AI for Audio
Audio Toolbox™ provides functionality to develop machine and deep learning solutions for audio, speech, and acoustic applications including speaker identification, speech command recognition, speech separation, acoustic scene recognition, denoising, and many more.
Use
audioDatastoreto ingest large audio data sets and process files in parallel.Use Signal Labeler to build audio data sets by annotating audio recordings manually and automatically.
Use
audioDataAugmenterto create randomized pipelines of built-in or custom signal processing methods for augmenting and synthesizing audio data sets.Use
audioFeatureExtractorto extract combinations of different features while sharing intermediate computations.
Audio Toolbox also provides access to third-party APIs for text-to-speech and speech-to-text, and it includes pretrained models so that you can perform transfer learning, classify sounds, and extract feature embeddings. Using pretrained networks requires Deep Learning Toolbox™.
Categories
- Applications
Apply AI workflows to audio applications
- Dataset Management and Labeling
Ingest, create, and label large data sets
- Feature Extraction
Mel spectrogram, MFCC, pitch, spectral descriptors
- Data Augmentation
Augmentation pipelines, shift pitch and time, stretch time, control volume and noise
- Segmentation
Detect and isolate speech and other sounds
- Pretrained Models
Transfer learning, sound classification, feature embeddings, pretrained audio deep learning networks
- Speech Transcription and Synthesis
Use pretrained models or third-party APIs for text-to-speech and speech-to-text
- AI with MATLAB and Python
Develop AI for audio processing in MATLAB® using Python® coexecution
- Code Generation and GPU Support
Generate portable C/C++/MEX functions and use GPUs to deploy or accelerate processing
Featured Examples

AI for Speech Command Recognition
Build, train, compress, and deploy a deep learning model for speech command recognition.
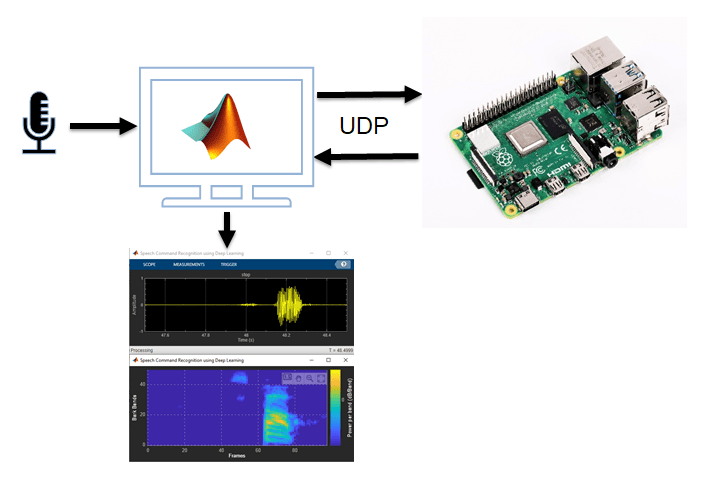
Speech Command Recognition Code Generation on Raspberry Pi
Generate code and deploy feature extraction and speech command recognition network on Raspberry Pi hardware.
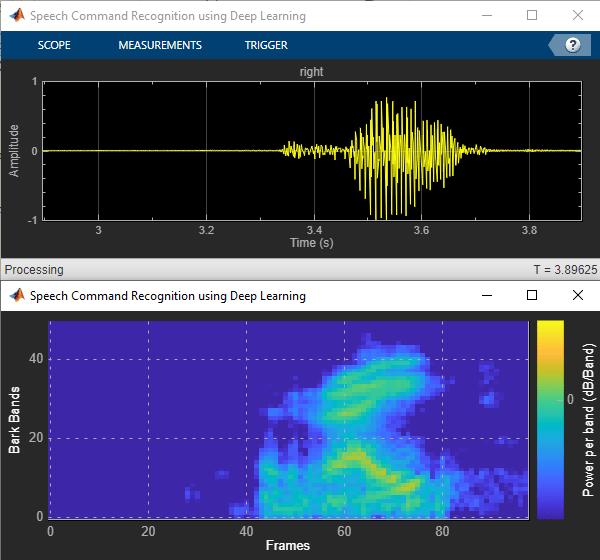
Speech Command Recognition Code Generation on Desktop
Deploy feature extraction and a convolutional neural network (CNN) for speech command recognition. In this example, the generated code is a MATLAB executable (MEX) function, which is called by a MATLAB script that displays the predicted speech command along with the time domain signal and auditory spectrogram. For details about audio preprocessing and network training, see Train Deep Learning Network for Speech Command Recognition.
