accumarray
累加向量元素
语法
说明
B = accumarray(ind,data)ind 中指定的组,通过对向量 data 的元素进行累加来对组数据求和。然后计算每组的总和。ind 中的值定义数据所属的组以及存储每个组总和的输出数组 B 的索引。
要按顺序返回组总和,请将 ind 指定为向量。然后,对于索引为 i 的组,accumarray 返回其在 B(i) 中的总和。例如,如果 ind = [1 1 2 2]' 和 data = [1 2 3 4]',则 B = accumarray(ind,data) 返回列向量 B = [3 7]'。
要以另一种形状返回组总和,请将 ind 指定为矩阵。对于 m×n 矩阵 ind,其中每一行的值表示指定的组和输出 B 的 n 维索引。例如,如果 ind 包含 [3 4] 形式的两行,则 data 中对应元素的总和存储在 B 的 (3,4) 元素中。
B 中未在 ind 中显示其索引的元素默认用 0 填充。
示例
输入参数
输出参量
详细信息
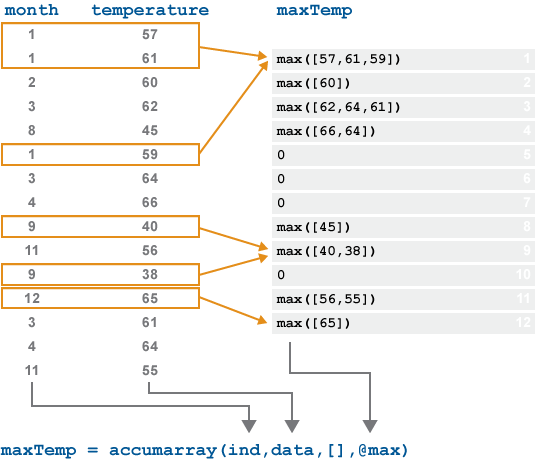
下图描述了 accumarray 作用于在 12 个月的时间段中获取的温度数据向量的行为。为了得出每个月的最大温度读数,accumarray 将 max 函数应用于在 month 中具有相同索引的 temperature 中的每组值。
month 中的值都不指向输出的 5、6、7 或 10 位置。默认情况下,这些索引处的输出 maxTemp 的元素是 0。
提示
accumarray的行为类似于函数groupsummary和groupcounts,后者分别用于按组计算摘要统计量和对组中的元素数进行计数。有关 MATLAB® 中的更多分组功能,请参阅数据预处理。accumarray的行为还与histcounts函数的行为类似。histcounts使用 bin 边界将连续值分组置入某个一维范围中。accumarray使用 n 维索引对数据进行分组。histcounts只能返回 bin 计数和 bin 位置。accumarray可以对数据应用任何函数。
您可以将
accumarray与data = 1结合使用来模拟histcounts的行为。sparse函数也具有与accumarray类似的累积行为。sparse使用二维索引对数据进行分组,而accumarray使用 n 维索引对数据进行分组。对于索引相同的元素,
sparse应用sum函数(对于double值)或any函数(对于logical值),并在输出矩阵中返回标量结果。accumarray默认求和,但可以将任何函数应用于数据。
扩展功能
版本历史记录
在 R2006a 之前推出