anovan
N-way analysis of variance
Syntax
Description
p = anovan(y,group,Name,Value)Name,Value pair
arguments.
For example, you can specify which predictor variable is continuous, if any, or the type of sum of squares to use.
[ returns a p,tbl,stats]
= anovan(___)stats structure
that you can use to perform a multiple comparison test, which
enables you to determine which pairs of group means are significantly
different. You can perform such a test using the multcompare function by providing the stats structure
as input.
Examples
Load the sample data.
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]';
g1 = [1 2 1 2 1 2 1 2];
g2 = {'hi';'hi';'lo';'lo';'hi';'hi';'lo';'lo'};
g3 = {'may';'may';'may';'may';'june';'june';'june';'june'};y is the response vector and g1, g2, and g3 are the grouping variables (factors). Each factor has two levels, and every observation in y is identified by a combination of factor levels. For example, observation y(1) is associated with level 1 of factor g1, level 'hi' of factor g2, and level 'may' of factor g3. Similarly, observation y(6) is associated with level 2 of factor g1, level 'hi' of factor g2, and level 'june' of factor g3.
Test if the response is the same for all factor levels.
p = anovan(y,{g1,g2,g3})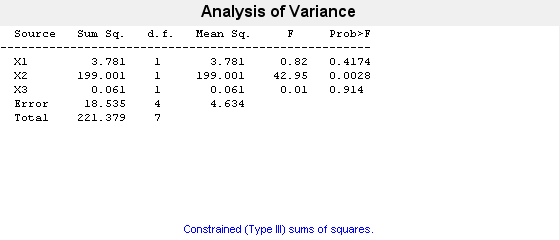
p = 3×1
0.4174
0.0028
0.9140
In the ANOVA table, X1, X2, and X3 correspond to the factors g1, g2, and g3, respectively. The p-value 0.4174 indicates that the mean responses for levels 1 and 2 of the factor g1 are not significantly different. Similarly, the p-value 0.914 indicates that the mean responses for levels 'may' and 'june', of the factor g3 are not significantly different. However, the p-value 0.0028 is small enough to conclude that the mean responses are significantly different for the two levels, 'hi' and 'lo' of the factor g2. By default, anovan computes p-values just for the three main effects.
Test the two-factor interactions. This time specify the variable names.
p = anovan(y,{g1 g2 g3},'model','interaction','varnames',{'g1','g2','g3'})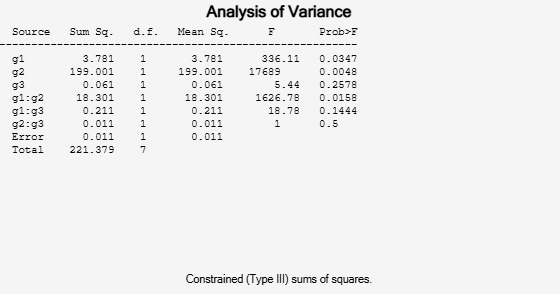
p = 6×1
0.0347
0.0048
0.2578
0.0158
0.1444
0.5000
The interaction terms are represented by g1*g2, g1*g3, and g2*g3 in the ANOVA table. The first three entries of p are the p-values for the main effects. The last three entries are the p-values for the two-way interactions. The p-value of 0.0158 indicates that the interaction between g1 and g2 is significant. The p-values of 0.1444 and 0.5 indicate that the corresponding interactions are not significant.
Load the sample data.
load carbigThe data has measurements on 406 cars. The variable org shows where the cars were made and when shows when in the year the cars were manufactured.
Study how the mileage depends on when and where the cars were made. Also include the two-way interactions in the model.
p = anovan(MPG,{org when},'model',2,'varnames',{'origin','mfg date'})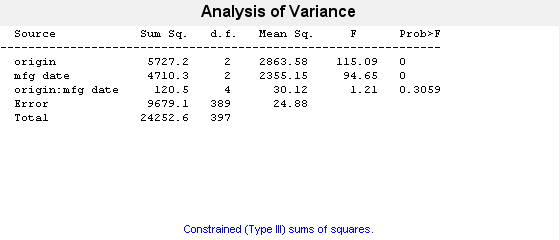
p = 3×1
0.0000
0.0000
0.3059
The 'model',2 name-value pair argument represents the two-way interactions. The p-value for the interaction term, 0.3059, is not small, indicating little evidence that the effect of the time of manufacture (mfg date) depends on where the car was made (origin). The main effects of origin and manufacturing date, however, are significant, both p-values are 0.
Load the sample data.
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]'; g1 = [1 2 1 2 1 2 1 2]; g2 = ["hi" "hi" "lo" "lo" "hi" "hi" "lo" "lo"]; g3 = ["may" "may" "may" "may" "june" "june" "june" "june"];
y is the response vector and g1, g2, and g3 are the grouping variables (factors). Each factor has two levels, and every observation in y is identified by a combination of factor levels. For example, observation y(1) is associated with level 1 of factor g1, level hi of factor g2, and level may of factor g3. Similarly, observation y(6) is associated with level 2 of factor g1, level hi of factor g2, and level june of factor g3.
Test if the response is the same for all factor levels. Also compute the statistics required for multiple comparison tests.
