定义自定义深度学习层
提示
本主题说明如何针对您的问题定义自定义深度学习层。有关 Deep Learning Toolbox™ 中的内置层的列表,请参阅深度学习层列表。
如果 Deep Learning Toolbox 没有提供您的任务所需的层,您可以使用本主题作为指南来定义自己的自定义层。定义自定义层后,您可以自动检查该层是否有效,是否与 GPU 兼容,以及是否输出正确定义的梯度。
神经网络层架构
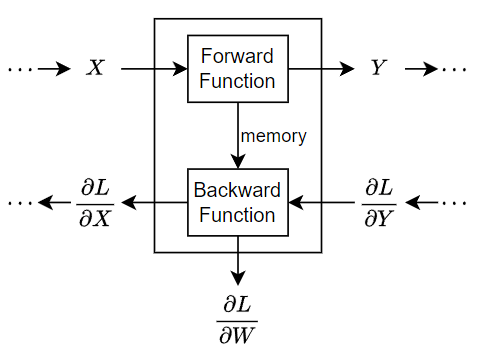
在训练过程中,软件在网络中以迭代方式执行前向传导和后向传导。
在网络的前向传导过程中,每个层获取前面各层的输出,应用一个函数,然后将结果输出(正向传播)到后面各层。有状态的层(如 LSTM 层)也会更新层状态。
层可以有多个输入或输出。例如,层可以从多个前面的层中获取 X1、…、XN,并将输出 Y1、…、YM 正向传播到后续各层。
在执行网络的前向传导结束时,软件计算预测值和目标值之间的损失 L。
在网络的后向传导过程中,每个层都接受损失关于该层的输出的导数,计算损失 L 关于输入的导数,然后反向传播结果。如果层具有可学习参数,则该层还会计算损失关于层权重(可学习参数)的导数。该软件使用这些导数来更新可学习参数。为了节省计算量,前向函数可以使用可选的内存输出与后向函数共享信息。
下图说明通过深度神经网络的数据流,重点显示通过具有单个输入 X、单个输出 Y 和可学习参数 W 的层的数据流。
自定义层模板
要定义自定义层,请使用此类定义模板。此模板提供了自定义层类定义的结构。其大致内容如下:
classdef myLayer < nnet.layer.Layer % ... % & nnet.layer.Formattable ... % (Optional) % & nnet.layer.Acceleratable % (Optional) properties % (Optional) Layer properties. % Declare layer properties here. end properties (Learnable) % (Optional) Layer learnable parameters. % Declare learnable parameters here. end properties (State) % (Optional) Layer state parameters. % Declare state parameters here. end properties (Learnable, State) % (Optional) Nested dlnetwork objects with both learnable % parameters and state parameters. % Declare nested networks with learnable and state parameters here. end methods function layer = myLayer() % (Optional) Create a myLayer. % This function must have the same name as the class. % Define layer constructor function here. end function layer = initialize(layer,layout) % (Optional) Initialize layer learnable and state parameters. % % Inputs: % layer - Layer to initialize % layout - Data layout, specified as a networkDataLayout % object % % Outputs: % layer - Initialized layer % % - For layers with multiple inputs, replace layout with % layout1,...,layoutN, where N is the number of inputs. % Define layer initialization function here. end function [Y,state] = predict(layer,X) % Forward input data through the layer at prediction time and % output the result and updated state. % % Inputs: % layer - Layer to forward propagate through % X - Input data % Outputs: % Y - Output of layer forward function % state - (Optional) Updated layer state % % - For layers with multiple inputs, replace X with X1,...,XN, % where N is the number of inputs. % - For layers with multiple outputs, replace Y with % Y1,...,YM, where M is the number of outputs. % - For layers with multiple state parameters, replace state % with state1,...,stateK, where K is the number of state % parameters. % Define layer predict function here. end function [Y,state,memory] = forward(layer,X) % (Optional) Forward input data through the layer at training % time and output the result, the updated state, and a memory % value. % % Inputs: % layer - Layer to forward propagate through % X - Layer input data % Outputs: % Y - Output of layer forward function % state - (Optional) Updated layer state % memory - (Optional) Memory value for custom backward % function % % - For layers with multiple inputs, replace X with X1,...,XN, % where N is the number of inputs. % - For layers with multiple outputs, replace Y with % Y1,...,YM, where M is the number of outputs. % - For layers with multiple state parameters, replace state % with state1,...,stateK, where K is the number of state % parameters. % Define layer forward function here. end function layer = resetState(layer) % (Optional) Reset layer