使用深度学习检测噪声中的语音活动
在此示例中,您使用预训练的深度学习模型在低 SNR 环境中执行批量和流式语音活动检测 (VAD)。有关该模型及其训练方式的详细信息,请参阅Train Voice Activity Detection in Noise Model Using Deep Learning (Audio Toolbox)。
加载和检查数据
读入由单词组成的音频文件,单词之间有停顿,并收听该文件。使用 resample (Signal Processing Toolbox) 以 16 kHz 的采样率对信号进行重采样。对干净信号使用 detectSpeech (Audio Toolbox) 来确定真实值语音区域。
fs = 16e3; [speech,fileFs] = audioread("Counting-16-44p1-mono-15secs.wav"); speech = resample(speech,fs,fileFs); speech = speech./max(abs(speech)); sound(speech,fs) detectSpeech(speech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs))
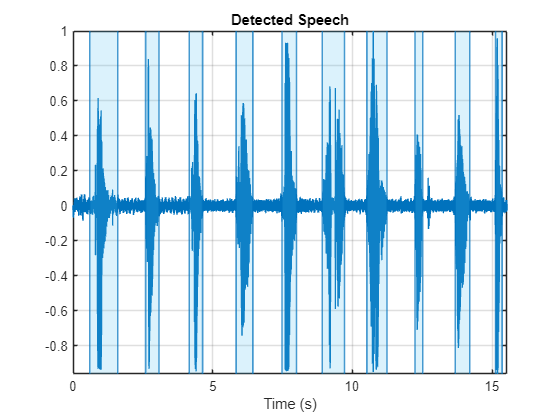
加载含噪信号并使用 resample (Signal Processing Toolbox) 以相同的音频采样率进行重采样。
[noise,fileFs] = audioread("WashingMachine-16-8-mono-200secs.mp3");
noise = resample(noise,fs,fileFs);使用支持函数 mixSNR 在所需的 SNR 水平 (dB) 下,用洗衣机噪声破坏干净的语音信号。收听损坏的音频。该网络在 -10 dB SNR 条件下进行了训练。
SNR =  -10;
noisySpeech = mixSNR(speech,noise,SNR);
sound(noisySpeech,fs)
-10;
noisySpeech = mixSNR(speech,noise,SNR);
sound(noisySpeech,fs)基于算法的 VAD detectSpeech (Audio Toolbox) 在这些含噪条件下失败。
detectSpeech(noisySpeech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs))
下载预训练网络
下载并加载一个预训练网络和一个已配置的 audioFeatureExtractor (Audio Toolbox) 对象。该网络经过训练,能够在低 SNR 环境中基于由 audioFeatureExtractor 对象输出的特征检测语音。
downloadFolder = matlab.internal.examples.downloadSupportFile("audio/examples","vadbilsmtnet.zip"); dataFolder = tempdir; netFolder = fullfile(dataFolder,"vadbilsmtnet"); unzip(downloadFolder,netFolder) pretrainedNetwork = load(fullfile(netFolder,"voiceActivityDetectionExample.mat")); afe = pretrainedNetwork.afe; net = pretrainedNetwork.speechDetectNet;
audioFeatureExtractor 对象配置为从包含 256 个采样的窗中提取特征,其中各窗之间有 128 个采样重叠。以 16 kHz 的采样率从 16 ms 的窗中提取特征,各窗之间有 8 ms 的重叠。audioFeatureExtractor 对象从每个窗中提取九个特征:频谱质心、频谱波峰、谱熵、频谱通量、谱峭度、频谱滚降点、频谱偏度、频谱斜率和谐波比。
afe
afe =
audioFeatureExtractor with properties:
Properties
Window: [256×1 double]
OverlapLength: 128
SampleRate: 16000
FFTLength: []
SpectralDescriptorInput: 'linearSpectrum'
FeatureVectorLength: 9
Enabled Features
spectralCentroid, spectralCrest, spectralEntropy, spectralFlux, spectralKurtosis, spectralRolloffPoint
spectralSkewness, spectralSlope, harmonicRatio
Disabled Features
linearSpectrum, melSpectrum, barkSpectrum, erbSpectrum, mfcc, mfccDelta
mfccDeltaDelta, gtcc, gtccDelta, gtccDeltaDelta, spectralDecrease, spectralFlatness
spectralSpread, pitch, zerocrossrate, shortTimeEnergy
To extract a feature, set the corresponding property to true.
