长短期记忆神经网络
本主题说明如何使用长短期记忆 (LSTM) 神经网络处理分类和回归任务的序列和时间序列数据。有关如何使用 LSTM 神经网络对序列数据进行分类的示例,请参阅使用深度学习进行序列分类。
LSTM 神经网络是一种循环神经网络 (RNN),可以学习序列数据的时间步之间的长期依赖关系。
LSTM 神经网络架构
LSTM 神经网络的核心组件是序列输入层和 LSTM 层。序列输入层将序列或时间序列数据输入神经网络中。LSTM 层学习序列数据的时间步之间的长期相关性。
下图说明用于分类的简单 LSTM 网络的架构。该神经网络从一个序列输入层开始,后跟一个 LSTM 层。为了预测类标签,该神经网络的末尾是一个全连接层和一个 softmax 层。

下图说明用于回归的简单 LSTM 神经网络的架构。该神经网络从一个序列输入层开始,后跟一个 LSTM 层。该神经网络的末尾是一个全连接层。

分类 LSTM 网络
要创建针对“序列到标签”分类的 LSTM 网络,请创建一个层数组,其中包含一个序列输入层、一个 LSTM 层、一个全连接层和一个 softmax 层。
将序列输入层的大小设置为输入数据的特征数量。将全连接层的大小设置为类的数量。您不需要指定序列长度。
对于 LSTM 层,指定隐藏单元的数量和输出模式 "last"。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
有关说明如何针对“序列到标签”分类训练 LSTM 网络和对新数据进行分类的示例,请参阅使用深度学习进行序列分类。
要针对“序列到序列”分类创建一个 LSTM 网络,请使用与序列到标签分类相同的架构,但将 LSTM 层的输出模式设置为 "sequence"。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
回归 LSTM 网络
要针对“序列到单个”回归创建一个 LSTM 网络,请创建一个层数组,其中包含一个序列输入层、一个 LSTM 层和一个全连接层。
将序列输入层的大小设置为输入数据的特征数量。将全连接层的大小设置为响应的数量。您不需要指定序列长度。
训练神经网络时,您可以使用 NormalizeTargets 训练选项(在 R2026a 中引入)自动对训练目标进行归一化。使用归一化目标有助于稳定训练,并使训练预测值与归一化目标高度匹配。若仅需神经网络在预测阶段输出未归一化值空间中的预测值,可添加反归一化层(在 R2026a 中引入)。在 R2026a 之前:为稳定训练,可在训练神经网络前手动对目标进行归一化。
对于 LSTM 层,指定隐藏单元的数量和输出模式 "last"。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
要针对“序列到序列”回归创建一个 LSTM 网络,请使用与“序列到单个”回归相同的架构,但将 LSTM 层的输出模式设置为 "sequence"。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
有关说明如何针对“序列到序列”回归训练 LSTM 网络和对新数据进行预测的示例,请参阅使用深度学习进行“序列到序列”回归。
视频分类网络
要针对包含图像序列的数据(如视频数据和医学图像)创建一个深度学习网络,请使用序列输入层指定图像序列输入。
指定层并创建一个 dlnetwork 对象。
inputSize = [64 64 3];
filterSize = 5;
