Model the United States Economy
This example describes the US economy by applying techniques of Smets-Wouters [11][12][13], but it uses a vector error-correction (VEC) model as a linear alternative to the Dynamic Stochastic General Equilibrium (DSGE) macroeconomic model. Like Smets and Wouters, this example models the same 7 response series: output (GDP), prices (GDP deflator), wages, hours worked, interest rates (Federal Funds), consumption, and investment.
Specifically, the example shows how to perform the following tasks using Econometrics Toolbox™ functionality:
Determine the cointegration rank using the suite of Johansen cointegration tests.
Specify the VEC model structure to fit to multivariate time series data.
Perform unconstrained and constrained estimation.
Perform an impulse response analysis to assess the sensitivity of the estimated model.
Iteratively compute minimum mean square error (MMSE), out-of-sample forecasts, as described in [13].
Determine the VEC model's ability to forecast the Fiscal Crisis of 2008.
Compare models fitted during the Great Inflation and Great Moderation periods in a counterfactual experiment.
Stress test the fitted models by computing conditional forecasts and performing conditional simulation.
Introduction
The Smets-Wouters model [11][12][13] is a nonlinear system of equations taking the form of a DSGE model. DSGE models attempt to explain aggregate economic behavior, such as growth, business cycles, and monetary and fiscal policy effects, using macroeconomic models derived from microeconomic principles. DSGE models are dynamic; they study how economies change over time. DSGE models are also stochastic; they account for the effects of random shocks including technological changes and price fluctuations.
Because DSGE models start from microeconomic principles of constrained decision-making, rather than relying on historical correlations, they are difficult to solve and analyze. However, because they are based on the preferences of economic agents, DSGE models offer a natural benchmark for evaluating the effects of policy change.
In contrast, traditional macroeconometric forecasting models, such as the cointegrated vector autoregression (VAR) model, or VEC model, estimate the relationships between variables in different sectors of the economy using historical data. Generally, they are easier to analyze and interpret. This descriptive macroeconomic model offers a nice starting point to examine the impact of various shocks to the United States economy, particularly around the period of the 2008 fiscal crisis.
Obtain Economic Data
The file Data_USEconVECModel.mat contains two timetables storing the economic series: FRED and CBO. FRED contains the sample to which the model is fit and was retrieved from the Federal Reserve Economic Database (FRED) [14] for periods 1957:Q1 (31-Mar-1957) through 2016:Q4 (31-Dec-2016).
CBO is from the Congressional Budget Office (CBO) [1] and contains 10-year economic projections for a subset of the FRED series. CBO is in the forecast horizon; this example uses observations therein for conditional forecasting and simulation beyond the latest FRED data.
This table lists the response series.
FRED Series | Description | Sample Frequency |
| Gross domestic product (USD billions) | quarterly |
| Gross domestic product implicit price deflator (index, where year 2009 = 100) | quarterly |
| Paid compensation of employees (USD billions) | quarterly |
| Nonfarm business sector hours of all persons (index, where year 2009 = 100) | quarterly |
| Effective federal funds rate (annualized, percent) | monthly |
| Personal consumption expenditures (USD billions) | quarterly |
| Gross private domestic investment (USD billions) | quarterly |
Load the data set.
load Data_USEconVECModelAlternatively, if you have a Datafeed Toolbox™ license, you can load, synchronize, and merge the latest economic data directly from FRED. To access the latest data from FRED, run the following command:
FRED = Example_USEconData;
The series are quarterly, seasonally adjusted, and start at the beginning of each quarter, except for Federal Funds, which is a monthly series. Because the GDP implicit price deflator is in the model, this example uses nominal series throughout.
For consistency with Smets and Wouters, this example synchronizes the FRED data to a quarterly periodicity using an end-of-quarter reporting convention. For example, FRED reports 2012:Q1 GDP dated 01-Jan-2012 and 2012:M3 Federal Funds dated 01-Mar-2012. When synchronized to a common end-of-quarter periodicity, both series are associated with 31-Mar-2012, the last day of the first quarter of 2012. For any given year YYYY, the data for Q1, Q2, Q3, and Q4 correspond to 31-Mar-YYYY, 30-Jun-YYYY, 30-Sep-YYYY, and 31-Dec-YYYY, respectively.
Transform Raw Data
Transform the series in FRED as in Smets and Wouters [13]:
Use the raw interest rate series
FEDFUNDS.Because the remaining series exhibit exponential growth, apply the log transform and scale the result by 100.
Retain the same series names for both raw and transformed data.
trnsfrmIdx = series ~= "FEDFUNDS"; Data = varfun(@(x)100*log(x),FRED,InputVariables=series(trnsfrmIdx)); Data.Properties.VariableNames = series(trnsfrmIdx); Data.FEDFUNDS = FRED.FEDFUNDS; numDims = width(Data); % Response dimensionality
Data is a timetable containing the transformed series and FEDFUNDS.
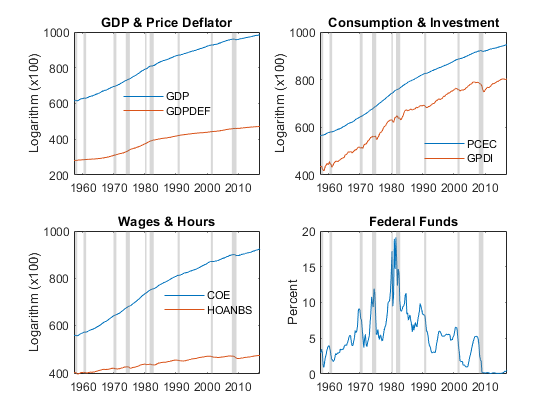
Plot each series in Data. Overlay shaded bands to identify periods of economic recession, as determined by the National Bureau of Economic Research (NBER) [9], by using the recessionplot function. recessionplot arbitrarily sets the middle of the month as the start or end date of a recession.
