ttest2
双样本 t 检验
说明
示例
加载数据集。创建包含数据矩阵第一列和第二列的向量,以表示学生在两次考试中的成绩。
load examgrades
x = grades(:,1);
y = grades(:,2);检验原假设,即两个数据样本来自均值相等的总体。
[h,p,ci,stats] = ttest2(x,y)
h = 0
p = 0.9867
ci = 2×1
-1.9438
1.9771
stats = struct with fields:
tstat: 0.0167
df: 238
sd: 7.7084
返回值 h = 0 表明 ttest2 在默认的 5% 显著性水平上未拒绝原假设。
加载数据集。创建包含数据矩阵第一列和第二列的向量,以表示学生在两次考试中的成绩。
load examgrades
x = grades(:,1);
y = grades(:,2);检验原假设,即两个数据向量来自均值相等的总体,而不假设总体还具有方差齐性。
[h,p] = ttest2(x,y,'Vartype','unequal')
h = 0
p = 0.9867
返回值 h = 0 表明 ttest2 在默认的 5% 显著性水平上未拒绝原假设,即使没有假设方差齐性也是如此。
加载样本数据。创建一个分类向量,根据车辆年份标注车辆里程数据。
load carbig.mat; decade = categorical(Model_Year < 80,[true,false],["70s","80s"]);
创建每十年的里程数据的箱线图。
boxchart(decade,MPG) xlabel("Decade") ylabel("Mileage")
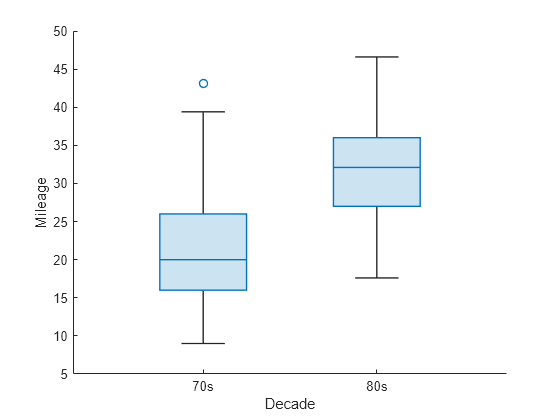
根据每十年的里程数据创建向量。使用左尾双样本 t 检验来检验原假设,即数据来自均值相等的总体。使用备择假设,即 20 世纪 70 年代生产的汽车里程的总体均值小于 20 世纪 80 年代生产的汽车里程的总体均值。
MPG70s = MPG(decade == "70s"); MPG80s = MPG(decade == "80s"); [h,~,~,stats] = ttest2(MPG70s,MPG80s,"Tail","left")
h = 1
stats = struct with fields:
tstat: -14.0630
df: 396
sd: 6.3910
返回值 h = 1 表明 ttest2 在 5% 的默认显著性水平上拒绝了原假设,而支持备择假设,即 20 世纪 70 年代生产的汽车里程的总体均值小于 20 世纪 80 年代生产的汽车里程的总体均值。
绘制相应的 Student t 分布、返回的 t 统计量和临界 t 值。使用 tinv 计算默认置信水平为 95% 时的临界 t 值。
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = -14.0630
tvalpdf = tpdf(tval,nu); tcrit = -tinv(0.95,nu)
tcrit = -1.6487
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf","t-statistic", ... "Critical Cutoff"])

橙色圆点表示 t 统计量,位于表示临界 t 值的黑色虚线左侧。
输入参数
名称-值参数
输出参量
详细信息
提示
使用
sampsizepwr计算:对应于指定检验功效和参数值的样本大小;
给定真实参数值时,特定样本大小的检验功效;
可用指定的样本大小和检验功效检测的参数值。
扩展功能
版本历史记录
在 R2006a 之前推出
另请参阅
ttest | ztest | sampsizepwr