numFilters = 20;
numHiddenUnits = 200;
numClasses = 10;
layers = [
sequenceInputLayer(inputSize)
convolution2dLayer(filterSize,numFilters)
batchNormalizationLayer
reluLayer
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = dlnetwork(layers);有关说明如何针对视频分类训练深度学习网络的示例,请参阅使用深度学习对视频进行分类。
更深的 LSTM 网络
您可以通过在 LSTM 层之前插入具有输出模式 "sequence" 的额外 LSTM 层来加大 LSTM 网络的深度。为了防止过拟合,可以在 LSTM 层后插入丢弃层。
对于“序列到标签”分类网络,最后一个 LSTM 层的输出模式必须为 "last"。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
对于“序列到序列”分类网络,最后一个 LSTM 层的输出模式必须为 "sequence"。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
网络层
| 图标 | 层 | 描述 |
|---|---|---|
| 序列输入层向神经网络输入序列数据并应用数据归一化。 | |
| 嵌入层将数值索引转换为数值向量,其中索引对应于离散数据。 | |
| LSTM 层是一个 RNN 层,该层学习时间序列和序列数据中时间步之间的长期相关性。 | ||
| LSTM 投影层是一个 RNN 层,该层使用投影的可学习权重来学习时间序列和序列数据中时间步之间的长期相关性。 | ||
| 双向 LSTM (BiLSTM) 层是一个 RNN 层,该层学习时间序列或序列数据的时间步之间的双向长期相关性。当您希望 RNN 在每个时间步从完整时间序列中学习时,这些相关性会很有用。 | ||
| GRU 层是一个 RNN 层,它学习时间序列和序列数据中时间步之间的相关性。 | ||
| GRU 投影层是一个 RNN 层,它使用投影的可学习权重来学习时间序列中的时间步和序列数据之间的相关性。 | ||
| 一维卷积层将滑动卷积滤波器应用于一维输入。 | ||
| 转置的一维卷积层对一维特征图进行上采样。 | ||
| 一维最大池化层通过将输入划分为一维池化区域并计算每个区域的最大值来执行下采样。 | ||
| 一维平均池化层通过将输入划分为若干一维池化区域,然后计算每个区域的平均值来执行下采样。 | ||
| 一维全局最大池化层通过输出输入的时间或空间维度的最大值来执行下采样。 | ||
| 展平层将输入的空间维度折叠成通道维度。 | ||
| 单词嵌入层将单词索引映射到向量。 | |
| 窥视孔 LSTM 层是 LSTM 层的变体,其中门计算使用层单元状态。 |

分类、预测和预报
要对新数据进行预测,请使用 minibatchpredict 函数。要将预测分类分数转换为标签,请使用 scores2label。
LSTM 神经网络可以记住各次预测之间的神经网络状态。如果您事先没有完整的时间序列,或您要对一个长时间序列进行多次预测,则 RNN 状态会很有用。
要对部分时间序列进行预测和分类并更新 RNN 状态,请使用 predict 函数,同时返回并更新神经网络状态。要重置各预测之间的 RNN 状态,请使用 resetState。