For example, obj.mfcc = true, adds mfcc to the list of enabled features.
该网络由两个双向 LSTM 层(每个层有 200 个隐藏单元)和一个分类输出组成。如果没有检测到语音活动,该分类输出返回类 0;如果检测到语音活动,则返回类 1。
net.Layers
ans =
5×1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 9 channels
2 'biLSTM_1' BiLSTM BiLSTM with 200 hidden units
3 'biLSTM_2' BiLSTM BiLSTM with 200 hidden units
4 'fc' Fully Connected Fully connected layer with output size 2
5 'softmax' Softmax Softmax
执行语音活动检测
从语音数据中提取特征,然后将其标准化。调整特征方向,使时间跨列。
features = extract(afe,noisySpeech); features = (features - mean(features,1))./std(features,[],1); features = features';
使特征通过语音检测网络,以将每个特征向量分类为是否属于一个语音帧。
scores = predict(net,features.'); decisionsCategorical = scores2label(scores,categorical([0 1]));
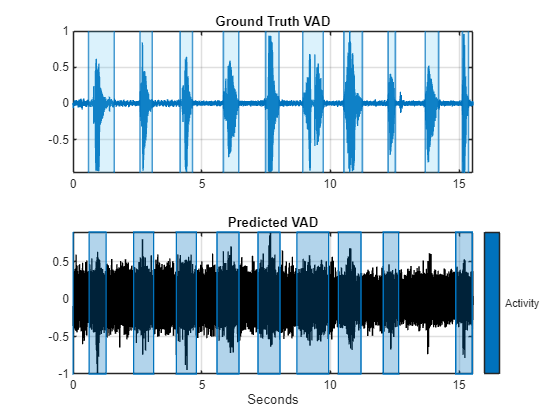
每个决策都对应一个由 audioFeatureExtractor (Audio Toolbox) 分析的分析窗口。复制决策,使它们与音频采样一一对应。使用不带输出参量的 detectSpeech (Audio Toolbox) 来绘制真实值。使用 signalMask (Signal Processing Toolbox) 和 plotsigroi (Signal Processing Toolbox) 绘制预测的 VAD。
decisions = (double(decisionsCategorical) - 1); decisionsPerSample = [decisions(1:round(numel(afe.Window)/2));repelem(decisions,numel(afe.Window)-afe.OverlapLength,1)]; tiledlayout(2,1) nexttile detectSpeech(speech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs)) title("Ground Truth VAD") xlabel("") nexttile mask = signalMask(decisionsPerSample,SampleRate=fs,Categories="Activity"); plotsigroi(mask,noisySpeech,true) title("Predicted VAD")
执行流式语音活动检测
audioFeatureExtractor (Audio Toolbox) 对象用于批处理,在各次调用之间不保留状态。使用 generateMATLABFunction (Audio Toolbox) 创建一个适合流式传输的特征提取器。您可以使用 classifyAndUpdateState 在流式环境中使用经过训练的 VAD 网络。
generateMATLABFunction(afe,"featureExtractor",IsStreaming=true)要模拟流式环境,请将语音和含噪信号保存为 WAV 文件。要模拟流式输入,您将使用 dsp.AudioFileReader (DSP System Toolbox) 从文件中读取帧,并以所需的 SNR 混合它们。您也可以使用 audioDeviceReader (Audio Toolbox) 让您的麦克风成为语音源。
audiowrite("Speech.wav",speech,fs) audiowrite("Noise.wav",noise,fs)
定义噪声演示中流语音活动检测的参数:
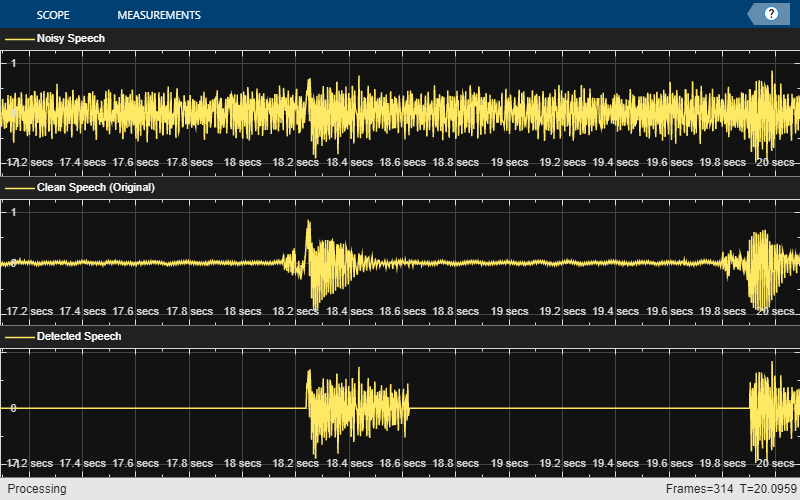
signal- 信号源,指定为先前录制的语音文件或您的麦克风。noise- 噪声源,指定为与信号混合的噪声声音文件。SNR- 混合信号和噪声的信噪比,以 dB 为单位指定。testDuration- 测试持续时间,以秒为单位指定。playbackSource- 回放源,指定为原始干净信号、含噪信号或检测到的语音。audioDeviceWriter(Audio Toolbox) 对象用于向您的扬声器播放音频。
signal ="Speech.wav"; noise = "Noise.wav"; SNR =
-10; % dB testDuration =
20; % seconds playbackSource =
"noisy";
调用支持函数 streamingDemo,观察 VAD 网络对流音频的性能。您使用实时控制设置的参数不会中断流示例。流式演示完成后,您可以修改演示的参数,然后再次运行流式演示。
streamingDemo(net,afe, ... signal,noise,SNR, ... testDuration,playbackSource);
参考资料
[1] Warden P."Speech Commands:A public dataset for single-word speech recognition", 2017.可从 https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz 获得。Copyright Google 2017.Speech Commands Dataset 是根据 Creative Commons Attribution 4.0 许可证授权的
支持函数
流式演示
