使用一个预测变量的线性回归
简单线性回归描述单个预测变量和一个响应变量之间的关系。线性回归模型有助于理解预测变量的变化如何影响响应。
此示例说明如何使用 polyfit 和 polyval 函数拟合、可视化和验证不同阶数的简单线性回归模型。有关改用基本拟合工具拟合和可视化模型的信息,请参阅交互式拟合。
在以下情况下使用简单线性回归:
您有一个预测变量。
预测变量和响应之间的关系在系数上是线性的。
您需要量化预测变量对响应的影响。
对数据绘图
首先绘制数据以确定多项式拟合的可能阶数。
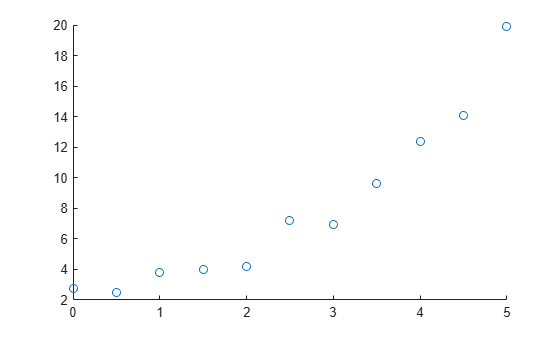
例如,创建并可视化一个样本预测变量 x 和一个样本响应变量 y。此可视化表明线性或二次拟合可能会描述预测变量和响应变量之间的关系。
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
拟合一阶模型
使用 polyfit 函数对数据进行一阶(线性)模型拟合。指定两个输出参量以返回多项式系数以及误差估计结构体。
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
显示拟合的模型。
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
拟合高阶模型
如果一阶模型不能充分描述预测变量和响应变量之间的关系,您可以拟合更高阶的模型。例如,使用 polyfit 函数对数据进行二阶(二次)模型拟合。指定两个输出参量以返回多项式系数以及误差估计结构体。
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
显示拟合的模型。
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
比较模型
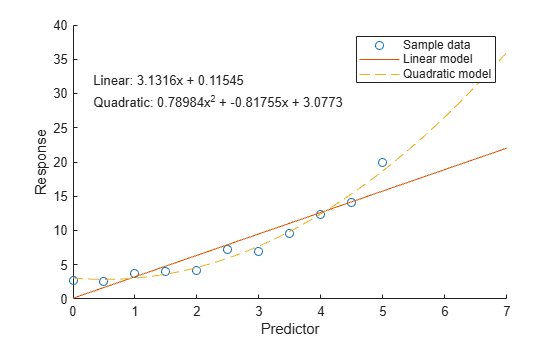
要使用一个绘图来比较模型,请先使用 polyval 函数在查询点处评估每个模型并返回预测的响应值。然后可视化数据和两个模型。
例如,在更精细的 x 值范围内获取线性模型和二次模型的响应值。
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
如果高阶模型无法很好地预测响应值,这可能表明出现过拟合。有关验证模型和选择适当模型复杂度的信息,请参阅验证模型部分。
然后绘制采样数据和模型数据。
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
验证模型
要验证模型,请计算决定系数(R 方)或调整后的决定系数(调整 R 方)。接近 1 的值表示拟合良好。
使用 R 方验证线性模型
对于一阶模型,您可以使用 polyfit 函数返回的误差估计结构体访问 R 方值。例如,查询 SLinear 中的 rsquared 字段。
linearR2 = SLinear.rsquared
linearR2 = 0.8715
使用调整 R 方验证高阶模型
对于具有更多项的高阶模型,R 方值通常会增大,表明对观测数据的拟合更接近。然而,这些模型具有更高的过拟合风险。
当模型对原始数据(包括噪声)的拟合过于紧密,导致无法很好地预测变量新数据时,就会发生过拟合。
为了平衡预测质量和模型复杂度,请考虑使用调整 R 方值来验证模型,该值包含对预测变量数目的罚分。您可以使用以下方程来计算调整 R 方值,其中 是误差估计结构体中 rsquared 字段的值, 是数据中的观测值数量, 是模型的阶数。
例如,计算二次模型的调整 R 方值。
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
计算每个模型的最大预测误差
您也可以通过计算模型预测与采样数据之间的最大误差来验证模型。相对于数据值而言,较小的最大误差表示拟合良好。
例如,计算线性模型和二次模型的最大误差。
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
另请参阅
函数
主题
- 交互式拟合
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- 创建并计算多项式
- Linear Regression Workflow (Statistics and Machine Learning Toolbox)
- Fit Polynomial Models (Curve Fitting Toolbox)