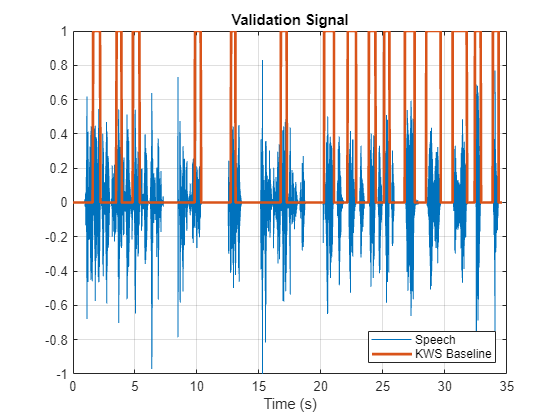
Keyword Spotting in Noise Using MFCC and LSTM Networks
Identify a keyword in noisy speech using a deep learning network. In particular, the example uses a Bidirectional Long Short-Term Memory (BiLSTM) network and mel frequency cepstral coefficients (MFCC).
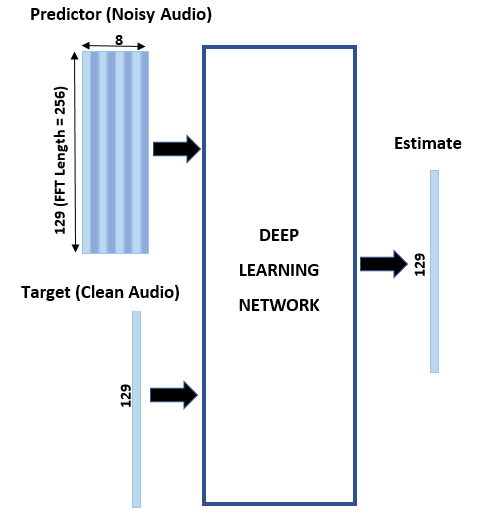
Denoise Speech Using Deep Learning Networks
Denoise speech signals using deep learning networks. The example compares two types of networks applied to the same task: fully connected, and convolutional.
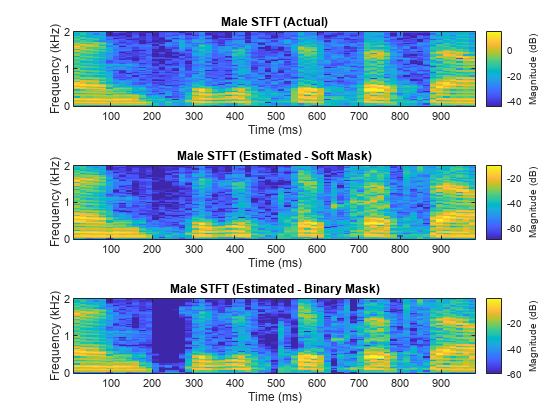
Cocktail Party Source Separation Using Deep Learning Networks
Isolate a speech signal using a deep learning network.
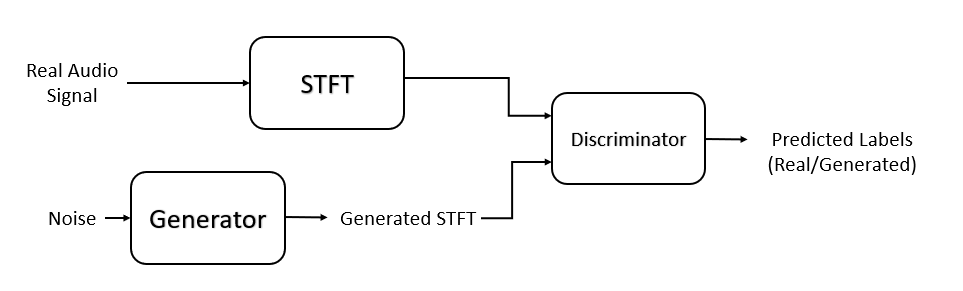
Train Generative Adversarial Network (GAN) for Sound Synthesis
Train and use a generative adversarial network (GAN) to generate sounds.
