使用深度学习对视频进行分类
此示例说明如何通过将预训练图像分类模型和 LSTM 网络相结合来创建视频分类网络。
要为视频分类创建深度学习网络,请执行以下操作:
使用预训练卷积神经网络(如 GoogLeNet)将视频转换为特征向量序列,以从每帧中提取特征。
基于序列训练 LSTM 网络来预测视频标签。
通过合并来自两个网络的层,组合一个直接对视频进行分类的网络。
下图说明网络架构。
要将图像序列输入到网络,请使用序列输入层。
使用卷积层来提取特征,也就是说,将卷积运算独立地应用于视频的每个帧。
要对得到的向量序列进行分类,请包括 LSTM 层,并在其后添加输出层。

加载数据
从 HMDB51:大型人体运动识别视频数据库下载 HMBD51 数据集并将 RAR 文件解压缩到名为 "hmdb51_org" 的文件夹中。该数据集包含 51 个类的 7000 个片段、大约 2 GB 的视频数据,例如 "drink"、"run" 和 "shake_hands"。
提取 RAR 文件后,使用支持函数 hmdb51Files 获取视频的文件名和标签。
dataFolder = "hmdb51_org";
[files,labels] = hmdb51Files(dataFolder);
classNames = categories(labels);使用在此示例末尾定义的 readVideo 辅助函数读取第一段视频,并查看该视频的大小。该视频是 H×W×C×S 数组,其中 H、W、C 和 S 分别是视频的高度、宽度、通道数和帧数。
idx = 1; filename = files(idx); video = readVideo(filename); [height,width,numChannels,numFrames] = size(video);
查看对应的标签。
labels(idx)
ans = categorical
brush_hair
要查看视频,请使用 implay 函数(需要 Image Processing Toolbox™)。此函数需要数据在 [0,1] 范围内,因此您必须先将数据除以 255。您也可以遍历各个帧,并使用 imshow 函数。
figure for i = 1:numFrames frame = video(:,:,:,i); imshow(frame/255); drawnow end
加载预训练卷积网络
要将视频帧转换为特征向量,请使用预训练网络的激活值。
使用 imagePretrainedNetwork 函数加载预训练的 GoogLeNet 模型。此函数需要 Deep Learning Toolbox™ Model for GoogLeNet Network 支持包。如果未安装此支持包,则函数会提供下载链接。
netCNN = imagePretrainedNetwork("googlenet");将帧转换为特征向量
当将视频帧输入到网络时,通过获取激活值,将卷积网络用作特征提取器。将视频转换为特征向量序列,其中特征向量是 GoogLeNet 网络的最后一个池化层 ("pool5-7x7_s1") 的输出。
下图说明通过网络的数据流。

要读取视频数据并调整其大小以匹配 GoogLeNet 网络的输入大小,请使用在此示例末尾定义的 readVideo 和 centerCrop 辅助函数。此步骤可能需要很长时间才能完成运行。在将视频转换为序列后,将序列保存在 tempdir 文件夹的一个 MAT 文件中。如果该 MAT 文件已经存在,则从 MAT 文件加载序列,而不必重新转换它们。
inputSize = netCNN.Layers(1).InputSize(1:2); layerName = "pool5-7x7_s1"; tempFile = fullfile(tempdir,"hmdb51_org.mat"); if exist(tempFile,"file") load(tempFile,"sequences") else numFiles = numel(files); sequences = cell(numFiles,1); for i = 1:numFiles fprintf("Reading file %d of %d...\n", i, numFiles) video = readVideo(files(i)); video = centerCrop(video,inputSize); sequences{i,1} = predict(netCNN,video,Outputs=layerName); sequences{i,1} = squeeze(sequences{i,1})'; end save(tempFile,"sequences","-v7.3"); end
