使用深度学习进行序列分类
此示例说明如何使用长短期记忆 (LSTM) 网络对序列数据进行分类。
要训练深度神经网络以对序列数据进行分类,可以使用 LSTM 神经网络。LSTM 神经网络允许您将序列数据输入网络,并根据序列数据的各个时间步进行预测。
此图说明序列数据流经序列分类神经网络的序列数据。
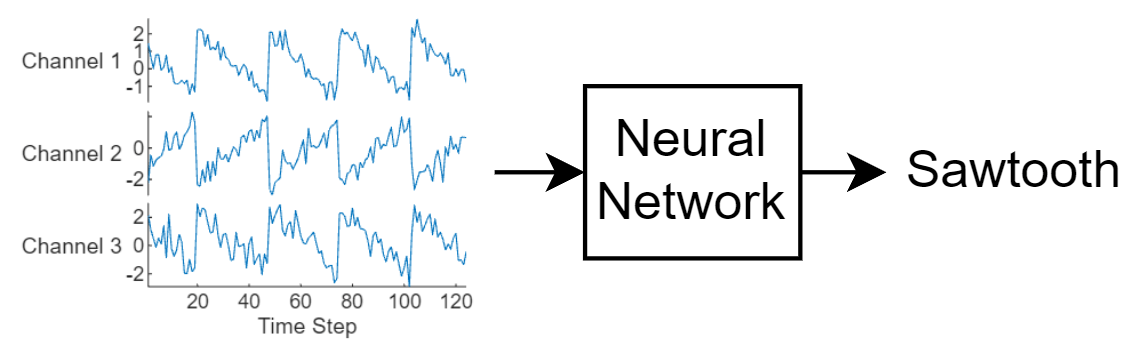
此示例使用 Waveform 数据集。此示例训练 LSTM 神经网络来识别给定时间序列数据的波形类型。训练数据包含四种波形的时间序列数据。每个序列有三个通道,且长度不同。
加载序列数据
从 WaveformData 加载示例数据。序列数据是序列的 numObservations×1 元胞数组,其中 numObservations 是序列数。每个序列都是一个 numTimeSteps×-numChannels 数值数组,其中 numTimeSteps 是序列的时间步,numChannels 是序列的通道数。标签数据是 numObservations×1 分类向量。
load WaveformData 在绘图中可视化一些序列。
numChannels = size(data{1},2);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end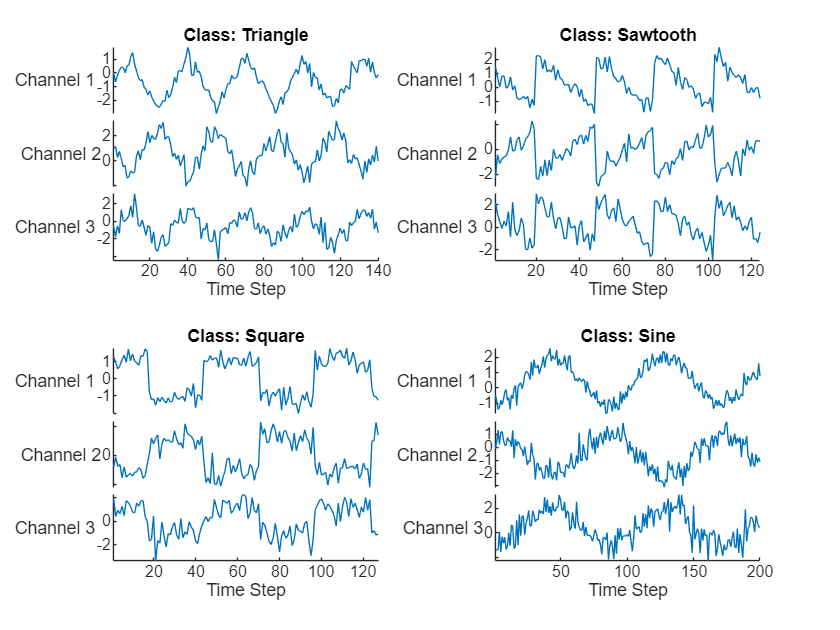
查看类名称。
classNames = categories(labels)
classNames = 4×1 cell
{'Sawtooth'}
{'Sine' }
{'Square' }
{'Triangle'}
留出测试数据。将数据划分为训练集(包含 90% 数据)和测试集(包含其余 10% 数据)。要划分数据,请使用 trainingPartitions 函数,此函数作为支持文件包含在此示例中。要访问此文件,请以实时脚本形式打开此示例。
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations,[0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
准备要填充的数据
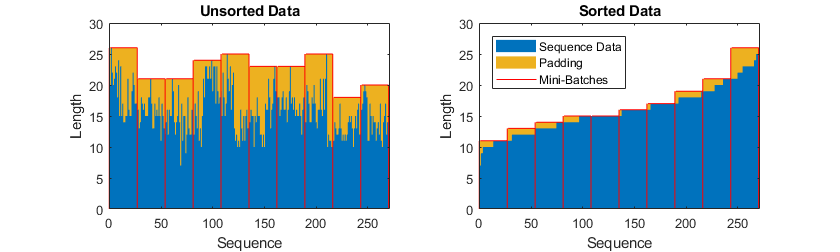
在训练过程中,默认情况下,软件将训练数据拆分成小批量并填充序列,使它们具有相同的长度。过多填充会对网络性能产生负面影响。
为了防止训练过程添加过多填充,您可以按序列长度对训练数据进行排序,并选择合适的小批量大小,以使同一小批量中的序列长度相近。下图显示了对数据进行排序之前和之后填充序列的效果。
获取每个观测值的序列长度。
numObservations = numel(XTrain); for i=1:numObservations sequence = XTrain{i}; sequenceLengths(i) = size(sequence,1); end
按序列长度对数据进行排序。
[sequenceLengths,idx] = sort(sequenceLengths); XTrain = XTrain(idx); TTrain = TTrain(idx);
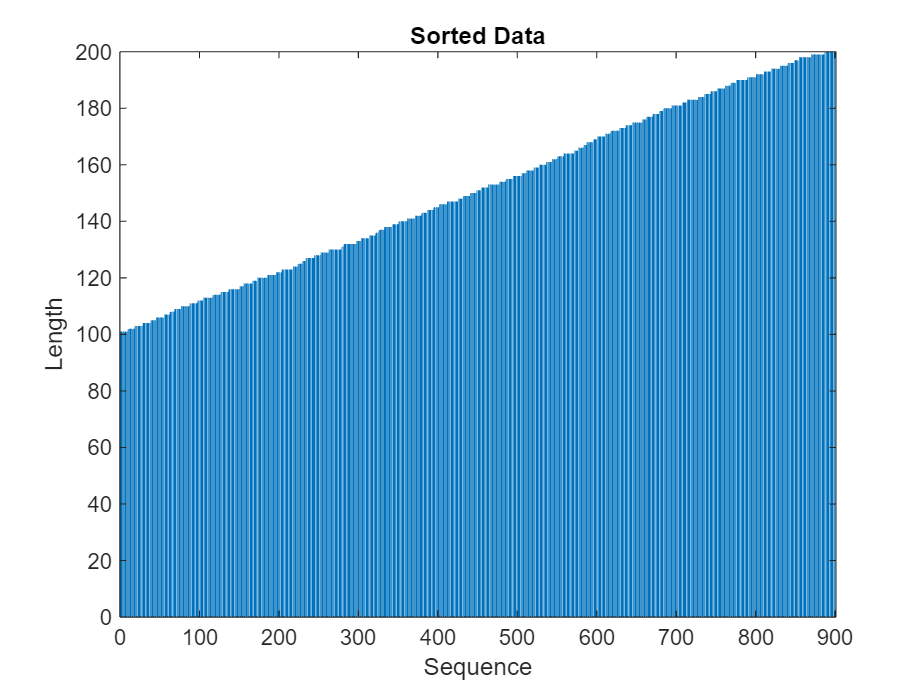
在条形图中查看排序的序列长度。
figure bar(sequenceLengths) xlabel("Sequence") ylabel("Length") title("Sorted Data")
定义 LSTM 神经网络架构
定义 LSTM 神经网络架构。
将输入大小指定为输入数据的通道数。
指定一个具有 120 个隐藏单元的双向 LSTM 层,并输出序列的最后一个元素。
最后,包括一个输出大小与类的数量匹配的全连接层,后跟一个 softmax 层。