有关如何预测序列的将来时间步的示例,请参阅使用深度学习进行时间序列预测。
序列填充和截断
LSTM 神经网络支持具有不同序列长度的输入数据。当使数据通过神经网络时,软件会填充或截断序列,以便每个小批量中的所有序列都具有指定的长度。您可以使用 SequenceLength 和 SequencePaddingValue 训练选项来指定序列长度和用于填充序列的值。
训练神经网络后,在使用 minibatchpredict 函数时,可以使用相同的小批量大小和填充选项。
按长度对序列排序
要在填充或截断序列时减少填充或丢弃的数据量,请尝试按序列长度对数据进行排序。对于第一个维度对应于时间步的序列,要按序列长度对数据进行排序,首先使用 cellfun 对每个序列应用 size(X,1) 来获得每个序列的列数。然后使用 sort 对序列长度进行排序,并使用第二个输出对原始序列重新排序。
sequenceLengths = cellfun(@(X) size(X,1), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);
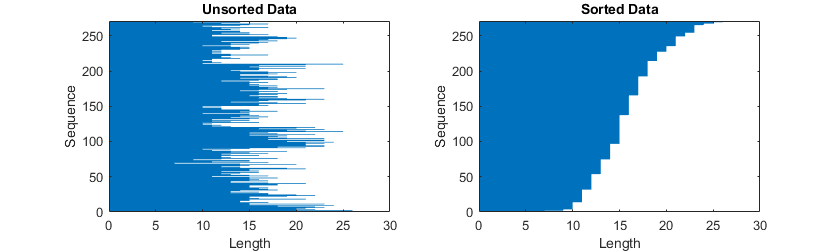
填充序列
如果 SequenceLength 训练或预测选项为 "longest",则软件会填充序列,使小批量中的所有序列具有与小批量中的最长序列相同的长度。此选项是默认选项。

截断序列
如果 SequenceLength 训练或预测选项为 "shortest",则软件会截断序列,使小批量中的所有序列具有与该小批量中的最短序列相同的长度。序列中的其余数据被丢弃。
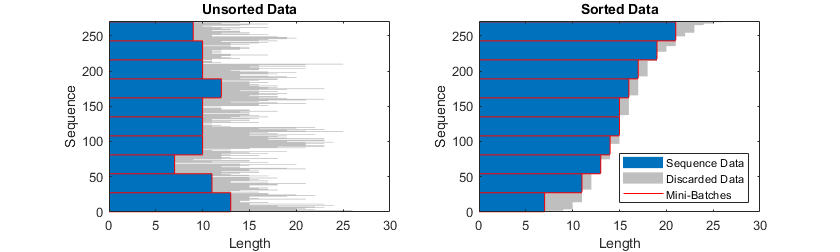
指定填充方向
填充和截断的位置会影响训练、分类和预测准确度。请尝试将 SequencePaddingDirection 训练选项设置为 "left" 或 "right",看看哪个最适合您的数据。
循环层一次处理一个时间步的序列数据,因此当循环层 OutputMode 属性为 "last" 时,最终时间步中的任何填充都会对层输出产生负面影响。要填充或截断左侧的序列数据,请将 SequencePaddingDirection 名称-值参量设置为 "left"。
对于“序列到序列”神经网络(当每个循环层的 OutputMode 属性为 "sequence" 时),前几个时间步中的任何填充都会对较早时间步的预测产生负面影响。要填充或截断右侧的序列数据,请将 SequencePaddingDirection 名称-值参量设置为 "right"。


归一化序列数据
要在训练时使用以零为中心的归一化自动对训练数据调整中心位置,请将 sequenceInputLayer 的 Normalization 选项设置为 "zerocenter"。您也可以通过首先计算所有序列的每个特征的均值和标准差来归一化序列数据。然后,对于每个训练观测值,减去均值并除以标准差。
mu = mean([XTrain{:}],1);
sigma = std([XTrain{:}],0,1);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,UniformOutput=false);无法放入内存的数据
如果数据太大而无法放入内存或在读取批量数据时无法执行特定操作,请对序列、时间序列和信号数据使用数据存储。
要了解详细信息,请参阅使用无法放入内存的序列数据训练网络和使用深度学习对无法放入内存的文本数据进行分类。
