umap
Uniform Manifold Approximation and Projection (UMAP) for dimension reduction
Since R2026a
Description
Y = umap(X)X.
To calculate the embeddings, the function uses the Neg-t-SNE version of the Uniform Manifold
Approximation and Projection (UMAP) algorithm for dimension reduction. For more information,
see Algorithms.
Y = umap(X,Name=Value)
[
also returns the Y,NeighborIndicesResult] = umap(___)NumNeighbors nearest neighbor row indices for each row
of X that does not contain any NaN values. Use this
syntax with any of the input arguments in the previous syntaxes.
Examples
View the 2-D and 3-D embeddings of the human activity data set using the umap function.
Load the data set.
load humanactivityThe data set contains 24,075 observations of 60 predictors, and an activity class label for each observation. For more details on the data set, enter Description at the command line.
Associate the activities with the labels in actid.
activities = ["Sitting";"Standing";"Walking";"Running";"Dancing"]; activity = activities(actid);
Because UMAP is a stochastic algorithm, set the random number seed.
rng(0,"twister") % For reproducibility
View the 2-D embedding. Assign a color to each activity class using the hsv colormap.
Y2 = umap(feat); % Default number of embedding dimensions is 2 figure colormap = hsv(5); gscatter(Y2(:,1),Y2(:,2),activity,colormap) title("2-D Embedding")
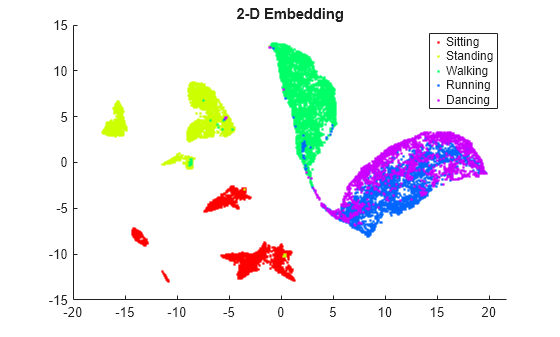
View the 3-D embedding.
Y3= umap(feat,NumDimensions=3); figure scatter3(Y3(:,1),Y3(:,2),Y3(:,3),8,colormap(actid,:),"filled") title("3-D Embedding") grid on view([12 60])
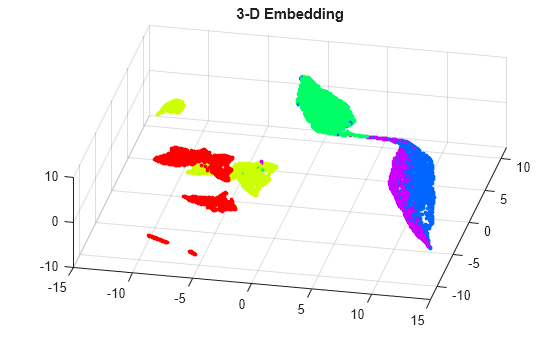
By rotating the 3-D plot, you can see that the activities Running and Dancing are more easily distinguished in 3-D than in 2-D.
Determine the effects of the UMAP embedding density and number of nearest neighbor settings on the two-dimensional embeddings of two data sets: a simulated clustered data set and a human activity data set.
Create Simulated Clustered Data
Create a simulated clustered data set with 1000 observations of 10 predictors. X contains five clusters of 200 observations each. Y contains the cluster identification numbers. The predictor values of each cluster centroid lie within the range [–5,5] and have a standard deviation sigma. The sigma value for each cluster is a random scalar in the range (0,3].
rng(0,"twister"); % For reproducibility nClusters = 5; obsPerCluster = 200; X = []; Y = []; xrange = 5; nPredictors = 10; sigmaRange = 3; for c = 1:nClusters Y = [Y; c*ones(obsPerCluster,1)]; sigma = rand*sigmaRange; X = [X; randn(obsPerCluster,nPredictors)*sigma + ... (randi(2*xrange,[1,nPredictors])-xrange).* ... ones(obsPerCluster,nPredictors)]; end
View Two-Dimensional Clustered Data Embeddings
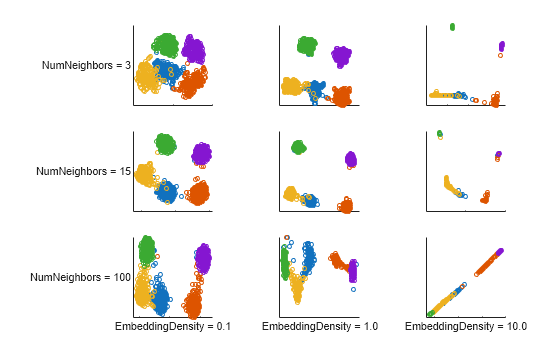
Compute two-dimensional embeddings for X with different parameter settings by using the umap function. Specify 0.1, 1, and 10 for the embedding density values, and 3, 15, and 100 for the number of nearest neighbor values. Because UMAP is a stochastic algorithm, reset the random number seed each time and set Reproducible to true. This setting for Reproducible slows down computations considerably, but is needed in this example to ensure a fair comparison between parameter settings. Display each embedding in a separate plot and assign a different color to each cluster identification number.