查看前几个序列的大小。每个序列都是一个 S×D 数组,其中 S 是视频的帧数,D 是特征数量(池化层的输出大小)。
sequences(1:10)
ans=10×1 cell array
{409×1024 single}
{395×1024 single}
{323×1024 single}
{246×1024 single}
{159×1024 single}
{137×1024 single}
{359×1024 single}
{191×1024 single}
{439×1024 single}
{528×1024 single}
准备训练数据
通过将数据划分为训练分区和验证分区并删除任何长序列,为训练准备数据。
创建训练分区和验证分区
对数据进行分区。将 90% 的数据分配给训练分区,将 10% 分配给验证分区。
numObservations = numel(sequences); idx = randperm(numObservations); N = floor(0.9 * numObservations); idxTrain = idx(1:N); sequencesTrain = sequences(idxTrain); labelsTrain = labels(idxTrain); idxValidation = idx(N+1:end); sequencesValidation = sequences(idxValidation); labelsValidation = labels(idxValidation);
删除长序列
比网络中典型序列长得多的序列会在训练过程中引入大量填充。填充过多会对分类准确度产生负面影响。
获取训练数据的序列长度,并在训练数据的直方图中可视化它们。
numObservationsTrain = numel(sequencesTrain); sequenceLengths = zeros(1,numObservationsTrain); for i = 1:numObservationsTrain sequence = sequencesTrain{i}; sequenceLengths(i) = size(sequence,1); end figure histogram(sequenceLengths) title("Sequence Lengths") xlabel("Sequence Length") ylabel("Frequency")
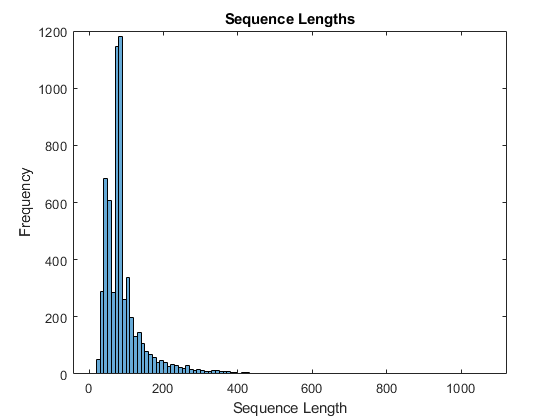
只有少数序列有超过 400 个时间步。为了提高分类准确度,请删除具有超过 400 个时间步的训练序列及其对应的标签。
maxLength = 400; idx = sequenceLengths > maxLength; sequencesTrain(idx) = []; labelsTrain(idx) = [];
创建 LSTM 网络
接下来,创建一个 LSTM 网络,它可以对表示视频的特征向量的序列进行分类。
定义 LSTM 网络架构。指定以下网络层。
序列输入层,其输入大小对应于特征向量的特征维度。
具有 2000 个隐藏单元的 BiLSTM 层,后跟一个丢弃层。通过将 BiLSTM 层的
OutputMode选项设置为"last",为每个序列仅输出一个标签。输出大小对应于类数量的全连接层,以及 softmax 层。
numFeatures = size(sequencesTrain{1},2);
numClasses = numel(categories(labelsTrain));
layers = [
sequenceInputLayer(numFeatures,Name="sequence")
bilstmLayer(2000,OutputMode="last",Name="bilstm")
dropoutLayer(0.5,Name="drop")
fullyConnectedLayer(numClasses,Name="fc")