如果您可以在预测时访问完整序列,则可以在网络中使用双向 LSTM 层。双向 LSTM 层在每个时间步从完整序列学习。如果您不能在预测时访问完整序列,例如,您正在预测值或一次预测一个时间步时,则改用 LSTM 层。
numHiddenUnits = 120;
numClasses = 4;
layers = [
sequenceInputLayer(numChannels)
bilstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer]layers =
4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' BiLSTM BiLSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
指定训练选项
指定训练选项。在选项中进行选择需要经验分析。要通过运行试验探索不同训练选项配置,您可以使用Experiment Manager。
使用 Adam 求解器进行训练。
进行 200 轮训练。
指定学习率为 0.002。
使用阈值 1 裁剪梯度。
为了保持序列按长度排序,禁用乱序。
在图中显示训练进度并监控准确度。
禁用详尽输出。
options = trainingOptions("adam", ... MaxEpochs=200, ... InitialLearnRate=0.002,... GradientThreshold=1, ... Shuffle="never", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
训练 LSTM 神经网络
使用 trainnet 函数训练神经网络。对于分类,使用交叉熵损失。默认情况下,trainnet 函数使用 GPU(如果有)。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,该函数使用 CPU。要指定执行环境,请使用 ExecutionEnvironment 训练选项。
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
测试 LSTM 神经网络
准备测试数据。LSTM 神经网络 net 已使用相似长度的小批量序列进行训练。确保以相同的方式组织测试数据。按序列长度对测试数据进行排序。
numObservationsTest = numel(XTest); for i=1:numObservationsTest sequence = XTest{i}; sequenceLengthsTest(i) = size(sequence,1); end [sequenceLengthsTest,idx] = sort(sequenceLengthsTest); XTest = XTest(idx); TTest = TTest(idx);
使用 testnet 函数测试神经网络。对于单标签分类,需评估准确度。准确度是正确预测的标签的百分比。默认情况下,testnet 函数使用 GPU(如果有)。要手动选择执行环境,请使用 testnet 函数的 ExecutionEnvironment 参量。
acc = testnet(net,XTest,TTest,"accuracy")acc = 84
在混淆图中显示分类结果。使用 minibatchpredict 函数进行预测,并使用 scores2label 函数将分数转换为标签。默认情况下,minibatchpredict 函数使用 GPU(如果有)。
scores = minibatchpredict(net,XTest); YTest = scores2label(scores,classNames);
在混淆图中显示分类结果。
figure confusionchart(TTest,YTest)

另请参阅
trainnet | trainingOptions | dlnetwork | lstmLayer | bilstmLayer | sequenceInputLayer