Get Started with Vision-Language Models
Vision-language models (VLMs) are transformer-based deep learning models, trained on large data sets of images and associated text, that connect visual understanding with natural language.
The visual feature-to-language association by VLMs enables tasks such as:
Object detection and labeling — Identify and rapidly label objects in images using text prompts.
Image captioning — Generate descriptive sentences for images.
Zero-shot image classification — Categorize images into classes not seen during training, using class names as text prompts.
Image search — Find images that match a text query.
Computer Vision Toolbox™ provides several pretrained VLMs for image captioning, object detection with natural language queries, image classification, and image-text retrieval.
Select Vision-Language Model
Use this table to choose a VLM based on your application.
| Vision-Language Model | Use Case | Sample Visualization and Examples |
|---|---|---|
Grounding-DINO – Detect objects in images using natural language text queries. | Use the
|
For an example, see Perform Zero-Shot Object Detection Using Grounding DINO. |
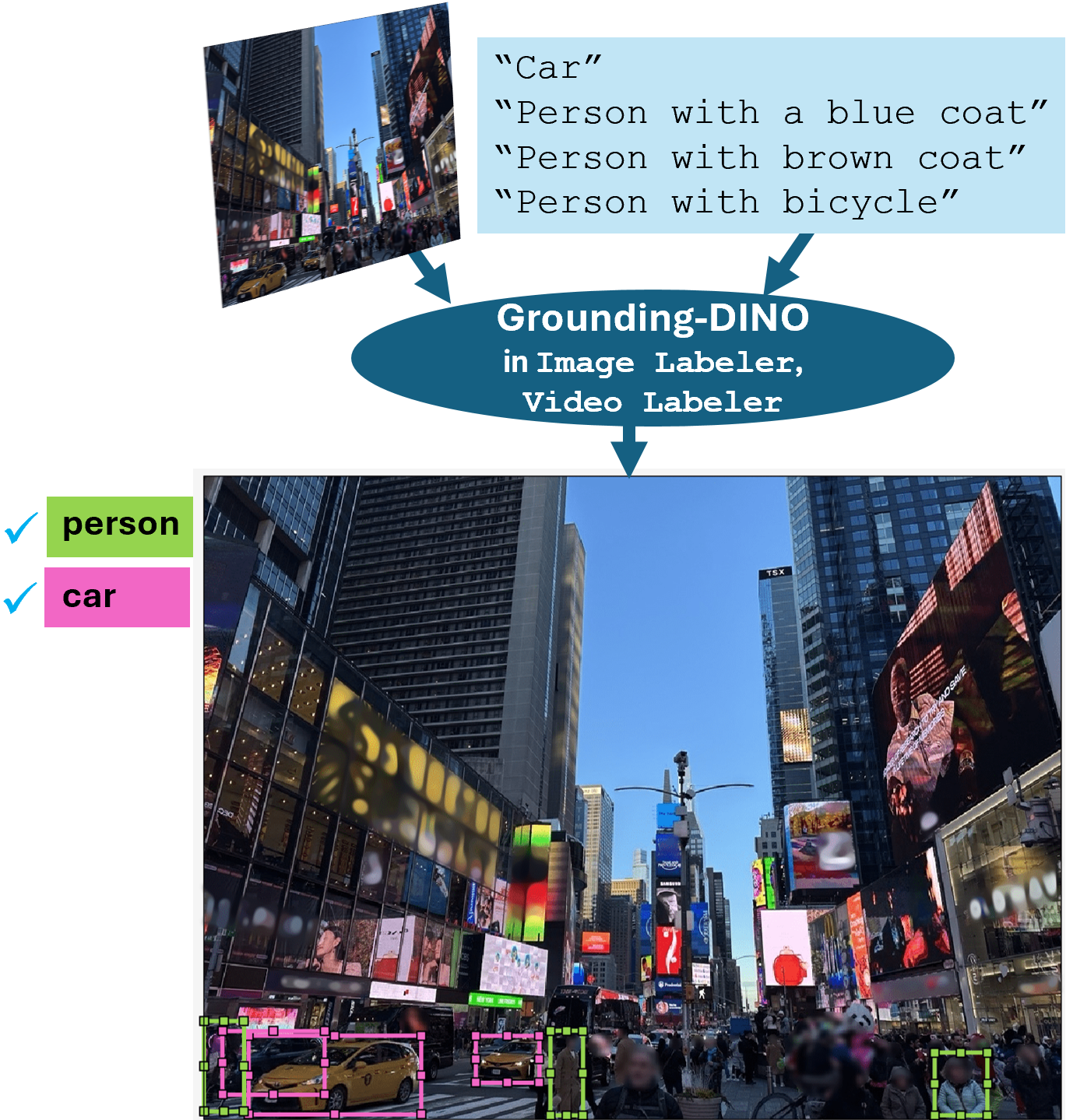
Grounding-DINO – Automatically label objects in images and video frames using natural language text queries. | Automatically label specific objects in image and video scenes by specifying descriptive text queries using the Grounding DINO tool in the Image Labeler and Video Labeler apps. |
For an example, see Automatically Label Ground Truth Using Vision-Language Model. |
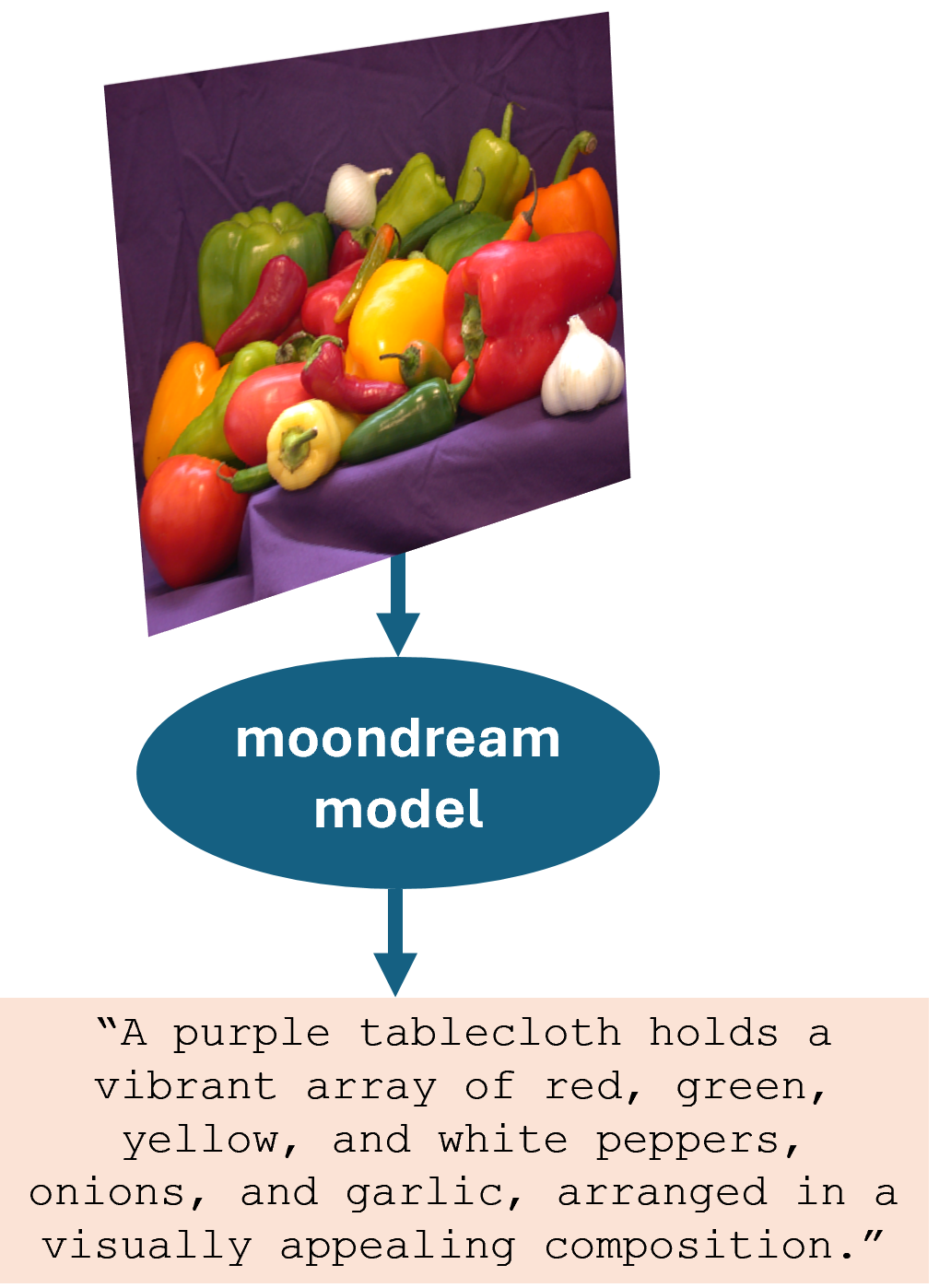