softmaxLayer(Name="softmax")];指定训练选项
使用 trainingOptions 函数指定训练选项。
将小批量大小设置为 32,初始学习率设置为 0.0001,梯度阈值设置为 2(以防止梯度爆炸)。
每轮训练都会打乱数据。
每轮训练后对网络进行一次验证。
如果验证损失大于或等于之前五轮的最小值,则停止训练。
在绘图中显示训练进度(包括网络的准确度),并隐藏详尽输出。
miniBatchSize = 32; numObservations = numel(sequencesTrain); numIterationsPerEpoch = floor(numObservations / miniBatchSize); options = trainingOptions("adam", ... MiniBatchSize=miniBatchSize, ... InitialLearnRate=1e-4, ... GradientThreshold=2, ... Shuffle="every-epoch", ... ValidationData={sequencesValidation,labelsValidation}, ... ValidationFrequency=numIterationsPerEpoch, ... ValidationPatience=5, ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
训练 LSTM 网络
使用 trainnet 函数训练网络。这可能需要很长时间才能运行完毕。默认情况下,trainnet 函数使用 GPU(如果有)。在 GPU 上进行训练需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet 函数使用 CPU。要手动选择执行环境,请使用 ExecutionEnvironment 训练选项。
[netLSTM,info] = trainnet(sequencesTrain,labelsTrain,layers,"crossentropy",options);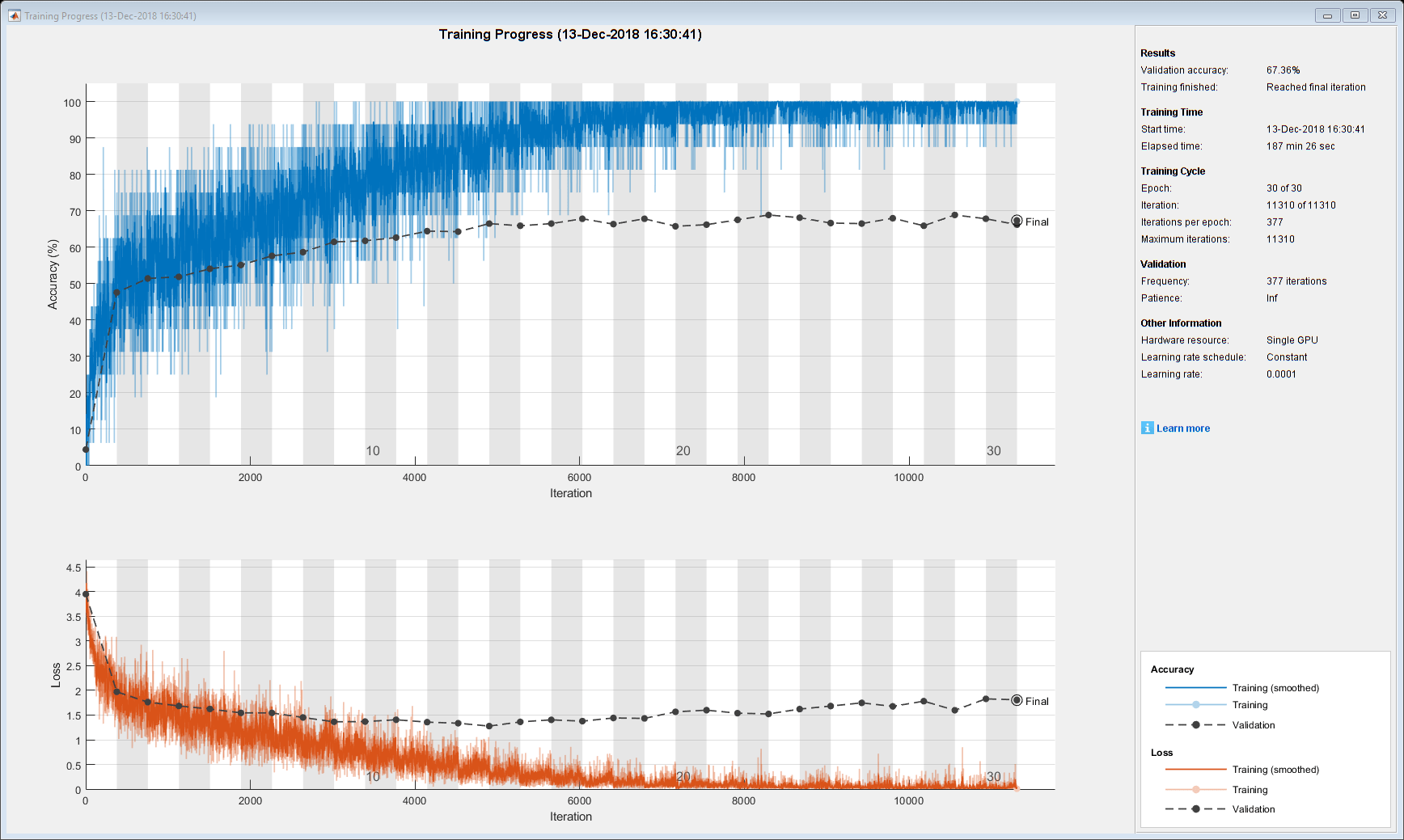
基于验证集计算网络分类准确度。使用与训练选项相同的小批量大小。
accuracy = testnet(netLSTM,sequencesValidation,labelsValidation,"accuracy",MiniBatchSize=miniBatchSize)accuracy = 65.7312
组合视频分类网络
要创建直接对视频进行分类的网络,请用创建的两个网络中的层组合成一个网络。使用来自卷积网络的层将视频变换为向量序列,使用来自 LSTM 网络的层对向量序列进行分类。
下图说明网络架构。
要将图像序列输入到网络,请使用序列输入层。
要提取特征,请使用卷积层。
要对得到的向量序列进行分类,请包括 LSTM 层,并在其后添加输出层。输出层(有时称为模型头)包括最终的全连接层和 softmax 层。

添加卷积层
提取输入层的平均图像,序列输入层将使用该图像来归一化图像。
averageImage = netCNN.Layers(1).Mean;
删除输入层 ("data") 和用于激活的池化层之后的层("pool5-drop_7x7_s1"、"loss3-classifier" 和 "prob")。
layerNames = ["data" "pool5-drop_7x7_s1" "loss3-classifier" "prob"]; net = removeLayers(netCNN,layerNames);
添加序列输入层
创建一个序列输入层,它接受包含与 GoogLeNet 网络输入大小相同的图像的图像序列。要使用与 GoogLeNet 网络相同的平均图像归一化图像,请将序列输入层的 Normalization 选项设置为 "zerocenter",将 Mean 选项设置为 GoogLeNet 输入层的平均图像。
inputLayer = sequenceInputLayer([inputSize 3], ... Normalization="zerocenter", ... Mean=averageImage, ... Name="input");
将序列输入层添加到网络中,并将其输出连接到第一个卷积层 ("conv1-7x7_s2") 的输入。