figure tiledlayout(2,2); nexttile; plot(Data.Time,[Data.GDP, Data.GDPDEF]) recessionplot title("GDP & Price Deflator") ylabel("Scaled Logarithm") h = legend("GDP","GDPDEF",Location="best"); h.Box = "off"; nexttile; plot(Data.Time,[Data.PCEC Data.GPDI]) recessionplot title("Consumption & Investment") ylabel("Scaled Logarithm") h = legend("PCEC","GPDI",Location="best"); h.Box = "off"; nexttile; plot(Data.Time,[Data.COE Data.HOANBS]) recessionplot title("Wages & Hours") ylabel("Scaled Logarithm") h = legend("COE","HOANBS",Location="best"); h.Box = "off"; nexttile; plot(Data.Time,Data.FEDFUNDS) recessionplot title("Federal Funds") ylabel("Percent")
Estimate VEC Model
This section begins with an overview of VEC model estimation. Then, the section shows how to do these tasks:
Choose appropriate values for non-estimable VEC model parameters. Non-estimable VEC model parameters include the lag length , the cointegrating rank , and the deterministic terms present in the model (Johansen parametric form). In practice, researchers consider several candidate models, compare them, and choose the best one. This section considers one candidate with a structure informed by literature and statistical rigor.
Fit the candidate model to the data.
VEC Model Estimation Overview
VEC model estimation proceeds in two steps:
Johansen Step – Estimate the cointegrating relations in a non-stationary, multivariate time series . Although the component series in might not be stationary, various linear combinations of them are stationary. The cointegrating rank is the number of independent linear combinations for which is stationary; is loosely interpreted as the number of long-run equilibrium relations in . The corresponding stationary linear combinations are the cointegrating relations.
VARX Step – Estimate a VARX model in differences using the cointegrating relations of the Johansen step as predictors. In other words, express the VEC(1) model as a VARX(1) model in differences, in which the cointegrating relations are predictors, , and the adjustment matrix is the corresponding regression coefficient. Symbolically,
This example imposes additional structure on the parameters of the VARX model by following this process:
Estimate an unrestricted VARX model to serve as a baseline model.
Determine and impose suitable constraints on the parameters of the VARX model, including the constant, regression coefficients, and autoregressive coefficients according to their statistical inference results.
The Johansen cointegration matrix estimated in the first step converges at a rate proportional to the sample size . Therefore, using the cointegrating relations obtained in the first step as predictors in the second step does not affect the distribution of the second step VARX parameter estimators. In contrast, the VARX parameters of the second step are asymptotically normally distributed and converge at the usual rate of . Therefore, you can interpret inferences in the usual way. This result helps determine suitable constraints on the parameters of the VARX model.
Choose Candidate VEC Model for Estimation
Candidate VEC models for a system vary in parametric form. The choice of an appropriate VEC model among of the candidates can incorporate personal experience and familiarity with the data, limited-scope analyses, industry best practice, regulatory mandates, and statistical rigor. Also, in-sample fit metrics, such as information criteria (for example, AIC or BIC, see aicbic or Information Criteria for Model Selection), and out-of-sample forecast performance (as emphasized in Smets and Wouters [13]) are data-driven methods for model specification. In practice, researchers include elements of all of these metrics in an iterative fashion.
To determine candidate VEC models for a system, choose reasonable settings for these model parameters:
Lag length . represents the number of presample responses needed to initialize the model, regardless of whether you view the responses in differences (VEC() form) or levels (VAR() form).
Cointegrating rank .
Cointegration model that best captures the deterministic terms of the data, for example, a linear trend.
Collectively, this procedure determines the cointegrating relations, which corresponding to the first step of the two-step VEC estimation method.
Lag length
In practice, researchers use a set of values for . This example adopts the guidance of Johansen [4], p. 4, and Juselius [5], p. 72, where lags are sufficient to describe the dynamic interactions between the series. The benefit of a low lag order is model simplicity, specifically, each additional lag of an unconstrained VEC model requires the estimation of an additional 7*7 = 49 parameters. Therefore, a low lag order mitigates the effects of over-parameterization, particularly when working with quarterly economic data whose sample size might be low relative to the number of parameters.
P = 2;
Cointegrating Rank and Cointegration Model Form
To determine the cointegrating rank of all series simultaneously, a cointegration model is required. Because the series clearly exhibit time trends, examine whether you can describe the data by either of two Johansen parametric forms that incorporate linear time trends: and (see Cointegration and Error Correction Analysis).
The model has a component of the overall constant both inside () and outside () the cointegrating relations, while only the cointegrating relations term has a time trend . Symbolically,
Because a component of the constant appears inside and outside the cointegrating relations, the overall constant () is unrestricted. The resulting model is
The VEC model is expressed in differences , therefore the unrestricted constant represents linear trends in the corresponding response levels .
The model also has an unrestricted model constant, but the cointegrating relations contain no time trend ( = 0). The model is a restricted parameterization of the model in that it imposes an additional restrictions on the parameters of an otherwise unrestricted model. This situation that can arise when the cointegrating relations drift along a common linear trend and the trend slope is the same for series with a linear trend. Symbolically,
The model emphasizes the unrestricted nature of the constant, symbolically,
Regardless of Johansen model, the responses are
with innovations
To determine , use the Johansen hypothesis testing function jcitest, which implements Johansen's trace test by default. By default, jcitest displays the test results in tabular form.