可视化
通过使用 minibatchpredict 函数提取激活值并设置 Outputs 参量,调查并可视化 LSTM 神经网络从序列和时间序列数据中学习到的特征。要了解详细信息,请参阅可视化 LSTM 网络的激活值。
LSTM 层架构
以下是数据流通过 LSTM 层的示意图,其中输入为 、输出为 、时间步数为 T。在图中, 表示在时间步 t 的输出(也称为隐藏状态), 表示在该时间步的单元状态。
如果层输出完整序列,则它输出 、…、,等效于 、…、。如果该层仅输出最后一个时间步,则该层输出 ,等效于 。输出中的通道数量与 LSTM 层的隐藏单元数量匹配。
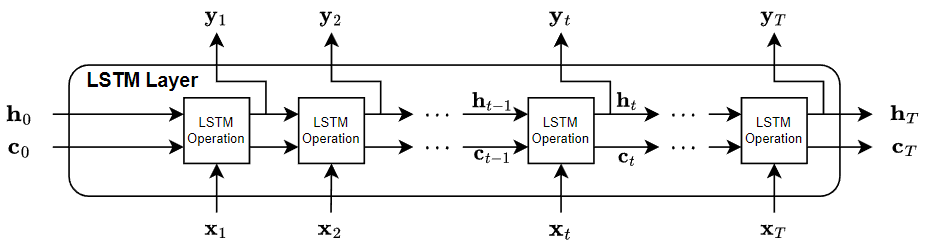
第一个 LSTM 运算使用 RNN 的初始状态和序列的第一个时间步来计算第一个输出和更新后的单元状态。在时间步 t 上,该运算使用 RNN 的当前状态 和序列的下一个时间步来计算输出和更新后的单元状态 。
该层的状态由隐藏状态(也称为输出状态)和单元状态组成。时间步 t 处的隐藏状态包含该时间步的 LSTM 层的输出。单元状态包含从前面的时间步中获得的信息。在每个时间步,该层都会在单元状态中添加或删除信息。该层使用不同的门控制这些更新。
以下组件控制层的单元状态和隐藏状态。
| 组件 | 目的 |
|---|---|
| 输入门 (i) | 控制单元状态更新的级别 |
| 遗忘门 (f) | 控制单元状态重置(遗忘)的级别 |
| 候选单元 (g) | 向单元状态添加信息 |
| 输出门 (o) | 控制添加到隐藏状态的单元状态的级别 |
下图说明在时间步 t 上的数据流。此图显示门如何遗忘、更新和输出单元状态和隐藏状态。
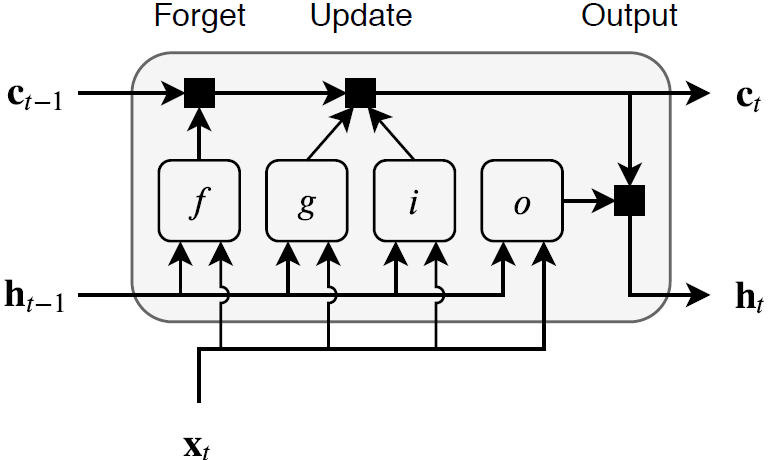
LSTM 层的可学习权重包括输入权重 W (InputWeights)、循环权重 R (RecurrentWeights) 以及偏置 b (Bias)。矩阵 W、R 和 b 分别是输入权重、循环权重和每个分量的偏置的串联。该层根据以下方程串联矩阵:
其中 i、f、g、o 分别表示输入门、遗忘门、候选单元和输出门。
时间步 t 处的单元状态由下式给出:
其中 表示哈达玛乘积(向量的按元素乘法)。
时间步 t 处的隐藏状态由下式给出:
其中 表示状态激活函数。默认情况下,lstmLayer 函数使用双曲正切函数 (tanh) 计算状态激活函数。
以下公式说明时间步 t 处的组件。
| 组件 | 公式 |
|---|---|
| 输入门 | |
| 遗忘门 | |
| 候选单元 | |
| 输出门 |
在这些计算中, 表示门激活函数。默认情况下,lstmLayer 函数使用 给出的 sigmoid 函数来计算门激活函数。
参考
[1] Hochreiter, S., and J. Schmidhuber. "Long short-term memory." Neural computation. Vol. 9, Number 8, 1997, pp.1735–1780.
另请参阅
sequenceInputLayer | lstmLayer | bilstmLayer | gruLayer | dlnetwork | minibatchpredict | predict | scores2label | flattenLayer | wordEmbeddingLayer (Text Analytics Toolbox)