Numerical Equivalence Testing
Test numerical equivalence between model components and production code that you generate from the components by using GPU acceleration and processor-in-the-loop (PIL) simulations.
With a GPU acceleration simulation, you test source code on your development computer. With a PIL simulation, you test the compiled object code that you intend to deploy on a target hardware by running the object code on real target hardware. To determine whether model components and generated code are numerically equivalent, compare GPU acceleration and PIL results to normal mode results.
Target Connectivity Configuration for PIL
Before you can run PIL simulations, you must configure target connectivity. The target connectivity configuration enables the PIL simulation to:
Build the target application.
Download, start, and stop the application on the target.
Support communication between Simulink® and the target.
To produce a target connectivity configuration for hardware platforms such as NVIDIA DRIVE® and Jetson™, install the MATLAB® Coder™ Support Package for NVIDIA® Jetson and NVIDIA DRIVE Platforms.
Target Board Requirements
NVIDIA DRIVE or Jetson embedded platform.
Ethernet crossover cable to connect the target board and host PC (if you cannot connect the target board to a local network).
NVIDIA CUDA® Toolkit installed on the board.
Environment variables on the target for the compilers and libraries. For information on the supported versions of the compilers, libraries, and their setup, see Prerequisites for Generating Code for NVIDIA Boards.
Create Live Hardware Connection Object
The support package software uses an SSH connection over TCP/IP to execute commands while building and running the generated CUDA code on the DRIVE or Jetson platforms. Connect the target platform to the same network as the host computer or use an Ethernet crossover cable to connect the board directly to the host computer. For how to set up and configure your board, see NVIDIA documentation.
To communicate with the NVIDIA hardware, create a live hardware connection object by using the jetson or
drive
function. To create a live hardware connection object by using the function, provide the
host name or IP address, user name, and password of the target board. For example, to
create live object for Jetson hardware:
hwobj = jetson('192.168.1.15','ubuntu','ubuntu');
The software performs a check of the hardware, compiler tools, libraries, IO server installation, and gathers peripheral information on target. This information is displayed in the Command Window.
Checking for CUDA availability on the Target... Checking for NVCC in the target system path... Checking for CUDNN library availability on the Target... Checking for TensorRT library availability on the Target... Checking for Prerequisite libraries is now complete. Fetching hardware details... Fetching hardware details is now complete. Displaying details. Board name : NVIDIA Jetson TX2 CUDA Version : 9.0 cuDNN Version : 7.0 TensorRT Version : 3.0 Available Webcams : UVC Camera (046d:0809) Available GPUs : NVIDIA Tegra X2
Alternatively, to create live object for DRIVE hardware:
hwobj = drive('92.168.1.16','nvidia','nvidia');
Note
In case of a connection failure, a diagnostics error message is reported on the MATLAB command window. If the connection has failed, the most likely cause is incorrect IP address or host name.
Example: The Mandelbrot Set
Description
The Mandelbrot set is the region in the complex plane consisting of the values z0 for which the trajectories defined by this equation remain bounded at k→∞.
The overall geometry of the Mandelbrot set is shown in the figure. This view does not have the resolution to show the richly detailed structure of the fringe just outside the boundary of the set. At increasing magnifications, the Mandelbrot set exhibits an elaborate boundary that reveals progressively finer recursive detail.
Algorithm
For this tutorial, pick a set of limits that specify a highly zoomed part of the Mandelbrot set in the valley between the main cardioid and the p/q bulb to its left. A 1000-by-1000 grid of real parts (x) and imaginary parts (y) is created between these two limits. The Mandelbrot algorithm is then iterated at each grid location. An iteration number of 500 renders the image in full resolution.
maxIterations = 500; gridSize = 1000; xlim = [-0.748766713922161,-0.748766707771757]; ylim = [0.123640844894862,0.123640851045266];
This tutorial uses an implementation of the Mandelbrot set by using standard MATLAB commands running on the CPU. This calculation is vectorized such that every location is updated simultaneously.
GPU Acceleration or PIL Simulation with a Top Model
Test the generated model code by running a top-model PIL simulation. With this approach:
You test code generated from the top model, which uses the standalone code interface.
You configure the model to load test vectors or stimulus inputs from the MATLAB workspace.
You can easily switch the top model between the normal, GPU acceleration, and PIL simulation modes.
Create Mandelbrot Top Model
Create a Simulink model and insert a MATLAB Function block from the User-Defined Functions library.