For each Johansen model, conduct a Johansen test. Supply the entire data set and set the number of lags to .
jmdl = ["H*" "H1"]; [h,pValue,stat,cValue,mleJT] = jcitest(Data,Lags=P-1,Model=jmdl);
************************ Results Summary (Test 1) Data: Data Effective sample size: 238 Model: H* Lags: 1 Statistic: trace Significance level: 0.05 r h stat cValue pValue eigVal ---------------------------------------- 0 1 266.1410 150.5530 0.0010 0.3470 1 1 164.7259 117.7103 0.0010 0.2217 2 1 105.0660 88.8042 0.0028 0.1665 3 0 61.7326 63.8766 0.0748 0.1323 4 0 27.9494 42.9154 0.6336 0.0446 5 0 17.0919 25.8723 0.4470 0.0379 6 0 7.9062 12.5174 0.2927 0.0327 ************************ Results Summary (Test 2) Data: Data Effective sample size: 238 Model: H1 Lags: 1 Statistic: trace Significance level: 0.05 r h stat cValue pValue eigVal ---------------------------------------- 0 1 261.9245 125.6176 0.0010 0.3460 1 1 160.8737 95.7541 0.0010 0.2212 2 1 101.3621 69.8187 0.0010 0.1661 3 1 58.1247 47.8564 0.0045 0.1323 4 0 24.3440 29.7976 0.1866 0.0446 5 0 13.4866 15.4948 0.0982 0.0340 6 1 5.2631 3.8415 0.0219 0.0219
h
h=2×11 table
r0 r1 r2 r3 r4 r5 r6 Model Lags Test Alpha
_____ _____ _____ _____ _____ _____ _____ ______ ____ _________ _____
t1 true true true false false false false {'H*'} 1 {'trace'} 0.05
t2 true true true true false false true {'H1'} 1 {'trace'} 0.05
pValue
pValue=2×11 table
r0 r1 r2 r3 r4 r5 r6 Model Lags Test Alpha
_____ _____ _________ _________ _______ ________ ________ ______ ____ _________ _____
t1 0.001 0.001 0.0027585 0.074778 0.63361 0.44705 0.2927 {'H*'} 1 {'trace'} 0.05
t2 0.001 0.001 0.001 0.0044644 0.1866 0.098186 0.021918 {'H1'} 1 {'trace'} 0.05
jcitest displays tables of statistical results for each test to the command line. Each output is a table with rows corresponding to each test and columns corresponding to the tested cointegration ranks 0 through and test options. For example, h contains logical decision indicators for each cointegrating rank:
1(true) indicates rejection of the null hypothesis that the model has cointegration rank of at most in favor of the alternative hypothesis that the model has cointegrating ranknumDims.0(false) indicates a failure to reject the null hypothesis.
The test results indicate that the test fails to reject a cointegrating rank of at the 5% significance level. At the 10% level, the test rejects a cointegrating rank of , but the test fails to reject a cointegrating rank of . By comparison, the test strongly fails to reject a cointegrating rank of at the 5% level. Therefore, a cointegrating rank of is a reasonable setting.
You can determine which of the two Johansen models better describes the data by conducting a likelihood ratio test using the lratiotest function. In the test, the model is the unrestricted model and the model is the restricted model with restrictions. The resulting test statistic is asymptotically (see [8] p. 342).
Conduct a likelihood ratio test by passing the loglikelihood values from the estimated and models for (stored in the rLL field of the structure arrays in mleJT) to lratiotest.
r = 4; uLogL = mleJT.r4(jmdl == "H*").rLL; rLogL = mleJT.r4(jmdl == "H1").rLL; [h,pValue,stat,cValue] = lratiotest(uLogL,rLogL,r)
h = logical
0
pValue = 0.9618
stat = 0.6111
cValue = 9.4877
The test fails to reject the restricted model.
Alternatively, you can use the jcontest function to perform a likelihood ratio test that tests the space spanned by the vectors in the cointegrating relations. The following test determines if you can impose a zero restriction (an exclusion constraint) on the trend coefficient of an model. Specifically, the test excludes a time trend in the cointegrating relations and imposes the restriction on the entire economic system. The test determines whether the restricted cointegrating vector lies in the stationarity space spanned by the cointegration matrix, see [6] pp. 175-178.
An model restricts the linear time trend to the cointegrating relations, and you can estimate one by adding an additional row to the cointegration matrix. Rewrite the model.
Format the constraint matrix such that
.
Conduct the test by using jcontest.
R = [zeros(1,width(Data)) 1]';
StatTbl = jcontest(Data,r,BCon=R,Model="H*",Lags=P-1)StatTbl=1×8 table
h pValue stat cValue Lags Alpha Model Test
_____ _______ _______ ______ ____ _____ ______ ________
Test 1 false 0.96183 0.61106 9.4877 1 0.05 {'H*'} {'bcon'}
The jcontest and lratiotest results are identical; the decisions fail to reject the restricted model.
In summary, the hypothesis test results suggest that the cointegrating rank is 4 and the model has the Johansen parametric form.
jmdl = "H1";Create VEC Model Candidate for Estimation
Specify the VEC model candidate by creating a vecm model object with properties that specify the chosen model. Pass the response variable dimensionality numDims, lag length and cointegrating rank to the vecm function. You specify the Johansen form when you operate on the model.
MdlBL = vecm(numDims,r,P-1);
Estimate VEC Model
Estimate a baseline model by passing the candidate model and entire data set to the estimate function. Specify the chosen Johansen model . To compute t statistics and use them to further constrain the tentatively estimated baseline VEC(1) model, return the standard errors of parameter estimates.
Y = Data.Variables; [EstMdlBL,se] = estimate(MdlBL,Y,Model=jmdl);
Because the VARX parameter estimators are asymptotically normally distributed, you can mitigate the effect of over-parameterization and improve out-of-sample forecasting performance by excluding (setting to zero) all VARX parameters that have a t statistic that is less than 2 in absolute value.
Create a VEC model of the same parametric form as the baseline model Mdl, but impose exclusion constraints on the VARX parameters of the second step which include the constant (), the short-run matrix (), and adjustment matrix (). Some references refer to exclusion constraints as subset restrictions, which are a special case of the type of individual constraints supported by VEC and VAR models.
Mdl = MdlBL;
Mdl.Constant(abs(EstMdlBL.Constant./se.Constant) < 2) = 0;
Mdl.ShortRun{1}(abs(EstMdlBL.ShortRun{1}./se.ShortRun{1}) < 2) = 0;
Mdl.Adjustment(abs(EstMdlBL.Adjustment./se.Adjustment) < 2) = 0;Fit the restricted model, and then plot the cointegrating relations of the final model for reference.