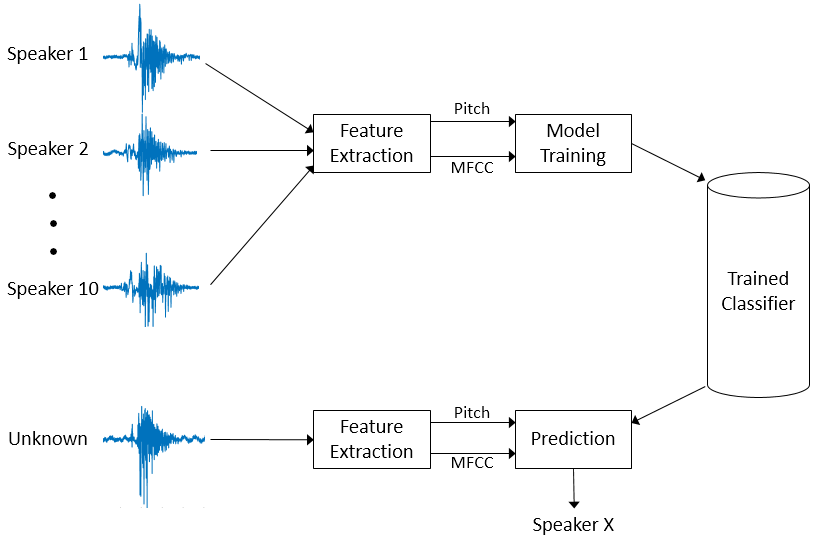
Speaker Identification Using Pitch and MFCC
Use machine learning to identify people based on features extracted from recorded speech.
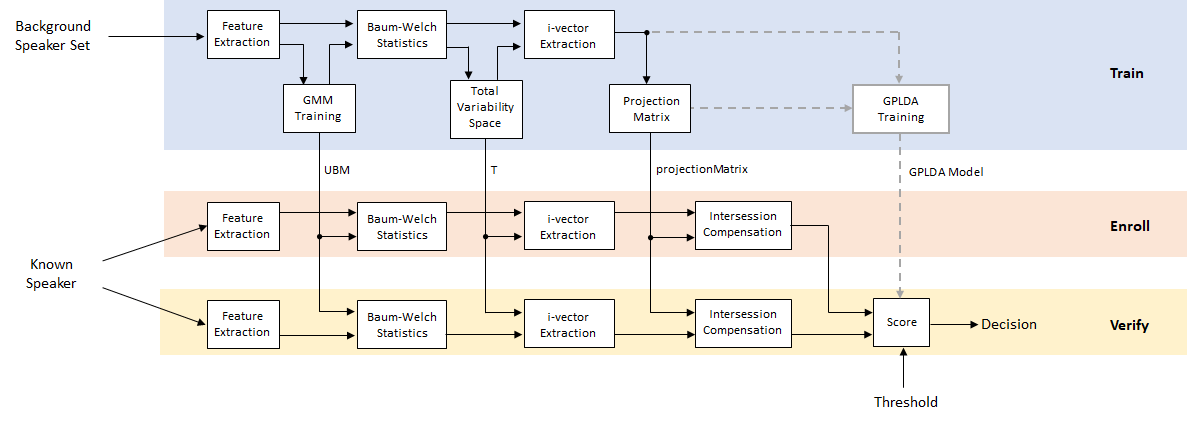
Speaker Verification Using i-vectors
Speaker verification, or authentication, is the task of confirming that the identity of a speaker is who they purport to be. Speaker verification has been an active research area for many years. An early performance breakthrough was to use a Gaussian mixture model and universal background model (GMM-UBM) [1] on acoustic features (usually mfcc). For an example, see Speaker Verification Using Gaussian Mixture Models. One of the main difficulties of GMM-UBM systems involves intersession variability. Joint factor analysis (JFA) was proposed to compensate for this variability by separately modeling inter-speaker variability and channel or session variability [2] [3]. However, [4] discovered that channel factors in the JFA also contained information about the speakers, and proposed combining the channel and speaker spaces into a total variability space. Intersession variability was then compensated for by using backend procedures, such as linear discriminant analysis (LDA) and within-class covariance normalization (WCCN), followed by a scoring, such as the cosine similarity score. [5] proposed replacing the cosine similarity scoring with a probabilistic LDA (PLDA) model. [11] and [12] proposed a method to Gaussianize the i-vectors and therefore make Gaussian assumptions in the PLDA, referred to as G-PLDA or simplified PLDA. While i-vectors were originally proposed for speaker verification, they have been applied to many problems, like language recognition, speaker diarization, emotion recognition, age estimation, and anti-spoofing [10]. Recently, deep learning techniques have been proposed to replace i-vectors with d-vectors or x-vectors [8] [6].

Train End-to-End Speaker Separation Model
Use an end-to-end deep learning network for speaker-independent speech separation.