density = [0.1 1 10 0.1 1 10 0.1 1 10]; nNeighbors = [3 3 3 15 15 15 100 100 100]; figure t = tiledlayout(3,3,TileSpacing="compact",Padding="compact"); for i = 1:9 rng(0,"twister"); % For fair comparison E1 = umap(X,EmbeddingDensity=density(i), ... NumNeighbors=nNeighbors(i),Reproducible=false); ax = nexttile; gscatter(E1(:,1),E1(:,2),Y,[],"o",3,"off") ax.XTickLabel = []; ax.YTickLabel = []; if i > 6 xlabel(sprintf("EmbeddingDensity = %.1f",density(i)),FontSize=8); end if (mod(i-1,3) == 0) ylabel(sprintf("NumNeighbors = %d",nNeighbors(i)), ... FontSize=8,Rotation=0); end axis square end
Load and Preprocess Human Activity Data
Load the human activity data set.
load humanactivityThe data set contains 24,075 observations of 60 predictors, and an activity class label for each observation. For more details on the data set, enter Description at the command line.
The observations are organized by activity class. To better represent a random set of data, shuffle the rows.
n = numel(actid); idx = randsample(n,n); X2 = feat(idx,:); actid = actid(idx);
View Two-Dimensional Human Activity Data Embeddings
Compute two-dimensional embeddings using standardized data and the same set of embedding density values and number of nearest neighbor values as for the simulated clustered data set. Reset the random number seed before computing each embedding, and set Reproducible=true to ensure a fair comparison between parameter settings. Display each embedding in a separate plot, and assign a different color to each activity class.
figure t = tiledlayout(3,3,TileSpacing="compact",Padding= "compact"); for i = 1:9 rng(0,"twister"); % For fair comparison E2 = umap(X2,Standardize=true,EmbeddingDensity=density(i), ... NumNeighbors=nNeighbors(i),Reproducible=true); ax = nexttile; gscatter(E2(:,1),E2(:,2),actnames(actid)',[],"o",3,"off") ax.XTickLabel = []; ax.YTickLabel = []; if i > 6 xlabel(sprintf("EmbeddingDensity = %.1f",density(i)),FontSize=8); end if (mod(i-1,3) == 0) ylabel(sprintf("NumNeighbors = %d",nNeighbors(i)), ... FontSize=8,Rotation=0); end axis square end
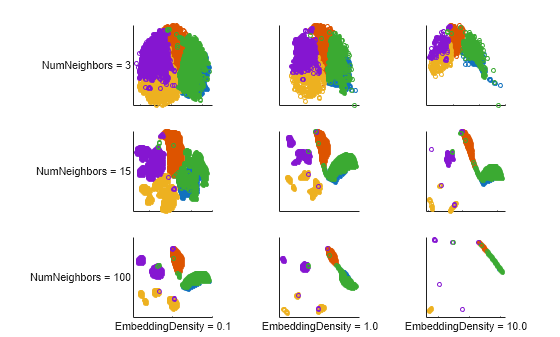
The embeddings of the two data sets show that higher embedding density values result in a tighter clustering of points. For very high values of EmbeddingDensity, the clusters can begin to merge. The effect of the number of nearest neighbors parameter depends on the particular data set and the embedding density value. A higher value of NumNeighbors causes umap to treat more pairs of points as neighbors, and to try bringing them closer together in the embedding space.
For the simulated clustered data set, the tightest, most distinct cluster representation occurs for NumNeighbors = 15. However, when EmbeddingDensity is 10, none of the NumNeighbors values yield an embedding with distinct clusters.
For the human activity data set, the highest NumNeighbors value yields relatively distinct clusters. However, when NumNeighbors is 100 and EmbeddingDensity is 10, most of the observations overlap in the same locations.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
References
[1] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.
[2] Böhm, J. N. "Attraction-Repulsion Spectrum in Neighbor Embeddings." Journal of Machine Learning Research , no. 23 (2022): 4118–4149.
[3] Damrich, Sebastian, and Fred A. Hamprecht. "On UMAP's True Loss Function." Neural Information Processing Systems (2021).
[4] Damrich, Sebastian, et al. "From t-SNE to UMAP with Contrastive Learning." arXiv:2206.01816 [cs], June 2022. arXiv.org.
[5] Healy, John, and Leland McInnes. "Uniform Manifold Approximation and Projection." Nature Reviews Methods Primers 4, no. 1 (2024).
[6] McInnes, Leland, John Healy, Nathaniel Saul, and Lukas Großberger. "UMAP: Uniform Manifold Approximation and Projection." Journal of Open Source Software 3, no. 29 (September 2, 2018): 861.
Version History
Introduced in R2026a