EstMdl = estimate(Mdl,Y,Model=jmdl);
B = [EstMdl.Cointegration ; EstMdl.CointegrationConstant' ; EstMdl.CointegrationTrend'];
figure
plot(Data.Time, [Y ones(size(Y,1),1) (-(EstMdl.P - 1):(size(Y,1) - EstMdl.P))'] * B)
recessionplot
title('Cointegrating Relations')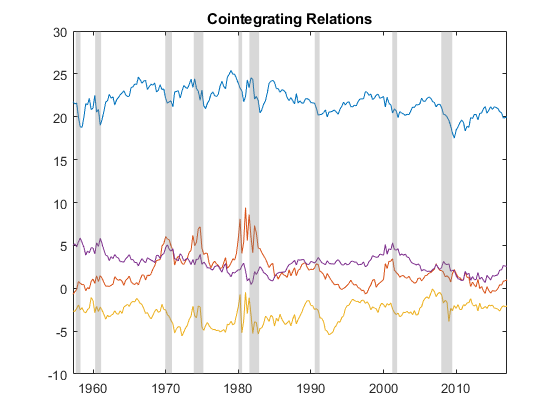
The plot suggests that the cointegrating relations are approximately stationary, although periods of volatility and abrupt change appear clustered around economic recessions.
Impulse Response Analysis
When economic conditions change, especially in response to a policy decision, you can assess the sensitivity of the system using an impulse response analysis.
The armairf function computes the impulse response function (IRF) of nominal GDP to a one-standard-deviation shock to each economic variable. By default, armairf displays the orthogonalized impulse response in which the residual covariance matrix is orthogonalized by its Cholesky factorization. Also, armairf supports the generalized impulse response of Pesaran and Shin [10], but for nominal GDP the results are similar in profile.
The armairf function returns the IRF in a 3-D array. Each page (the third dimension) captures the response of a specific variable, within the input forecast horizon fh, to a one-standard-deviation shock to all variables in the system. Specifically, element (t,j,k) is the response of variable k at time t in the forecast horizon, to an innovation shock to variable j at time 0. Columns and pages correspond to the response variables in the data, and t = 0, 1, ... fh.
Convert the fitted VEC model to its cointegrated VAR representation by using the varm conversion function. Then, compute the IRF for 40 quarters (10 years).
fh = 40;
VAR = varm(EstMdl);
IRF = armairf(VAR.AR,{},InnovCov=VAR.Covariance,NumObs=fh);
h = figure;
idxGDP = Data.Properties.VariableNames == "GDP";
tiledlayout(7,1);
for j = 1:EstMdl.NumSeries
nexttile;
plot(IRF(:,j,idxGDP))
title("GDP Impulse Response to " + Data.Properties.VariableNames(j))
end
h.Position(3:4) = [750 900];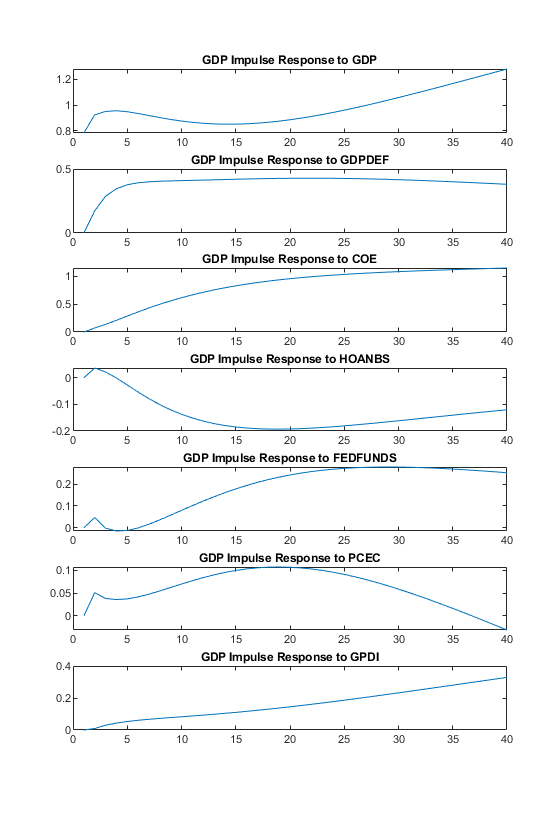
Although the plots display the impulse response over a span of 10 years, each response in fact approaches a steady-state asymptotic level indicating a unit root and suggesting that the shocks are persistent and have permanent effects on nominal GDP.
Compute Out-of-Sample Forecasts and Assess Forecast Accuracy
To assess the accuracy of the model, iteratively compute out-of-sample forecasts. Perform the following experiment, which is similar to the one in Smets and Wouters [13], pp. 21-22:
Estimate the VEC model over the initial 20-year sample period 1957:Q1 through 1976:Q4.
Forecast the data 1 through 4 quarters into the future. Store the forecasts for the current origin as a 3-D array, in which the first page stores all forecasts for the first series
GDP, the second page stores all forecasts for the second seriesGDPDEF, and so on. This storage convention facilitates the access of data from the output timetable of forecasts.Re-estimate the model over the period 1957:Q1 through 1977:Q1, but add the data of the next quarter to the sample, which increases the in-sample sample size.
Repeat steps 2 and 3, which accumulates a time series of forecasts until the end of the sample.
Y = Data; T0 = datetime(1976,12,31); % Forecast origin T = T0; fh = 4; % Forecast horizon in quarters numForecasts = numel(Y.Time(timerange(T,Y.Time(end),"closed"))) - fh; yForecast = nan(numForecasts,fh,EstMdl.NumSeries); for t = 1:numForecasts quarterlyDates = timerange(Y.Time(1),T,"closed"); % End-of-quarter dates for current forecast origin EstMdl = estimate(Mdl,Y{quarterlyDates,:},Model=jmdl); yForecast(t,:,:) = forecast(EstMdl, fh, Y{quarterlyDates,:}); T = dateshift(T,"end","quarter","next"); % Include data of next quarter end
Compute the forecast origin dates common to all forecasts in the forecast horizon and the specific quarterly dates, at which each of the forecasts applies. Then, create a timetable whose common time stamps (along each row) are the dates of each quarterly forecast origin. At each forecast origin, store the forecasts of each of the 7 series 1, 2, 3, and 4 quarters into the future, as well as the quarterly dates at which each forecast applies. This timetable format facilitates access to the forecasts of a given economic series.
