Vision-Language Models
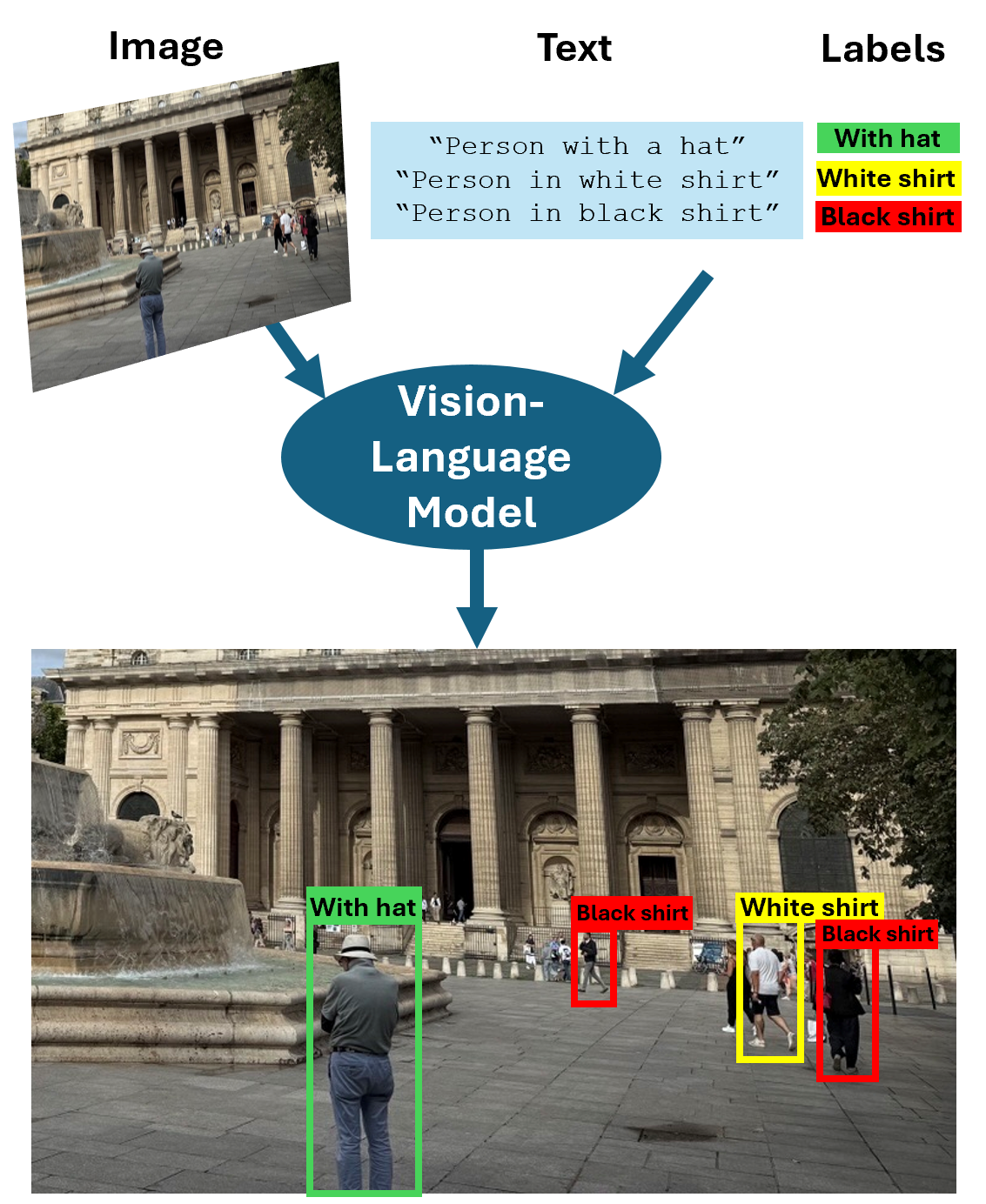
Vision-Language Models (VLMs) are multimodal models that take image and text inputs, and can generate text outputs or return bounding boxes with corresponding annotations, enabling tasks such as object detection and visual grounding. These models can analyze visual content in images or videos, process accompanying text, and identify correlations between visual and textual data. They enable a range of tasks that involve interpreting visual information within the context of language, using predictive algorithms rather than true comprehension. The Computer Vision Toolbox™ provides several pretrained VLMs, including CLIP, Grounding DINO, and Moondream, for these applications:
Image captioning — Generate descriptive text for an image.