| Moondream™ – Caption images. | Create the Moondream vision-language model using the |
For example, see: |
| Contrastive Language–Image Pre-training (CLIP) – Classify and retrieve images using text. | Use the
|
For example, see: |


Integrate VLMs into Visual Data Workflows
Use outputs from VLMs to enhance and automate various stages of your visual understanding pipeline. These are examples of applications where you can use VLM outputs as an initial starting point.
Use the Grounding-DINO object detector to accelerate automatic data set labeling by generating bounding box annotations for custom object classes. You can define the custom object classes using input text descriptions.
Use the Moondream model to automatically generate captions for images in a datastore, creating paired image-caption data sets. Then, you can use these automatically generated data sets as the paired image-text data required to train or evaluate vision-language models, such as CLIP or other multimodal networks.
Use CLIP to generate shared image-text embeddings, which you can then use for advanced tasks such as image-text matching, clustering, search, or integration into web applications.
Use CLIP to measure image similarity by extracting embeddings for both images and text queries and computing the cosine similarity between any pair of embedding vectors. You can use this numerical measure of similarity for tasks like image retrieval, clustering, or duplicate detection.
See Also
Apps
Functions
Topics
- Automatically Label Ground Truth Using Vision-Language Model
- Deep Learning in MATLAB (Deep Learning Toolbox)