originDates = dateshift(T0,"end","quarter",(0:(numForecasts-1))'); forecastDates = NaT(numForecasts,fh); % Preallocate forecast dates for j = 1:fh forecastDates(:,j) = dateshift(originDates,"end","quarter",j); end Forecast = timetable(forecastDates,RowTimes=originDates,VariableNames="Times"); for j = 1:numDims Forecast.(Y.Properties.VariableNames{j}) = yForecast(:,:,j); end
Using the iterative forecasts, assess the forecast accuracy of real GDP (nominal GDP net of the GDP price deflator) by plotting its forecasts and reported values at the forecast horizon. Plot the corresponding forecast errors.
forecastRealGDP = Forecast.GDP(:,4) - Forecast.GDPDEF(:,4); realGDP = Y.GDP(Forecast.Times(:,4)) - Y.GDPDEF(Forecast.Times(:,4)); figure tiledlayout(2,1) nexttile plot(Forecast.Times(:,4),forecastRealGDP,"r") hold on plot(Forecast.Times(:,4),realGDP,"b") title("Real GDP vs. Forecast: 4-Quarters-Ahead") ylabel("USD (billions)") recessionplot h = legend("Forecast","Actual",Location="best"); h.Box = "off"; nexttile plot(Forecast.Times(:,4),forecastRealGDP - realGDP) title("Real GDP Forecast Error: 4-Quarters-Ahead") ylabel("USD (billions)") recessionplot
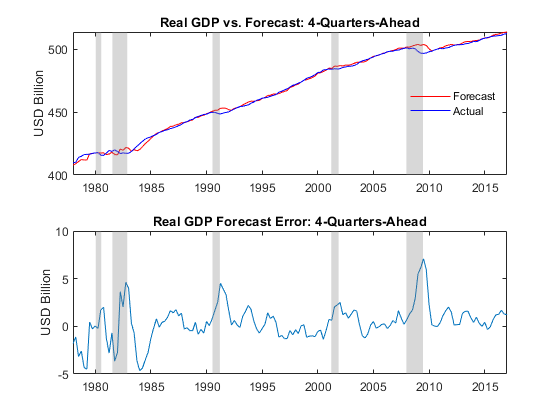
The plots suggest that during and shortly after periods of economic recession, the GDP forecasts tend to overestimate the true GDP. In particular, observe the large positive errors in the aftermath of the fiscal crisis of 2008 and into the first half of 2009.
For reference, although the plots do not show the forecast errors of the unconstrained VARX model without exclusion constraints imposed on the constant, short-run, and adjustment parameters, the constrained results in the plots represent approximately a 25 percent reduction in root mean square error (RMSE) of real GDP forecasts.
Analyze Fiscal Crisis of 2008 Using Real GDP Forecasts
This section investigates the forecasts in the vicinity of the 2008 fiscal crisis by contrasting forecast performance just before the crisis as the economy transitions into recession, and then again just after the crisis as the recovery ensues. As in Smets and Wouters [13], it uses a 12-quarter (3-year) forecast horizon, and it attempts to incorporate the forecasts of more than one series by examining real GDP.
Estimate and forecast real GDP 12 quarters into the future using data to the end of 2007, just before the mortgage crisis.
fh = 12;
T = datetime(2007,12,31);
EstMdl = estimate(Mdl, Y{timerange(Y.Time(1),T,"closed"),:},Model=jmdl);
[yForecast,yMSE] = forecast(EstMdl,fh,Y{timerange(Y.Time(1),T,"closed"),:});
sigma = zeros(fh,1); % Preallocate for forecast standard errors
for j = 1:fh
sigma(j) = sqrt(yMSE{j}(1,1) - 2*yMSE{j}(1,2) + yMSE{j}(2,2));
end
forecastDates = dateshift(T,"end","quarter",1:fh);
figure
plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) + sigma,"-.r")
hold on
plot(forecastDates,yForecast(:,1) - yForecast(:,2),"r")
plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) - sigma,"-.r")
plot(forecastDates,Y.GDP(forecastDates) - Y.GDPDEF(forecastDates),"b")
title("Real GDP vs. 12-Q Forecast: Origin = " + string(T))
ylabel("USD (billions")
recessionplot
h = legend("Forecast +1\sigma","Forecast","Forecast -1\sigma","Actual",Location="best");
h.Box = "off";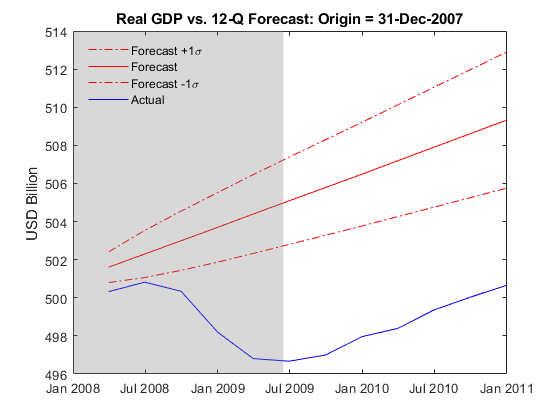
The estimated model fails to anticipate the dramatic economic downturn. Given the magnitude of the crisis, the model's failure to capture the extent of the recession is likely expected.
Estimate and forecast real GDP 12 quarters into the future using data up to the middle of 2009, which is just after the mortgage crisis.
