vision.CascadeObjectDetector
Detect objects using the Viola-Jones algorithm
Description
The cascade object detector uses the Viola-Jones algorithm to detect people’s faces, noses, eyes, mouth, or upper body. You can also use the Image Labeler to train a custom classifier to use with this System object™. For details on how the function works, see Get Started with Cascade Object Detector.
To detect facial features or upper body in an image:
Create the
vision.CascadeObjectDetectorobject and set its properties.Call the object with arguments, as if it were a function.
To learn more about how System objects work, see What Are System Objects?
Creation
Syntax
Description
detector = vision.CascadeObjectDetector
detector = vision.CascadeObjectDetector(
creates a detector configured to detect objects defined by the input character vector,
model)model.
detector = vision.CascadeObjectDetector(
creates a detector and configures it to use the custom classification model specified
with the XMLFILE)XMLFILE input.
detector = vision.CascadeObjectDetector(Name,Value)detector =
vision.CascadeObjectDetector('ClassificationModel','UpperBody')
Properties
Usage
Description
detectionResults = detector(ds)read
function of the input datastore.
Input Arguments
Output Arguments
Object Functions
To use an object function, specify the
System object as the first input argument. For
example, to release system resources of a System object named obj, use
this syntax:
release(obj)
Examples
Create a face detector object.
faceDetector = vision.CascadeObjectDetector;
Read the input image.
I = imread('visionteam.jpg');Detect faces.
bboxes = faceDetector(I);
Annotate detected faces.
IFaces = insertObjectAnnotation(I,'rectangle',bboxes,'Face'); figure imshow(IFaces) title('Detected faces');

Create a body detector object and set properties.
bodyDetector = vision.CascadeObjectDetector('UpperBody');
bodyDetector.MinSize = [60 60];
bodyDetector.MergeThreshold = 10;Read input image and detect upper body.
I2 = imread('visionteam.jpg');
bboxBody = bodyDetector(I2);Annotate detected upper bodies.
IBody = insertObjectAnnotation(I2,'rectangle',bboxBody,'Upper Body'); figure imshow(IBody) title('Detected upper bodies');

Algorithms
This object uses a cascade of classifiers to efficiently process image regions for the presence of a target object. Each stage in the cascade applies increasingly more complex binary classifiers, which allows the algorithm to rapidly reject regions that do not contain the target. If the desired object is not found at any stage in the cascade, the detector immediately rejects the region and processing is terminated. By terminating, the object avoids invoking computation-intensive classifiers further down the cascade.
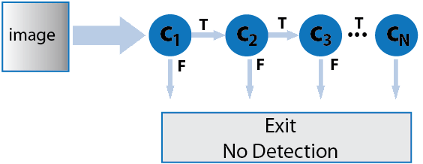
The detector incrementally scales the input image to locate target objects. At each
scale increment, a sliding window, whose size is the same as the training image size, scans
the scaled image to locate objects. The ScaleFactor property determines
the amount of scaling between successive increments.
The search region size is related to the ScaleFactor in the
following way:
search region = round((ObjectTrainingSize)*(ScaleFactorN))

The search window traverses the image for each scaled increment.
For each increment in scale, the search window traverses over the image producing
multiple detections around the target object. The multiple detections are merged into one
bounding box per target object. You can use the MergeThreshold property
to control the number of detections required before combining or rejecting the detections.
The size of the final bounding box is an average of the sizes of the bounding boxes for the
individual detections and lies between MinSize and
MaxSize.

References
[1] Lienhart R., Kuranov A., and V. Pisarevsky "Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection." Proceedings of the 25th DAGM Symposium on Pattern Recognition. Magdeburg, Germany, 2003.
[2] Ojala Timo, Pietikäinen Matti, and Mäenpää Topi, "Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns". In IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002. Volume 24, Issue 7, pp. 971-987.
[3] Kruppa H., Castrillon-Santana M., and B. Schiele. "Fast and Robust Face Finding via Local Context". Proceedings of the Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, 2003, pp. 157–164.
[4] Castrillón Marco, Déniz Oscar, Guerra Cayetano, and Hernández Mario, "ENCARA2: Real-time detection of multiple faces at different resolutions in video streams". In Journal of Visual Communication and Image Representation, 2007 (18) 2: pp. 130-140.
[5] Yu Shiqi "Eye Detection." Shiqi Yu’s Homepage. http://yushiqi.cn/research/eyedetection.
[6] Viola, Paul and Michael J. Jones, "Rapid Object Detection using a Boosted Cascade of Simple Features" , Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2001. Volume: 1, pp.511–518.
[7] Dalal, N., and B. Triggs, "Histograms of Oriented Gradients for Human Detection". IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Volume 1, (2005), pp. 886–893.
[8] Ojala, T., M. Pietikainen, and T. Maenpaa, "Multiresolution Gray-scale and Rotation Invariant Texture Classification With Local Binary Patterns". IEEE Transactions on Pattern Analysis and Machine Intelligence. Volume 24, No. 7 July 2002, pp. 971–987.
Extended Capabilities
Version History
Introduced in R2012a
See Also
Image Labeler | trainCascadeObjectDetector | insertShape | vision.PeopleDetector | integralImage | faceDetector
Topics
- Face Detection and Tracking Using CAMShift
- Face Detection and Tracking Using the KLT Algorithm
- Face Detection and Tracking Using Live Video Acquisition
- Code Generation for Face Tracking with PackNGo
- Detect and Track Face
- Get Started with the Image Labeler
- Get Started with Cascade Object Detector
- Multiple Object Tracking