net = addLayers(net,inputLayer); net = connectLayers(net,"input/out","conv1-7x7_s2/in");
添加 LSTM 层
从 LSTM 网络中提取层,并删除序列输入层。
lstmLayers = netLSTM.Layers; lstmLayers(1) = [];
将 LSTM 层添加到网络中。将最后一个卷积层 ("pool5-7x7_s1") 连接到 BiLSTM 层 ("bilstm/in") 的输入。
net = addLayers(net,lstmLayers); net = connectLayers(net,"pool5-7x7_s1/out","bilstm/in");
检查网络
使用 analyzeNetwork 函数检查网络是否有效。
analyzeNetwork(net)

使用新数据进行分类
使用与之前相同的步骤读取并居中裁剪视频 "pushup.mp4"。
filename = "pushup.mp4";
video = readVideo(filename);要查看视频,请使用 implay 函数(需要 Image Processing Toolbox)。此函数需要数据在 [0,1] 范围内,因此您必须先将数据除以 255。您也可以遍历各个帧,并使用 imshow 函数。
numFrames = size(video,4); figure for i = 1:numFrames frame = video(:,:,:,i); imshow(frame/255); drawnow end

初始化网络,并使用它对视频进行分类。
net = initialize(net); video = centerCrop(video,inputSize); scoresPred = predict(net,video); Y = scores2label(scoresPred,classNames)
Y = categorical
pushup
辅助函数
readVideo 函数读取 filename 中的视频,并返回一个 H×W×C×S 数组,其中 H、W、C 和 S 分别是视频的高度、宽度、通道数和帧数。
function video = readVideo(filename) vr = VideoReader(filename); H = vr.Height; W = vr.Width; C = 3; % Preallocate video array numFrames = floor(vr.Duration * vr.FrameRate); video = zeros(H,W,C,numFrames); % Read frames i = 0; while hasFrame(vr) i = i + 1; video(:,:,:,i) = readFrame(vr); end % Remove unallocated frames if size(video,4) > i video(:,:,:,i+1:end) = []; end end
centerCrop 函数裁剪视频的最长边,并将其大小调整为 inputSize 的大小。
function videoResized = centerCrop(video,inputSize) [height,width] = size(video,1:2); if height < width % Video is landscape idx = floor((width - height)/2); video(:,1:(idx-1),:,:) = []; video(:,(height+1):end,:,:) = []; elseif width < height % Video is portrait idx = floor((height - width)/2); video(1:(idx-1),:,:,:) = []; video(width+1:end,:,:,:) = []; end videoResized = imresize(video,inputSize(1:2)); end
另请参阅
trainnet | trainingOptions | dlnetwork | lstmLayer | sequenceInputLayer | flattenLayer