T = datetime(2009,6,30);
EstMdl = estimate(Mdl,Y{timerange(Y.Time(1),T,"closed"),:},Model=jmdl);
[yForecast,yMSE] = forecast(EstMdl,fh,Y{timerange(Y.Time(1),T,"closed"),:});
sigma = zeros(fh,1);
for j = 1:fh
sigma(j) = sqrt(yMSE{j}(1,1) - 2*yMSE{j}(1,2) + yMSE{j}(2,2));
end
forecastDates = dateshift(T,"end","quarter",1:fh);
figure
plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) + sigma,"-.r")
hold on
plot(forecastDates,yForecast(:,1) - yForecast(:,2),"r")
plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) - sigma,"-.r")
plot(forecastDates,Y.GDP(forecastDates) - Y.GDPDEF(forecastDates),"b")
title("Real GDP vs. 12-Q Forecast: Origin = " + string(T))
ylabel("USD (billions)")
h = legend("Forecast +1\sigma","Forecast","Forecast -1\sigma","Actual",Location="best");
h.Box = "off";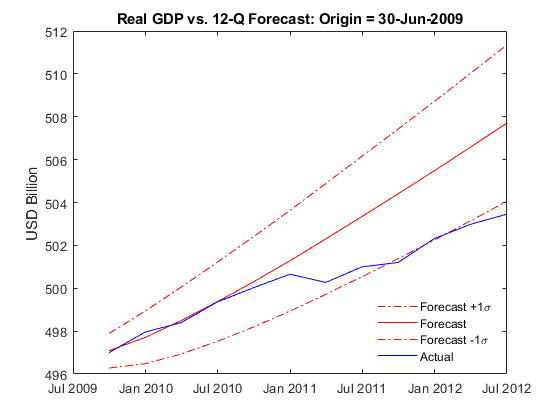
Once the model accounts for the recession data, the forecasts of real GDP agree reasonably well with the true values. However, beyond the 2-year forecast horizon, the forecasts suggest an optimistic economic recovery.
Incorporate the latest post-crisis data.
T = dateshift(Data.Time(end),"end","quarter",-fh); EstMdl = estimate(Mdl,Y{timerange(Y.Time(1),T,"closed"),:},Model=jmdl); [yForecast,yMSE] = forecast(EstMdl,fh,Y{timerange(Y.Time(1),T,"closed"),:}); sigma = zeros(fh,1); for j = 1:fh sigma(j) = sqrt(yMSE{j}(1,1) - 2*yMSE{j}(1,2) + yMSE{j}(2,2)); end forecastDates = dateshift(T,"end","quarter",1:fh); figure plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) + sigma,"-.r") hold on plot(forecastDates,yForecast(:,1) - yForecast(:,2),"r") plot(forecastDates,(yForecast(:,1) - yForecast(:,2)) - sigma,"-.r") plot(forecastDates,Y.GDP(forecastDates) - Y.GDPDEF(forecastDates),"b") title("Real GDP vs. 12-Q Forecast: Origin = " + string(T)) ylabel("USD (billions)") h = legend("Forecast +1\sigma","Forecast","Forecast -1\sigma","Actual",Location="best"); h.Box = "off";
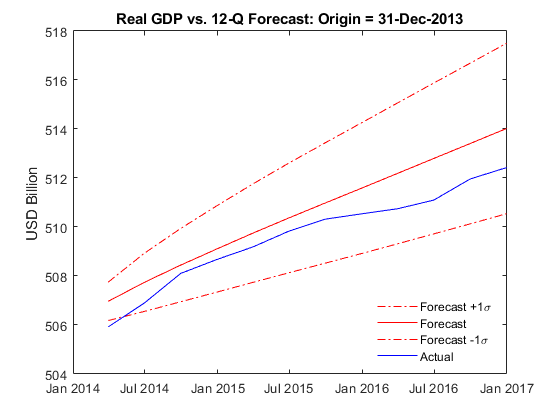
Because the latest data suggest that the recovery has gained some momentum and stabilized, the 3-year forecasts agree more closely with the true values.
Sub-Sample Sensitivity: The Great Inflation vs. the Great Moderation
To examine the stability and sensitivity of the analysis, compare the estimation results obtained from two distinct subsamples. Follow the approach in Smets and Wouters [13], pp. 28-29, by performing a what-if sensitivity analysis, referred to as a counterfactual experiment.
Smets and Wouters identify the period ending at 1979:Q2 with the appointment of Paul Volker as chairman of the Board of Governors of the Federal Reserve as the Great Inflation, and that starting 1984:Q1 as the Great Moderation. People consider the gap between the Great Inflation and the Great Moderation as a transition period, which includes the two recessions in the early 1980s. Consequently, Smets and Wouters examine the response of a model fitted to data over one period to shocks derived from a model fitted over another.
Estimate the VEC model over the period 1957:Q1 to 1979:Q2, and then again from 1984:Q1 to the latest quarter in the data. Although you can repeat the same pre-estimation model specification for the full sample to each sub-sample, for simplicity, use the same VEC model and subset constraints.
T1 = datetime(1979,6,30); % Last quarter of Great Inflation (30-Jun-1979 = (1979,6,30) triplet) Y1 = Y(timerange(Y.Time(1),T1,"closed"),:); % Great Inflation data [EstMdlGI,~,~,E1] = estimate(Mdl,Y1.Variables,Model=jmdl); T2 = datetime(1984,3,31); % First quarter of Great Moderation (31-Mar-1984 = (1984,3,31) triplet) Y2 = Y(timerange(T2,Y.Time(end),"closed"),:); % Great Moderation data EstMdlGM = estimate(Mdl,Y2.Variables,Model=jmdl);
Filter the inferred residuals from the first sub-sample fit (the Great Inflation) through the model from the latest sub-sample fit (the Great Moderation) using the filter function. To compare the filtered responses to the fitted results of the Great Moderation more accurately, initialize the filter using the first observations of the Great Moderation sub-sample. In other words, although the residuals inferred from the Great Inflation filter through the fitted model from the Great Moderation, you initialize the filter using data from the beginning of the Great Moderation.
