ztest
z 检验
说明
示例
加载样本数据。创建包含学生考试成绩数据的第一列的向量。
load examgrades
x = grades(:,1);检验原假设,即数据来自具有均值 m = 75 和标准差 sigma = 10 的正态分布。
[h,p,ci,zval] = ztest(x,75,10)
h = 0
p = 0.9927
ci = 2×1
73.2191
76.7975
zval = 0.0091
返回值 h = 0 表明 ztest 在默认的 5% 显著性水平上未拒绝原假设。
加载样本数据。创建包含学生考试成绩数据的第一列的向量。
load examgrades
x = grades(:,1);绘制考试成绩数据的直方图,并拟合正态密度函数。
histfit(x) xlabel("Grade") ylabel("Frequency")
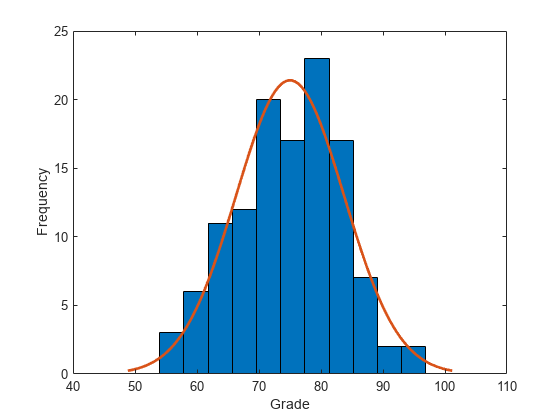
针对备择假设检验原假设,原假设为数据来自具有均值 m = 65 和标准差 sigma = 10 的正态分布,备择假设为分布的均值大于 65。
[h,~,~,zval] = ztest(x,65,10,"Tail","right")
h = 1
zval = 10.9636
返回值 h = 1 表明 ztest 在默认的 5% 显著性水平上拒绝了原假设,而支持备择假设,即总体均值大于 65。
绘制标准正态分布、返回的 z 统计量和临界 z 值。使用 norminv 计算默认置信水平为 95% 时的临界 z 值。
k = linspace(-15,15,300); y = normpdf(k); zvalpdf = normpdf(zval); zcrit = norminv(0.95); plot(k,y); hold on scatter(zval,zvalpdf,"filled") xline(zcrit,"--") legend(["Standard Normal pdf","z-Statistic", ... "Critical Cutoff"])
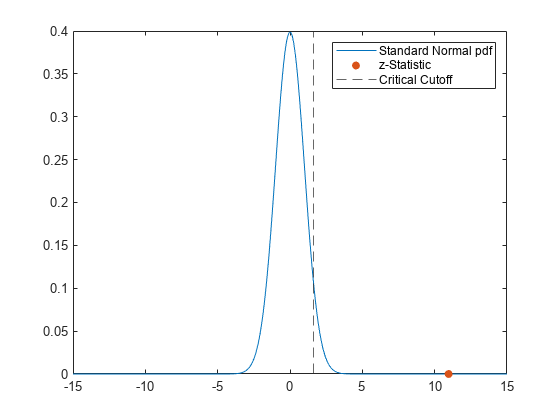
橙色圆点表示 z 统计量,位于表示临界 z 值的黑色虚线右侧。
输入参数
名称-值参数
输出参量
详细信息
提示
使用
sampsizepwr计算:对应于指定检验功效和参数值的样本大小;
给定真实参数值时,特定样本大小的检验功效;
可用指定的样本大小和检验功效检测的参数值。
扩展功能
版本历史记录
在 R2006a 之前推出
另请参阅
ttest | ttest2 | sampsizepwr