Double-click the MATLAB Function block. A default function signature appears in the MATLAB Function Block Editor.
Define a function called
mandelbrot_count, which implements the Mandelbrot algorithm. The function header declaresmaxIterations,xGrid, andyGridas an argument to themandelbrot_countfunction, withcountas the return value.function count = mandelbrot_count(maxIterations, xGrid, yGrid) % mandelbrot computation z0 = complex(xGrid,yGrid); count = ones(size(z0)); % Map computation to GPU coder.gpu.kernelfun; z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs(z)<=2; count = count + inside; end count = log(count);
Open the block parameters for the MATLAB Function block. On the Code Generation tab, select
Reusable functionfor Function packaging parameter.If the Function packaging parameter is set to another value, CUDA kernels may not get generated.
Add Inport (Simulink) blocks and Outport (Simulink) block from the Sources and Sinks library.
Connect these blocks as shown in the diagram. Save the model as
mandelbrot_top.slx.
Configure the Model for GPU Acceleration
To focus on numerical equivalence testing, turn off:
Model coverage
Code coverage
Execution time profiling
model = 'mandelbrot_top'; close_system(model,0); open_system(model) set_param(gcs, 'RecordCoverage','off'); coverageSettings = get_param(model, 'CodeCoverageSettings'); coverageSettings.CoverageTool='None'; set_param(model, 'CodeCoverageSettings',coverageSettings); set_param(model, 'CodeExecutionProfiling','off');
Configure the input stimulus data. The following lines of code generate a 1000-by-1000
grid of real parts (x) and imaginary parts (y)
between the limits specified by xlim and
ylim.
gridSize = 1000; xlim = [-0.748766713922161, -0.748766707771757]; ylim = [ 0.123640844894862, 0.123640851045266]; x = linspace( xlim(1), xlim(2), gridSize ); y = linspace( ylim(1), ylim(2), gridSize ); [xG, yG] = meshgrid( x, y ); maxIterations = timeseries(500,0); xGrid = timeseries(xG,0); yGrid = timeseries(yG,0);
Configure logging options in the model.
set_param(model, 'LoadExternalInput','on'); set_param(model, 'ExternalInput','maxIterations, xGrid, yGrid'); set_param(model, 'SignalLogging', 'on'); set_param(model, 'SignalLoggingName', 'logsOut'); set_param(model, 'SaveOutput','on')
Run Normal and PIL Simulations
Run a normal mode simulation.
set_param(model,'SimulationMode','normal') set_param(model,'GPUAcceleration','on'); sim_output = sim(model,10); count_normal = sim_output.yout{1}.Values.Data(:,:,1);
Before running a top-model PIL simulation, configure the model to run on your hardware board. This code configures the model to run PIL on an NVIDIA Jetson board.
set_param(model,"HardwareBoard","NVIDIA Jetson"); set_param(model,"SimulationMode","Processor-in-the-Loop (PIL)") sim_output = sim(model,10); count_pil = sim_output.yout{1}.Values.Data(:,:,1);
### Unable to find Simulink cache file "mandelbrot_top.slxc". ### Searching for referenced models in model 'mandelbrot_top'. ### Total of 1 models to build. ### Starting build procedure for: mandelbrot_top ### Generating code and artifacts to 'Model specific' folder structure ### Generating code into build folder: C:\Users\user\folder\mandelbrot_top_ert_rtw ### Invoking Target Language Compiler on mandelbrot_top.rtw ### Using System Target File: ert.tlc ### Loading TLC function libraries ....... ### Initial pass through model to cache user defined code . ### Caching model source code ............................................... ### Writing header file mandelbrot_top_types.h ### Writing source file mandelbrot_top.c ### Writing header file mandelbrot_top_private.h ### Writing header file mandelbrot_top.h ### Writing header file rtwtypes.h . ### Writing header file rtGetNaN.h ### Writing source file rtGetNaN.c ### Writing header file rt_nonfinite.h ### Writing source file rt_nonfinite.c . ### Writing header file rtGetInf.h ### Writing source file rtGetInf.c ### Writing header file rtmodel.h ### Writing source file ert_main.c ### TLC code generation complete (took 4.882s). ### Saving binary information cache. ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\mandelbrot_top.mk' ... ### Building 'mandelbrot_top': make -f mandelbrot_top.mk -j4 buildobj ### Successful completion of build procedure for: mandelbrot_top ### Simulink cache artifacts for 'mandelbrot_top' were created in 'C:\Users\user\folder\mandelbrot_top.slxc'. Build Summary Top model targets: Model Build Reason Status Build Duration ================================================================================================================= mandelbrot_top Information cache folder or artifacts were missing. Code generated and compiled. 0h 0m 13.966s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 14.111s ### Connectivity configuration for component "mandelbrot_top": NVIDIA Jetson ### PIL execution is using Port 17725. PIL execution is using 30 Sec(s) for receive time-out. ### Preparing to start PIL simulation ... Building with 'Microsoft Visual C++ 2022 (C)'. MEX completed successfully. ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\coderassumptions\lib\mandelbrot_top_ca.mk' ... ### Building 'mandelbrot_top_ca': make -f mandelbrot_top_ca.mk -j4 all ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\pil\mandelbrot_top.mk' ... ### Building 'mandelbrot_top': make -f mandelbrot_top.mk -j4 all ### Starting application: 'mandelbrot_top_ert_rtw\pil\mandelbrot_top.elf' ### Launching application mandelbrot_top.elf...