Image retrieval — Locate images from a predefined set that best match a text description.
Object detection — Detect objects in an image based on a text-based query.
Image classification — Classify images based on textual categories.
Additionally, you can use VLMs to automatically label ground truth using descriptive text prompts in the Image Labeler and Video Labeler apps. To get started, see Get Started with Vision-Language Models.
Apps
| Image Labeler | Label images for computer vision applications |
| Video Labeler | Label video for computer vision applications |
Functions
Topics
Get Started
- Get Started with Vision-Language Models
Use vision-language models for multimodal tasks such as image captioning, zero-shot classification, and image search.
Featured Examples

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
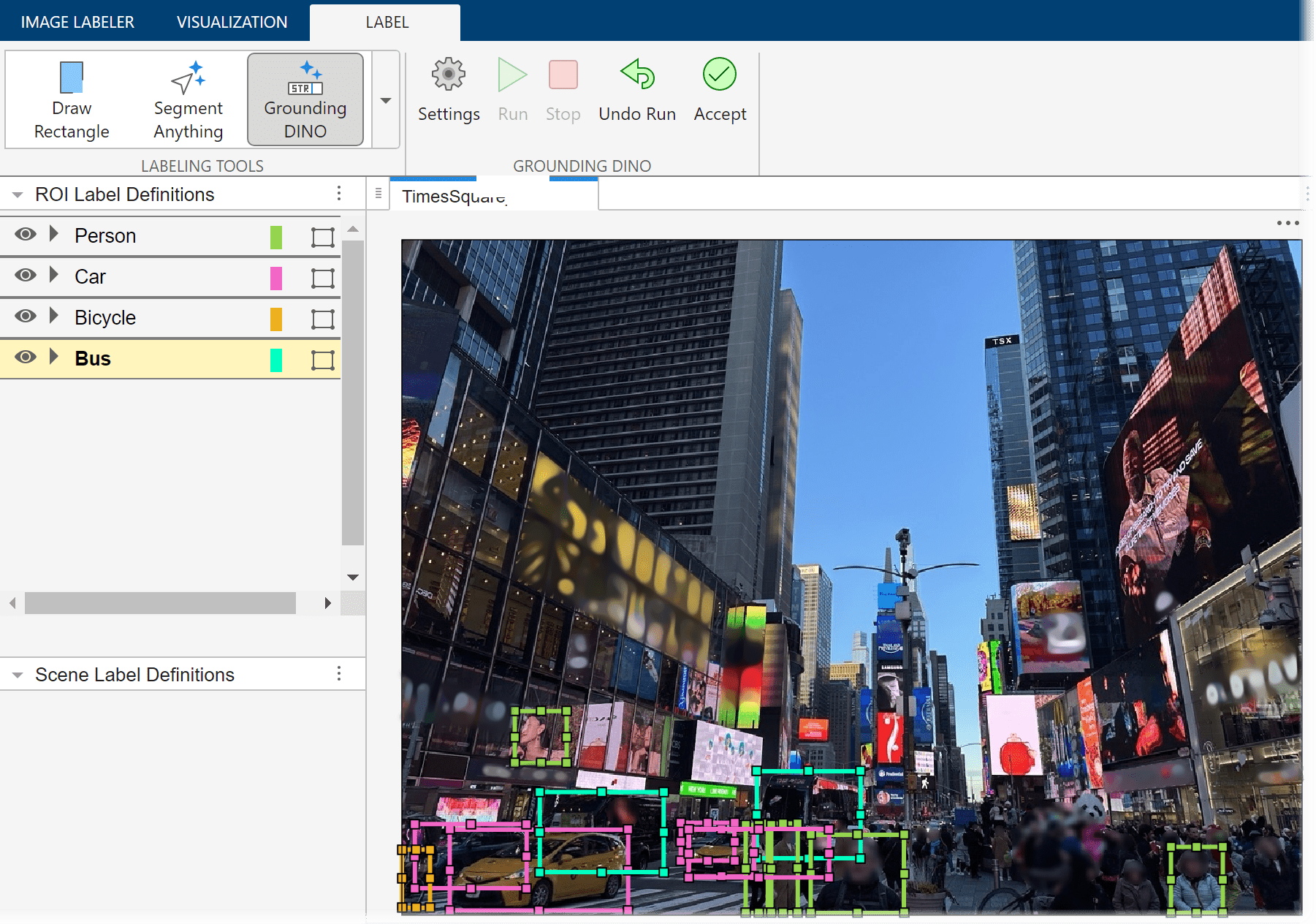
Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).
