quantile
数据集的分位数
语法
说明
示例
输入参数
输出参量
详细信息
T-digest [2] 是一种概率数据结构体,它是数据集的经验累积分布函数 (CDF) 的稀疏表示。T-digest 可用于根据在线或分布式数据计算基于秩的统计量(例如百分位数和分位数)的逼近值,所采用的方式支持可控精度,特别是在数据分布的尾部附近。
对于分布在不同分区中的数据,T-digest 会单独计算每个数据分区的分位数估计值(和百分位数估计值),然后合并这些估计值,同时保持恒定的内存界限和恒定的计算相对精度(对于第 q 个分位数,为 )。由于这些原因,T-digest 在处理 tall 数组时非常实用。
要估计分布在不同分区中的数组的分位数,首先在数据的每个分区中构建一个 T-digest。T-digest 对分区中的数据进行聚类,并通过质心值和表示对聚类有贡献的样本数量的累积权重来汇总每个聚类。T-digest 使用大簇(质心间距大)表示 q = 0.5 附近的 CDF 区域,使用小簇(质心间距小)表示 q = 0 和 q = 1 附近的 CDF 区域。
T-digest 通过使用缩放函数控制簇大小,该函数使用压缩参数 δ 将分位数 q 映射到索引 k。即
,其中映射 k 呈单调形态,最小值为 k(0,δ) = 0,最大值为 k(1,δ) = δ。下图显示了 δ = 10 的缩放函数。
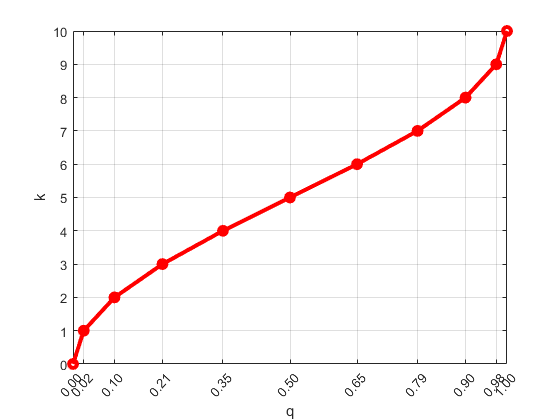
缩放函数将分位数 q 转换为缩放因子 k,以便在 q 中给出可变大小的步。因此,簇大小不相等(中心分位数附近的簇较大,q = 0 和 q = 1 附近的簇较小)。较小的簇使得数据边缘附近的准确度更高。
要用具有权重和位置的新观测值更新 T-digest,请找到距离新观测值最近的簇。然后,添加权重,并基于加权平均值更新簇质心,前提是更新后的簇权重不超过大小限制。
您可以合并来自每个数据分区的独立 T-digest,方法是对这些 T-digest 求并集,并合并其质心。要合并 T-digest,请首先对来自所有独立 T-digest 的簇按簇权重降序排序。然后,合并满足大小限制的相邻簇,以形成一个新 T-digest。
一旦形成表示完整数据集的 T-digest,就可以估计 T-digest 中每个簇的端点(或边界),然后使用每个簇的端点之间的插值来计算准确的分位数估计值。
算法
对于 n 元素向量 A,当您选择除 "approximate" 之外的任何方法时,quantile 函数使用基于排序的算法计算分位数。
A中的排序元素根据选定方法映射到分位数,如下表中所述。分位数 Method"midpoint"在 R2025a 之前的版本中:
"exact""inclusive"(自 R2025a 起)"exclusive"(自 R2025a 起)第一个排序元素的分位数 1/(2n) 0 1/(n+1) 第二个排序元素的分位数 3/(2n) 1/(n−1) 2/(n+1) 第三个排序元素的分位数 5/(2n) 2/(n−1) 3/(n+1) ... ... ... ... 第 k 个排序元素的分位数 (2k−1)/(2n) (k−1)/(n−1) k/(n+1) ... ... ... ... 第 (n−1) 个排序元素的分位数 (2n−3)/(2n) (n−2)/(n−1) (n−1)/(n+1) 第 n 个排序元素的分位数 (2n−1)/(2n) 1 n/(n+1) 例如,如果
A是[6 3 2 10 1],则分位数如下表所示。分位数 Method"midpoint"在 R2025a 之前的版本中:
"exact""inclusive"(自 R2025a 起)"exclusive"(自 R2025a 起)1的分位数1/10 0 1/6 2的分位数3/10 1/4 1/3 3的分位数1/2 1/2 1/2 6的分位数7/10 3/4 2/3 10的分位数9/10 1 5/6 quantile函数使用线性插值计算在A的第一个和最后一个排序元素的概率之间的概率下的分位数。有关详细信息,请参阅线性插值。例如,如果
A是[6 3 2 10 1],则:对于中点方法,第 0.4 个分位数是
2.5。在 R2025a 之前的版本中: 对于精确方法,第 0.4 个分位数是
2.5。对于包含方法,第 0.4 个分位数是
2.6。 (自 R2025a 起)对于排除方法,第 0.4 个分位数是
2.4。 (自 R2025a 起)
quantile函数将A中元素的最小值或最大值赋给该范围之外的概率对应的分位数。例如,如果
A是[6 3 2 10 1],则对于中点方法和排除方法,第 0.05 个分位数是1。 (自 R2025a 起)在 R2025a 之前的版本中: 例如,如果
A是[6 3 2 10 1],则对于精确方法,第 0.05 个分位数是1。
quantile 函数将 NaN 值视为缺失值并将其删除。
参考
[1] Langford, E. “Quartiles in Elementary Statistics”, Journal of Statistics Education. Vol. 14, No. 3, 2006.