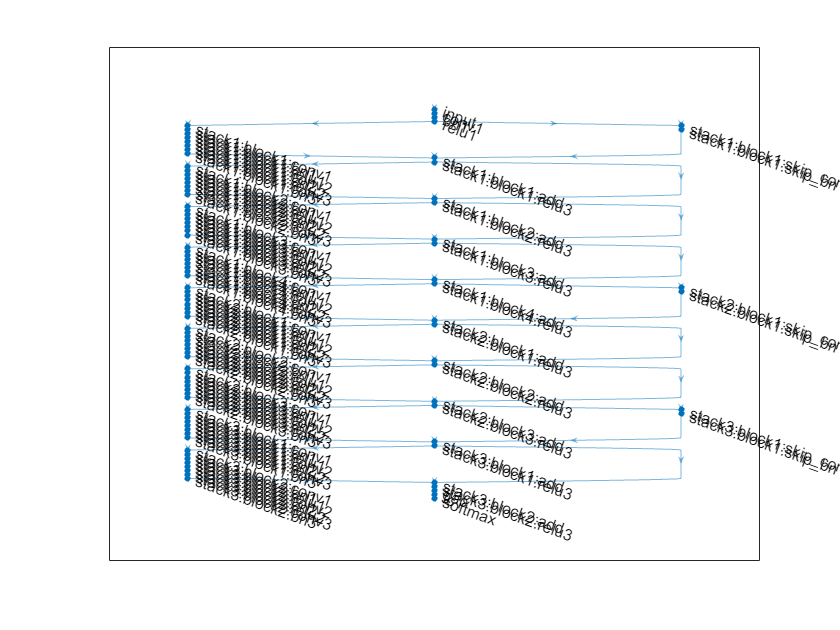
ResNet 架构由初始层、后跟包含残差块的堆栈以及最终层组成。有三种类型的残差块:
初始残差块 - 此块出现在第一个栈的开头。此示例使用瓶颈组件;因此,此块包含与下采样块相同的层,但仅在第一个卷积层中具有
[1,1]的步幅。有关详细信息,请参阅resnetNetwork。标准残差块 - 此块出现在每个栈中的第一个下采样残差块后。此块在每个栈中出现多次,并保留激活的维度大小。
下采样残差块 - 此块出现在每个栈的开头(第一个栈除外),并且在每个栈中只出现一次。下采样块中的第一个卷积单元会将空间维度下采样二分之一。
每个栈的深度可以不同,此示例训练具有三个深度递减的栈的残差网络。第一个栈的深度为 4,第二个栈的深度为 3,最后一个栈的深度为 2。

每个残差块都包含深度学习层。有关每个模块中各层的详细信息,请参阅 resnetNetwork。
要创建和训练适用于图像分类的残差网络,请执行以下步骤:
使用
resnetNetwork函数创建一个残差网络。使用
trainnet函数训练网络。经过训练的网络是一个dlnetwork对象。对新数据执行分类和预测。
您还可以加载预训练残差网络进行图像分类。有关详细信息,请参阅预训练的深度神经网络。
准备数据
下载 CIFAR-10 数据集 [1]。该数据集包含 60,000 个图像。每个图像为 32×32 像素大小,并且具有三个颜色通道 (RGB)。数据集的大小为 175 MB。根据您的 Internet 连接,下载过程可能需要一些时间。
datadir = tempdir; downloadCIFARData(datadir);
Downloading CIFAR-10 dataset (175 MB). This can take a while...done.