[~,~,stats] = anovan(y,{g1 g2 g3},"Model","interaction", ...
"Varnames",["g1","g2","g3"]);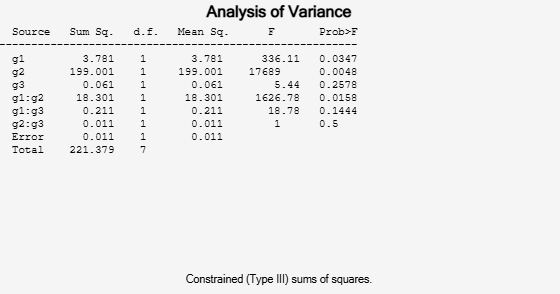
The p-value of 0.2578 indicates that the mean responses for levels may and june of factor g3 are not significantly different. The p-value of 0.0347 indicates that the mean responses for levels 1 and 2 of factor g1 are significantly different. Similarly, the p-value of 0.0048 indicates that the mean responses for levels hi and lo of factor g2 are significantly different.
Perform a multiple comparison test to find out which groups of factors g1 and g2 are significantly different.
[results,~,~,gnames] = multcompare(stats,"Dimension",[1 2]);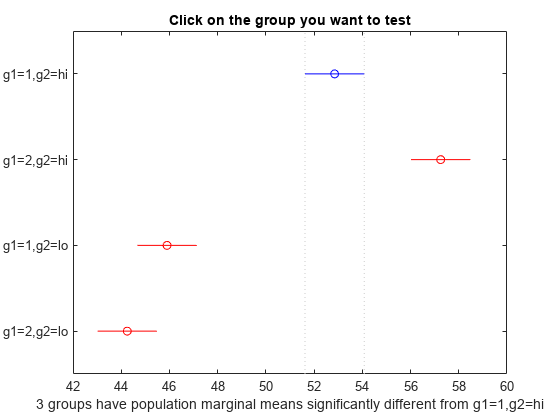
You can test the other groups by clicking on the corresponding comparison interval for the group. The bar you click on turns to blue. The bars for the groups that are significantly different are red. The bars for the groups that are not significantly different are gray. For example, if you click on the comparison interval for the combination of level 1 of g1 and level lo of g2, the comparison interval for the combination of level 2 of g1 and level lo of g2 overlaps, and is therefore gray. Conversely, the other comparison intervals are red, indicating significant difference.
Display the multiple comparison results and the corresponding group names in a table.
tbl = array2table(results,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"]); tbl.("Group A")=gnames(tbl.("Group A")); tbl.("Group B")=gnames(tbl.("Group B"))
tbl=6×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
______________ ______________ ___________ _____ ___________ _________
{'g1=1,g2=hi'} {'g1=2,g2=hi'} -6.8604 -4.4 -1.9396 0.027249
{'g1=1,g2=hi'} {'g1=1,g2=lo'} 4.4896 6.95 9.4104 0.016983
{'g1=1,g2=hi'} {'g1=2,g2=lo'} 6.1396 8.6 11.06 0.013586
{'g1=2,g2=hi'} {'g1=1,g2=lo'} 8.8896 11.35 13.81 0.010114
{'g1=2,g2=hi'} {'g1=2,g2=lo'} 10.54 13 15.46 0.0087375
{'g1=1,g2=lo'} {'g1=2,g2=lo'} -0.8104 1.65 4.1104 0.07375
The multcompare function compares the combinations of groups (levels) of the two grouping variables, g1 and g2. For example, the first row of the matrix shows that the combination of level 1 of g1 and level hi of g2 has the same mean response values as the combination of level 2 of g1 and level hi of g2. The p-value corresponding to this test is 0.0272, which indicates that the mean responses are significantly different. You can also see this result in the figure. The blue bar shows the comparison interval for the mean response for the combination of level 1 of g1 and level hi of g2. The red bars are the comparison intervals for the mean response for other group combinations. None of the red bars overlap with the blue bar, which means the mean response for the combination of level 1 of g1 and level hi of g2 is significantly different from the mean response for other group combinations.
Input Arguments
Name-Value Arguments
Output Arguments
Alternative Functionality
Instead of using anovan, you can create an anova
object by using the anova function.
The anova function provides these advantages:
The
anovafunction allows you to specify the ANOVA model type, sum of squares type, and factors to treat as categorical.anovaalso supports table predictor and response input arguments.In addition to the outputs returned by
anovan, the properties of theanovaobject contain the following:ANOVA model formula
Fitted ANOVA model coefficients
Residuals
Factors and response data
The
anovaobject functions allow you to conduct further analysis after fitting theanovaobject. For example, you can create an interactive plot of multiple comparisons of means for the ANOVA, get the mean response estimates for each value of a factor, and calculate the variance component estimates.
References
[1] Dunn, O.J., and V.A. Clark. Applied Statistics: Analysis of Variance and Regression. New York: Wiley, 1974.
[2] Goodnight, J.H., and F.M. Speed. Computing Expected Mean Squares. Cary, NC: SAS Institute, 1978.
[3] Seber, G. A. F., and A. J. Lee. Linear Regression Analysis. 2nd ed. Hoboken, NJ: Wiley-Interscience, 2003.
Version History
Introduced before R2006a