YY = filter(EstMdlGM,E1,Y0=Y2{1:EstMdlGM.P,:},Scale=false);
Y2 = Y2((EstMdlGM.P + 1):(size(E1,1) + EstMdlGM.P),:);
YY = array2timetable(YY,RowTimes=Y2.Time,VariableNames=Y.Properties.VariableNames);Compare real GDP data reported during the Great Moderation to that obtained by filtering the shocks from the Great Inflation through the model fitted to the Great Moderation.
figure plot(YY.Time,Y2.GDP - Y2.GDPDEF,"b") hold on plot(YY.Time,YY.GDP - YY.GDPDEF,"r") title("Real GDP Sub-Sample Comparison") ylabel("USD (billions)") recessionplot h = legend("Reported Great Moderation Data","Filtered Great Inflation Residuals",Location="best"); h.Box = "off";
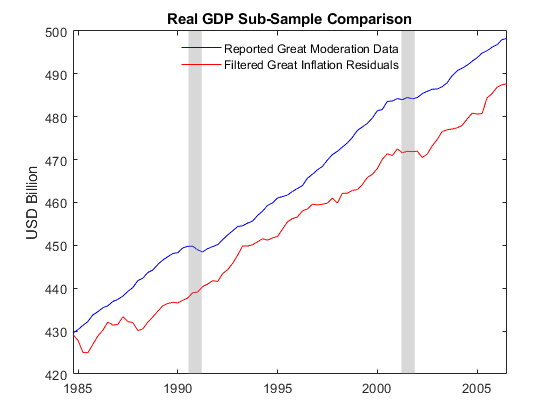
The plot suggests that the filtered results are more volatile than the reported Great Moderation data, as noted in Smets and Wouters [13], p. 30.
The filtering of the residuals from the Great Inflation model through the fitted Great Moderation model represents an alternative view of the economy within a broader historical simulation, filtering, and forecasting framework. For example, although the analysis in this example uses GDP, the analysis represents the other economic series in the data reasonably well, with the exception of short-term interest rates FEDFUNDS.
Within the Smets-Wouters model, interest rates are the only series left unadjusted, and Smets and Wouters include data only through the end of 2004, which is before the mortgage crisis. After 2004, short-term interest rates were already at low levels, but they approached zero at the end of 2008 as the fiscal crisis ensued and the recession began. Although the economy eventually recovered, interest rates remained at historically low levels for several years.
Given that VAR and VEC models are linear approximations of the true unknown vector process, whose dependence is captured by a multivariate Gaussian distribution, negative interest rates can occur. In fact, although short-term US interest rates have never been negative, other short-term interest-bearing accounts, especially in Europe, provided negative yields.
Conditional Forecasting & Simulation
Conditional analysis is closely related to stress testing. Specifically, values of a subset of variables are specified in advance, often subjected to adverse conditions or extreme values, to assess the effects on the remaining variables during periods of economic crisis. One approach to modeling economic time series in the presence of near-zero interest rates is to perform a conditional forecast and simulation using the model fitted to the Great Moderation to capture the latest data. Specifically, the analysis incorporates 10-year economic projections from the Congressional Budget Office (CBO) [1], which publishes quarterly forecasts for the following subset of the FRED series:
CBO Series | Description |
| Gross domestic product (USD billions) |
| Gross domestic product implicit price deflator (index, where year 2009 = 100) |
| Paid compensation of employees (USD billions) |
| Effective federal funds rate (annualized, percent) |
To obtain conditional forecasts, create a timetable where the CBO projections capture the future evolution of known data on which to condition unknown forecasts. NaN values indicate unknown (missing) forecasts conditioned on known (non-missing) information.
Transform the CBO series and store them in a new timetable that contains the subset of series known in advance and serves as the data on which you compute the remaining forecasts.
YF = varfun(@(x)100*log(x),CBO,InputVariables=series(trnsfrmIdx)); YF.Properties.VariableNames = series(trnsfrmIdx); YF.FEDFUNDS = CBO.FEDFUNDS;
Examine the last 4 quarterly CBO projections; hours worked, consumption, and investment are missing because the CBO does not publish projections for these series. The GDP, GDP deflator, compensation, and short-term interest rates contain the CBO projections.
YF(end-3:end,:)
ans=4×7 timetable
Time GDP GDPDEF COE HOANBS PCEC GPDI FEDFUNDS
___________ ______ ______ ______ ______ ____ ____ ________
31-Mar-2027 1023.5 492.1 963.14 NaN NaN NaN 2.8
30-Jun-2027 1024.4 492.6 964.07 NaN NaN NaN 2.8
30-Sep-2027 1025.4 493.09 964.99 NaN NaN NaN 2.8
31-Dec-2027 1026.3 493.59 965.89 NaN NaN NaN 2.8
Compare the forecasts of the CBO-projected real GDP to those obtained from the conditional forecasts of the VEC model by following this procedure:
Set the CBO projections of nominal GDP to
NaN, which indicates toforecasta lack of information regarding nominal GDP.Extract the quarterly CBO projections beyond the date of the most recent FRED data and forecast unknown series conditional on the projections.
Conditionally forecast nominal GDP from the VEC model by supplying the Great Moderation VEC model and timetable of known and unknown values in the forecast horizon to the
forecastfunction.
YF.GDP(:) = NaN;
forecastQuarters = timerange(Y.Time(end),CBO.Time(end),"openleft");
YF = YF(forecastQuarters,:);
yForecast = forecast(EstMdlGM,size(YF,1),Y.Variables,YF=YF.Variables);
yForecast = array2timetable(yForecast,RowTimes=YF.Time,VariableNames=Y.Properties.VariableNames);The forecast function converts the VEC model to its equivalent state-space representation, and derives the missing forecasts by using the standard Kalman filter. forecast replaces any missing values with filtered states computed as a minimum mean square error (MMSE) conditional expectation.