将 CIFAR-10 训练和测试图像作为四维数组加载。训练集包含 50,000 个图像,测试集包含 10,000 个图像。使用 CIFAR-10 测试图像进行网络验证。
[XTrain,TTrain,XValidation,TValidation] = loadCIFARData(datadir);
您可以使用以下代码显示训练图像的随机样本。
figure; idx = randperm(size(XTrain,4),20); im = imtile(XTrain(:,:,:,idx),ThumbnailSize=[96,96]); imshow(im)
创建一个 augmentedImageDatastore 对象以用于网络训练。在训练过程中,数据存储会沿垂直轴随机翻转训练图像,并在水平方向和垂直方向上将图像随机平移最多四个像素。数据增强有助于防止网络过拟合和记忆训练图像的具体细节。
imageSize = [32 32 3]; pixelRange = [-4 4]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(imageSize,XTrain,TTrain, ... DataAugmentation=imageAugmenter, ... OutputSizeMode="randcrop");
定义网络架构
使用 resnetNetwork 函数创建一个适用于此数据集的残差网络。
CIFAR-10 图像是 32×32 像素,因此,使用一个大小为 3 的初始滤波器和大小为 1 的初始步幅。将初始滤波器的数量设置为 16。
网络中的第一个栈以初始残差块开始。每个后续栈从下采样残差块开始。下采样分块中的第一个卷积单元以会将空间维度下采样二分之一。为了使整个网络中每个卷积层所需的计算量大致相同,每次执行空间下采样时,都将滤波器的数量增加一倍。将栈深度设置为
[4 3 2],将滤波器数量设置为[16 32 64]。
initialFilterSize = 3; numInitialFilters = 16; initialStride = 1; numFilters = [16 32 64]; stackDepth = [4 3 2];
创建一个二维残差网络。
net = resnetNetwork(imageSize,10, ... InitialFilterSize=initialFilterSize, ... InitialNumFilters=numInitialFilters, ... InitialStride=initialStride, ... InitialPoolingLayer="none", ... StackDepth=[4 3 2], ... NumFilters=[16 32 64]);
可视化网络。
plot(net);
训练选项
指定训练选项。对网络进行 80 轮训练。选择与小批量大小成正比的学习率,并在 60 轮训练后将学习率降低为原来的十分之一。每轮训练后都使用验证数据验证一次网络。
miniBatchSize = 128; learnRate = 0.1*miniBatchSize/128; valFrequency = floor(size(XTrain,4)/miniBatchSize); options = trainingOptions("sgdm", ... InitialLearnRate=learnRate, ... MaxEpochs=80, ... MiniBatchSize=miniBatchSize, ... VerboseFrequency=valFrequency, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationData={XValidation,TValidation}, ... ValidationFrequency=valFrequency, ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.1, ... LearnRateDropPeriod=60);
训练网络
要使用 trainnet 训练网络,请将 doTraining 标志设置为 true。对于分类,使用交叉熵损失。默认情况下,trainnet 函数使用 GPU(如果有)。在 GPU 上进行训练需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet 函数使用 CPU。要指定执行环境,请使用 ExecutionEnvironment 训练选项。
否则,请加载预训练的网络。
doTraining = false; if doTraining net = trainnet(augimdsTrain,net,'crossentropy',options); else load("trainedResidualNetwork.mat","net"); end

评估经过训练的网络
基于训练集(无数据增强)和验证集计算网络的最终准确度。要使用多个观测值进行预测,请使用 minibatchpredict 函数。要将预测分数转换为标签,请使用 scores2label 函数。minibatchpredict 函数自动使用 GPU(如果有)。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,该函数使用 CPU。
scores = minibatchpredict(net,XValidation); [YValPred,probs] = scores2label(scores,categories(TValidation)); validationError = mean(YValPred ~= TValidation); scores = minibatchpredict(net,XTrain); YTrainPred = scores2label(scores,categories(TTrain)); trainError = mean(YTrainPred ~= TTrain); disp("Training error: " + trainError*100 + "%")
Training error: 4.168%
disp("Validation error: " + validationError*100 + "%")
Validation error: 9.13%
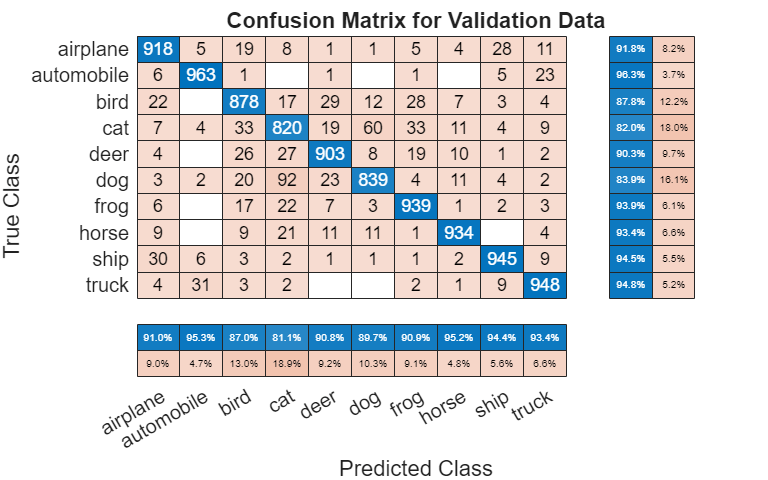
绘制混淆矩阵。使用列汇总和行汇总显示每个类的准确率和召回率。网络最常将猫与狗混淆。
figure(Units="normalized",Position=[0.2 0.2 0.4 0.4]); cm = confusionchart(TValidation,YValPred); cm.Title = "Confusion Matrix for Validation Data"; cm.ColumnSummary = "column-normalized"; cm.RowSummary = "row-normalized";
您可以使用以下代码显示包含九个测试图像的随机样本,以及它们的预测类和这些类的概率。
figure idx = randperm(size(XValidation,4),9); for i = 1:numel(idx) subplot(3,3,i) imshow(XValidation(:,:,:,idx(i))); prob = num2str(100*max(probs(idx(i),:)),3); predClass = char(YValPred(idx(i))); title([predClass + ", " + prob + "%"]) end
参考
[1] Krizhevsky, Alex. "Learning multiple layers of features from tiny images." (2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
另请参阅
trainnet | trainingOptions | dlnetwork | resnetNetwork | resnet3dNetwork | analyzeNetwork