function streamingDemo(net,afe,signal,noise,SNR,testDuration,playbackSource) % streamingDemo(net,afe,signal,noise,SNR,testDuration,playbackSource) runs % a real-time VAD demo. % Create dsp.AudioFileReader objects to read speech and noise files frame % by frame. If the speech signal is specified as Microphone, use an % audioDeviceReader as the source. if strcmpi(signal,"Microphone") speechReader = audioDeviceReader(afe.SampleRate); else speechReader = dsp.AudioFileReader(signal,PlayCount=inf); end noiseReader = dsp.AudioFileReader(noise,PlayCount=inf,SamplesPerFrame=speechReader.SamplesPerFrame); fs = speechReader.SampleRate; % Create a dsp.MovingStandardDeviation object and a dsp.MovingAverage % object. You will use these to determine the standard deviation and mean % of the audio features for standardization. The statistics should improve % over time. movSTD = dsp.MovingStandardDeviation(Method="Exponential weighting",ForgettingFactor=1); movMean = dsp.MovingAverage(Method="Exponential weighting",ForgettingFactor=1); % Create a dsp.MovingMaximum object. You will use it to standardize the % audio. movMax = dsp.MovingMaximum(SpecifyWindowLength=false); % Create a dsp.MovingRMS object. You will use this to determine the signal % and noise mix at the desired SNR. This object is only useful for example % purposes where you are artificially adding noise. movRMS = dsp.MovingRMS(Method="Exponential weighting",ForgettingFactor=1); % Create three dsp.AsyncBuffer objects. One to buffer the input audio, one % to buffer the extracted features, and one to buffer the output audio so % that VAD decisions correspond to the audio signal. The output buffer is % only necessary for visualizing the decisions in real time. audioInBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame); featureBuffer = dsp.AsyncBuffer(ceil(2*speechReader.SamplesPerFrame/(numel(afe.Window)-afe.OverlapLength))); audioOutBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame); % Create a time scope to visualize the original speech signal, the noisy % signal that the network is applied to, and the decision output from the % network. scope = timescope(SampleRate=fs, ... TimeSpanSource="property", ... TimeSpan=3, ... BufferLength=fs*3*3, ... TimeSpanOverrunAction="Scroll", ... AxesScaling="updates", ... MaximizeAxes="on", ... AxesScalingNumUpdates=20, ... NumInputPorts=3, ... LayoutDimensions=[3,1], ... ChannelNames=["Noisy Speech","Clean Speech (Original)","Detected Speech"], ... ... ActiveDisplay = 1, ... ShowGrid=true, ... ... ActiveDisplay = 2, ... ShowGrid=true, ... ... ActiveDisplay=3, ... ShowGrid=true); % Create an audioDeviceWriter object to play either the original or noisy % audio from your speakers. deviceWriter = audioDeviceWriter(SampleRate=fs); % Initialize variables used in the loop. windowLength = numel(afe.Window); hopLength = windowLength - afe.OverlapLength; % Run the streaming demonstration. loopTimer = tic; while toc(loopTimer) < testDuration % Read a frame of the speech signal and a frame of the noise signal speechIn = speechReader(); noiseIn = noiseReader(); % Mix the speech and noise at the specified SNR energy = movRMS([speechIn,noiseIn]); noiseGain = 