Inspect the results. Observe that forecast populates the missing GDP, HOANBS, PCEC, and GPDI series with their conditional forecasts. The GDPDEF, COE, and FEDFUNDS series used for conditioning are unchanged from the input forecast horizon data.
yForecast(end-3:end,:)
ans=4×7 timetable
Time GDP GDPDEF COE HOANBS PCEC GPDI FEDFUNDS
___________ ______ ______ ______ ______ ______ ______ ________
31-Mar-2027 1024.1 492.1 963.14 488.27 987.67 837.48 2.8
30-Jun-2027 1025 492.6 964.07 488.69 988.6 838.42 2.8
30-Sep-2027 1025.9 493.09 964.99 489.05 989.5 838.98 2.8
31-Dec-2027 1026.7 493.59 965.89 489.4 990.38 839.51 2.8
Compare conditionally forecasted real GDP to the CBO projections.
figure plot(YF.Time,100*log(CBO.GDP(forecastQuarters)) - YF.GDPDEF,"b") hold on plot(YF.Time,yForecast.GDP - yForecast.GDPDEF,"r") title("Real GDP Projection vs. Conditional Forecast") ylabel("USD (billions)") h = legend("CBO Real GDP Projection","Real GDP Conditional Forecast",Location="best"); h.Box = "off";
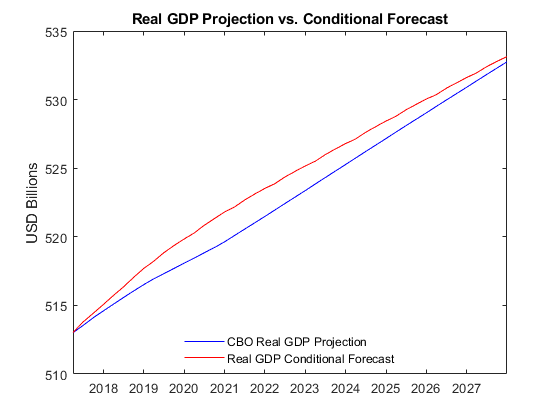
Like forecast, the simulate function supports conditional analyses, which enables you to conduct a Monte Carlo study in the forecast horizon. simulate samples from the conditional, multivariate Gaussian distribution to obtain random paths of innovations.
Simulate 1000 conditional response sample paths with the simulate function. Like forecast, simulate replaces NaNs in the input forecast horizon data with simulated responses.
rng(0,"twister");
YY = simulate(EstMdlGM,size(YF,1),Y0=Y.Variables,YF=YF.Variables,NumPaths=1000);Plot the first 10 sample paths of real GDP.
figure plot(YF.Time,squeeze(YY(:,1,1:10) - YY(:,2,1:10))) title("Real GDP Sample Paths") ylabel("USD (billions)")
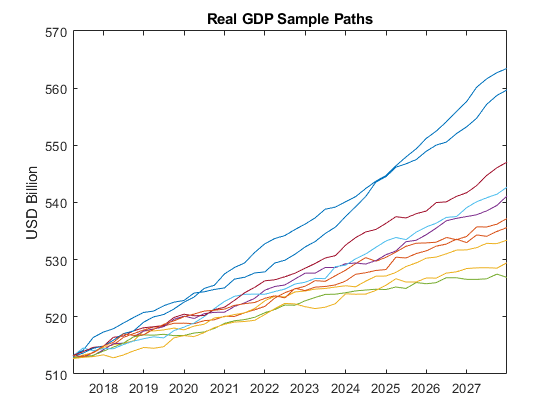
The plot suggests that the distribution of real GDP varies significantly as a function of time.
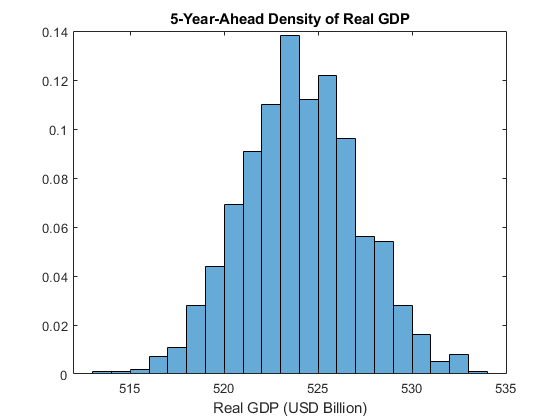
Plot the empirical probability density function (PDF) of real GDP 5 years (20 quarters) into the future.
YY = permute(squeeze(YY(20,:,:)),[2 1]); figure histogram(YY(:,1) - YY(:,2),"Normalization","pdf") xlabel("Real GDP (Billions of USD)") title("5-Year-Ahead Density of Real GDP")
See Also
Objects
Functions
Related Topics
References
[1] Congressional Budget Office, Budget and Economic Data, 10-Year
Economic Projections, https://www.cbo.gov/data/budget-economic-data.
[2] Del Negro, M., Schorfheide, F., Smets, F. and Wouters, R. "On the Fit of New Keynesian Models." Journal of Business & Economic Statistics. Vol. 25, No. 2, 2007, pp. 123–162.
[3] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
[4] Johansen, S. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press, 1995.
[5] Juselius, K. The Cointegrated VAR Model. Oxford: Oxford University Press, 2006.
[6] Kimball, M. "The Quantitative Analytics of the Basic Neomonetarist Model." Journal of Money, Credit, and Banking, Part 2: Liquidity, Monetary Policy, and Financial Intermediation. Vol. 27, No. 4, 1995, pp. 1241–1277.
[7] Lütkepohl, Helmut, and Markus Krätzig, editors. Applied Time Series Econometrics. 1st ed. Cambridge University Press, 2004. https://doi.org/10.1017/CBO9780511606885.
[8] Lütkepohl, Helmut. New Introduction to Multiple Time Series Analysis. New York, NY: Springer-Verlag, 2007.
[9] National Bureau of Economic Research (NBER), Business
Cycle Expansions and Contractions, https://www.nber.org/research/data/us-business-cycle-expansions-and-contractions.
[10] Pesaran, H. H., and Y. Shin. "Generalized Impulse Response Analysis in Linear Multivariate Models." Economic Letters. Vol. 58, 1998, pp. 17–29.
[11] Smets, F. and Wouters, R. "An Estimated Stochastic Dynamic General Equilibrium Model of the Euro Area." European Central Bank, Working Paper Series. No. 171, 2002.
[12] Smets, F. and Wouters, R. "Comparing Shocks and Frictions in US and Euro Area Business Cycles: A Bayesian DSGE Approach." European Central Bank, Working Paper Series. No. 391, 2004.
[13] Smets, F. and Wouters, R. "Shocks and Frictions in US Business Cycles: A Bayesian DSGE Approach." European Central Bank, Working Paper Series. No. 722, 2007.
[14] U.S. Federal Reserve Economic Data (FRED), Federal Reserve Bank of St. Louis, https://fred.stlouisfed.org/.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)