Unless up-to-date code for this model exists, Simulink generates code for the PIL simulation. The generated code runs as a separate process on your computer.
Plot and compare the results of the normal and PIL simulations. Observe that the results match.
figure(); subplot(1,2,1) imagesc(x, y, count_normal); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set Normal Simulation'); axis off; subplot(1,2,2) imagesc(x, y, count_pil); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set PIL'); axis off;
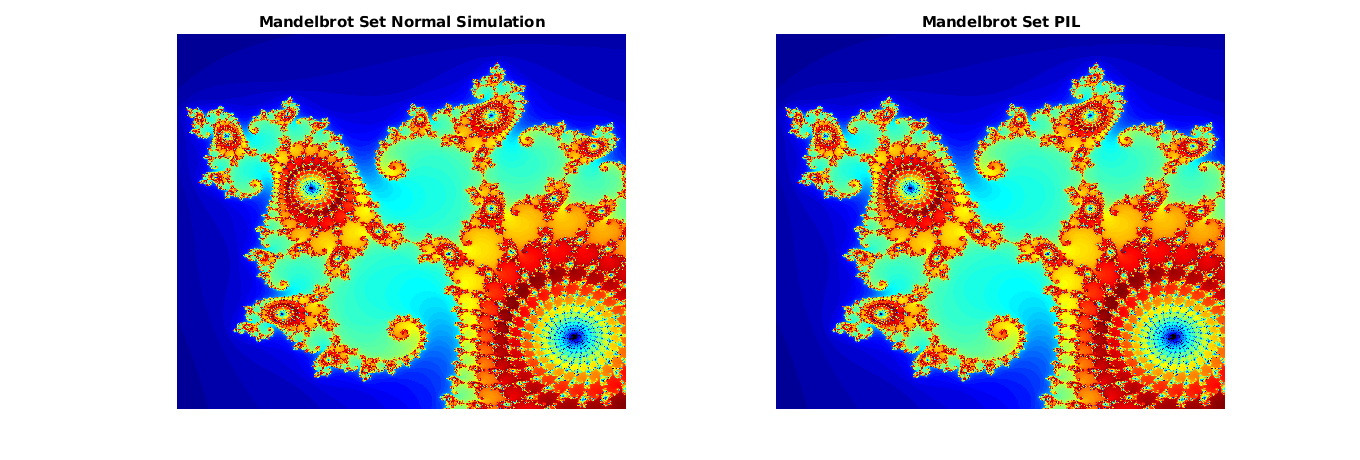
Clean up.
close_system(model,0); if ishandle(fig1), close(fig1), end clear fig1 simResults = {'count_sil','count_normal','model'}; save([model '_results'],simResults{:}); clear(simResults{:},'simResults')
Limitations
MAT file logging is not supported for Processor-in-the-loop (PIL) simulation with GPU Coder™.
See Also
Functions
open_system(Simulink) |load_system(Simulink) |save_system(Simulink) |close_system(Simulink) |bdclose(Simulink) |get_param(Simulink) |set_param(Simulink) |sim(Simulink) |slbuild(Simulink)
Topics
- Accelerate Simulation Speed by Using GPU Coder
- Code Generation from Simulink Models with GPU Coder
- GPU Code Generation for Deep Learning Networks Using MATLAB Function Block
- GPU Code Generation for Blocks from the Deep Neural Networks Library
- Targeting NVIDIA Embedded Boards
- Parameter Tuning and Signal Monitoring Using External Mode