10^(-SNR/20) * energy(end,1) / energy(end,2); noisyAudio = speechIn + noiseGain*noiseIn; % Update a running max to scale the audio myMax = movMax(abs(noisyAudio)); noisyAudio = noisyAudio/myMax(end); % Write the noisy audio and speech to buffers write(audioInBuffer,[noisyAudio,speechIn]); % If enough samples are in the audio buffer to calculate a feature % vector, read the samples, normalize them, extract the feature % vectors, and write the latest feature vector to the features buffer. while (audioInBuffer.NumUnreadSamples >= hopLength) x = read(audioInBuffer,numel(afe.Window),afe.OverlapLength); write(audioOutBuffer,x(end-hopLength+1:end,:)); noisyAudio = x(:,1); features = featureExtractor(noisyAudio); write(featureBuffer,features'); end if featureBuffer.NumUnreadSamples >= 1 % Read the audio data corresponding to the number of unread % feature vectors. audioHop = read(audioOutBuffer,featureBuffer.NumUnreadSamples*hopLength); % Read all unread feature vectors. features = read(featureBuffer); % Use only the new features to update the standard deviation and % mean. Normalize the features. rmean = movMean(features); rstd = movSTD(features); features = (features - rmean(end,:)) ./ rstd(end,:); % Network inference [score,state] = predict(net,features); net.State = state; [~,decision] = max(score,[],2); decision = decision-1; % Convert the decisions per feature vector to decisions per sample decision = repelem(decision,hopLength,1); % Apply a mask to the noisy speech for visualization vadResult = audioHop(:,1); vadResult(decision==0) = 0; % Listen to the speech or speech+noise switch playbackSource case "clean" deviceWriter(audioHop(:,2)); case "noisy" deviceWriter(audioHop(:,1)); case "detectedSpeech" deviceWriter(vadResult); end % Visualize the speech+noise, the original speech, and the voice % activity detection. scope(audioHop(:,1),audioHop(:,2),vadResult) end end end
混合 SNR
function [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) % [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) returns a noisy % version of the signal, noisySignal. The noisy signal has been mixed with % noise at the specified ratio in dB. numSamples = size(signal,1); % Convert noise to mono noise = mean(noise,2); % Trim or expand noise to match signal size if size(noise,1)>=numSamples % Choose a random starting index such that you still have numSamples % after indexing the noise. start = randi(size(noise,1) - numSamples + 1); noise = noise(start:start+numSamples-1); else numReps = ceil(numSamples/size(noise,1)); temp = repmat(noise,numReps,1); start = randi(size(temp,1) - numSamples - 1); noise = temp(start:start+numSamples-1); end signalNorm = norm(signal); noiseNorm = norm(noise); goalNoiseNorm = signalNorm/(10^(ratio/20)); factor = goalNoiseNorm/noiseNorm; requestedNoise = noise.*factor; noisySignal = signal + requestedNoise; noisySignal = noisySignal./max(abs(noisySignal)); end
另请参阅
vadnet (Audio Toolbox) | detectspeechnn (Audio Toolbox)