kstest
单样本柯尔莫哥洛夫-斯米尔诺夫检验
说明
h = kstest(x)x 中的数据来自标准正态分布,而不支持来自非标准正态分布这一备择假设。如果检验在 5% 的显著性水平上拒绝原假设,则结果 h 为 1,否则为 0。
h = kstest(x,Name,Value)
示例
使用 kstest 执行单样本科尔莫戈洛夫-斯米尔诺夫检验。通过以可视方式比较经验累积分布函数 (cdf) 和标准正态 cdf 来确认检验决策。
加载 examgrades 数据集。创建包含考试成绩数据的第一列的向量。
load examgrades
test1 = grades(:,1);检验数据来自均值为 75、标准差为 10 的正态分布的原假设。使用这些参数来中心化并缩放数据向量的每个元素,因为 kstest 默认情况下检验标准正态分布。
x = (test1-75)/10; h = kstest(x)
h = logical
0
返回值 h = 0 表明 kstest 在默认的 5% 显著性水平上未能拒绝原假设。
绘制经验 cdf 和标准正态 cdf,以便进行直观比较。
cdfplot(x) hold on x_values = linspace(min(x),max(x)); plot(x_values,normcdf(x_values,0,1),'r-') legend('Empirical CDF','Standard Normal CDF','Location','best')
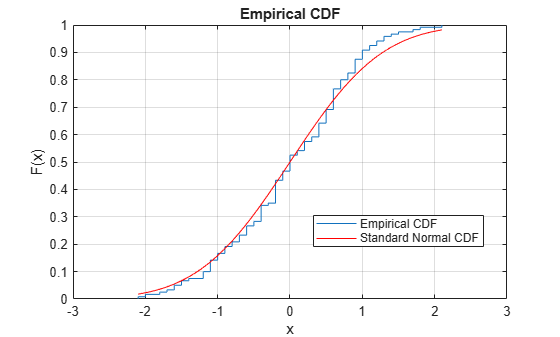
图窗显示中心化并缩放的数据向量的经验 cdf 与标准正态分布的 cdf 之间的相似性。
加载样本数据。创建包含学生考试成绩数据的第一列的向量。
load examgrades;
x = grades(:,1);将假设分布指定为一个两列矩阵。第 1 列含数据向量 x。第 2 列包含在假设的 Student 分布的 x 中的每个值处计算的 cdf 值,位置参数为 75,尺度参数为 10,自由度为 1。
test_cdf = [x,cdf('tlocationscale',x,75,10,1)];检验数据是否来自假设的分布。
h = kstest(x,'CDF',test_cdf)h = logical
1
返回值 h = 1 表明 kstest 在默认的 5% 显著性水平上拒绝了原假设。
加载样本数据。创建包含学生考试成绩数据的第一列的向量。
load examgrades;
x = grades(:,1);创建一个概率分布对象来检验数据是否来自某 Student 分布,其位置参数为 75,尺度参数为 10,自由度为 1。
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
检验原假设,即数据来自假设分布。
h = kstest(x,'CDF',test_cdf)h = logical
1
返回值 h = 1 表明 kstest 在默认的 5% 显著性水平上拒绝了原假设。
加载样本数据。创建包含学生考试成绩的第一列的向量。
load examgrades;
x = grades(:,1);创建一个概率分布对象来检验数据是否来自某 Student 分布,其位置参数为 75,尺度参数为 10,自由度为 1。
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
在 1% 的显著性水平上检验原假设,即数据来自假设分布。
[h,p] = kstest(x,'CDF',test_cdf,'Alpha',0.01)
h = logical
1
p = 0.0021
返回值 h = 1 表示 kstest 在 1% 显著性水平上拒绝了原假设。
加载样本数据。创建一个包含股票收益数据矩阵第三列的向量。
load stockreturns;
x = stocks(:,3);检验原假设,即数据来自标准正态分布;对立的备择假设为数据的总体 cdf 大于标准正态 cdf。
[h,p,k,c] = kstest(x,'Tail','larger')
h = logical
1
p = 5.0854e-05
k = 0.2197
c = 0.1207
返回值 h = 1 表明 kstest 在默认的 5% 显著性水平上拒绝了原假设,而支持备择假设。
绘制经验 cdf 和标准正态 cdf,以便进行直观比较。
[f,x_values] = ecdf(x); J = plot(x_values,f); hold on; K = plot(x_values,normcdf(x_values),'r--'); set(J,'LineWidth',2); set(K,'LineWidth',2); legend([J K],'Empirical CDF','Standard Normal CDF','Location','SE');
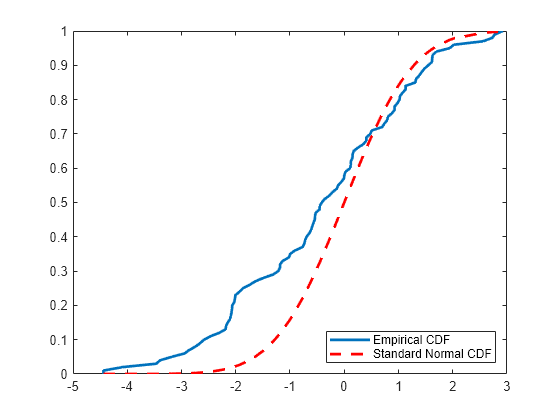
绘图显示数据向量 x 的经验 cdf 和标准正态分布的 cdf 之间的差异。
输入参数
名称-值参数
输出参量
详细信息
算法
kstest 通过比较 p 值 p 与显著性水平 Alpha(而不是通过比较检验统计量 ksstat 与临界值 cv)决定拒绝原假设。由于 cv 是逼近值,因此将 ksstat 与 cv 进行比较,得出的结论有时不同于将 p 与 Alpha 进行比较得出的结论。
参考
[1] Massey, F. J. “The Kolmogorov-Smirnov Test for Goodness of Fit.” Journal of the American Statistical Association. Vol. 46, No. 253, 1951, pp. 68–78.
[2] Miller, L. H. “Table of Percentage Points of Kolmogorov Statistics.” Journal of the American Statistical Association. Vol. 51, No. 273, 1956, pp. 111–121.
[3] Marsaglia, G., W. Tsang, and J. Wang. “Evaluating Kolmogorov’s Distribution.” Journal of Statistical Software. Vol. 8, Issue 18, 2003.
版本历史记录
在 R2006a 之前推出
另请参阅
kstest2 | lillietest | adtest