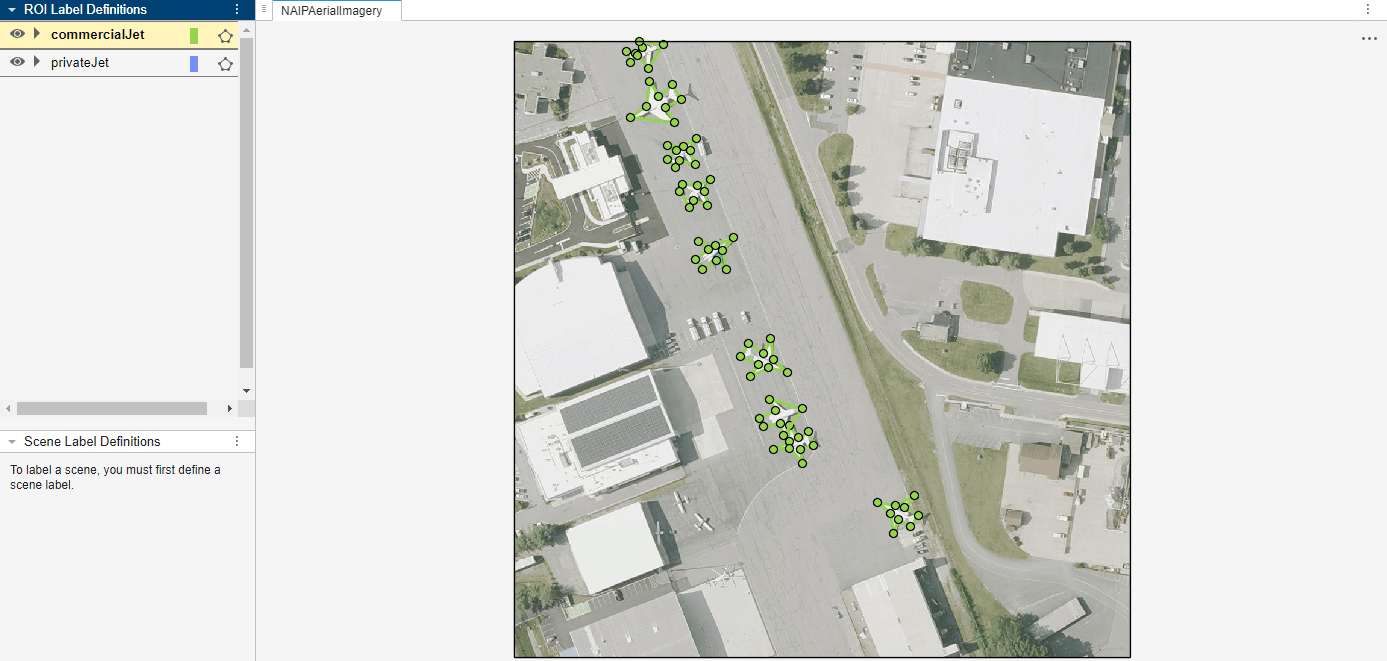
Automate Ground Truth Polygon Labeling Using Grounded SAM Model
Combine Grounding DINO and the Segment Anything Model 2 (SAM 2) to automatically produce polygon labels using the Video Labeler app.
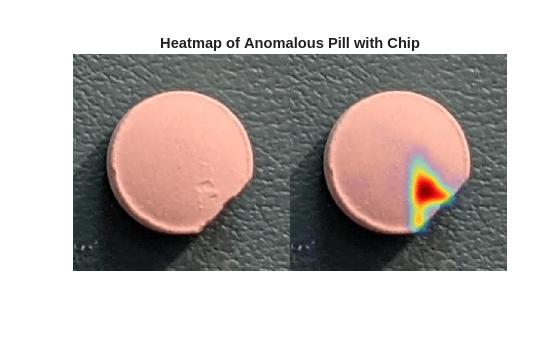
Detect Industrial Defects Using Zero-Shot AnomalyCLIP
Detect and localize industrial production defects in pill images using an AnomalyCLIP anomaly detection network.