state. % Define reset state function here. end function [dLdX,dLdW,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory) % (Optional) Backward propagate the derivative of the loss % function through the layer. % % Inputs: % layer - Layer to backward propagate through % X - Layer input data % Y - Layer output data % dLdY - Derivative of loss with respect to layer % output % dLdSout - (Optional) Derivative of loss with respect % to state output % memory - Memory value from forward function % Outputs: % dLdX - Derivative of loss with respect to layer input % dLdW - (Optional) Derivative of loss with respect to % learnable parameter % dLdSin - (Optional) Derivative of loss with respect to % state input % % - For layers with state parameters, the backward syntax must % include both dLdSout and dLdSin, or neither. % - For layers with multiple inputs, replace X and dLdX with % X1,...,XN and dLdX1,...,dLdXN, respectively, where N is % the number of inputs. % - For layers with multiple outputs, replace Y and dLdY with % Y1,...,YM and dLdY,...,dLdYM, respectively, where M is the % number of outputs. % - For layers with multiple learnable parameters, replace % dLdW with dLdW1,...,dLdWP, where P is the number of % learnable parameters. % - For layers with multiple state parameters, replace dLdSin % and dLdSout with dLdSin1,...,dLdSinK and % dLdSout1,...,dldSoutK, respectively, where K is the number % of state parameters. % Define layer backward function here. end end end
格式化的输入和输出
通过使用 dlarray 对象,您可以标注维度,从而简化高维数据的处理。例如,您可以分别使用 "S"、"T"、"C" 和 "B" 标签来标记哪些维度对应于空间维度、时间维度、通道维度和批量维度。对于未指定的维度和其他维度,请使用 "U" 标签。对于在特定维度上操作的 dlarray 对象函数,您可以通过直接格式化 dlarray 对象或使用 DataFormat 选项来指定维度标签。
通过在层函数中使用格式化的 dlarray 对象,您也可以定义输入和输出具有不同格式的层,例如置换、添加或删除维度的层。例如,您可以定义一个层,该层将格式为 "SSCB"(空间、空间、通道、批量)的小批量图像作为输入,并将格式为 "CBT"(通道、批量、时间)的小批量序列作为输出。通过使用格式化的 dlarray 对象,您还可以定义可对不同输入格式的数据进行操作的层,例如,支持格式为 "SSCB"(空间、空间、通道、批量)和 "CBT"(通道、批量、时间)的输入的层。
您可以通过选择从 ᦙ nnet.layer.Formattable 类继承来指定如何处理在软件与层之间传递的格式化数据和未格式化数据。下表说明了软件如何处理自定义层中的格式化数据和未格式化数据。
| 层定义 | 输入数据处理 | 输出数据处理 |
|---|---|---|
从 nnet.layer.Formattable 继承 | 软件会直接将层输入传递给层函数:
| 软件会直接将层函数输出传递给后续层:
警告 对于从 在 R2026a 之前的版本中: 该层会自动将输入数据的格式应用于未格式化输出数据。
|
不从 nnet.layer.Formattable 继承 | 软件会去除任何格式化输入的格式并将未格式化数据传递给层函数:
| 输出数据必须为未格式化数据。软件会将层输入的格式应用于任何未格式化的层函数输出,并将结果传递给后续层:
|
有关如何定义具有格式化输入的自定义层的示例,请参阅Define Custom Deep Learning Layer with Formatted Inputs。
自定义层加速
如果在定义自定义层时未指定后向函数,该软件会使用自动微分自动确定梯度。
当在不使用后向函数的情况下训练具有自定义层的网络时,该软件会跟踪自定义层前向函数的每个输入 dlarray 对象,以确定用于自动微分的计算图。此跟踪过程可能会花费一些时间,最终可能会重新计算相同的跟踪。通过优化、缓存和重用跟踪,您可以在训练网络时加快梯度计算的速度。该软件还可以在训练后重用这些跟踪来加速网络预测。
跟踪取决于层输入的大小、格式和基础数据类型。也就是说,层会针对缓存中不包含大小、格式或基础数据类型的输入触发新跟踪。任何输入,如果只是值与先前缓存的跟踪不同,则不会触发新跟踪。
要指示自定义层支持加速,请在定义自定义层时也指示从 nnet.layer.Acceleratable 类继承。当自定义层从 nnet.layer.Acceleratable 继承时,该软件会在通过 dlnetwork 对象传递数据时自动缓存跟踪。
例如,要指示自定义层 myLayer 支持加速,请使用以下语法
classdef myLayer < nnet.layer.Layer & nnet.layer.Acceleratable ... end
加速注意事项
基于缓存跟踪的性质,并非所有函数都支持加速。
缓存过程可以缓存您可能期望更改或取决于外部因素的值或代码结构。加速符合以下条件的自定义层时必须小心:
生成随机数。
使用
if语句和while循环,其条件取决于dlarray对象的值。
由于缓存过程需要额外的计算,在某些情况下,加速会导致代码运行时间较长。当该软件花费时间创建不经常重用的新缓存时,可能就会出现这种情况。例如,当您向函数传递具有不同序列长度的多个小批量时,该软件会针对每个唯一序列长度触发新跟踪。
当自定义层加速导致速度变慢时,您可以通过以下方式禁用自定义层加速:删除 Acceleratable 类,或通过将 Acceleration 选项设置为 "none" 来禁用 dlnetwork 对象函数 predict 和 forward 的加速。
有关为自定义层启用加速支持的详细信息,请参阅Custom Layer Function Acceleration。
自定义层属性
在类定义的 properties 部分声明层属性。
默认情况下,自定义层具有下列属性。请不要在 properties 部分中声明这些属性。
| 属性 | 描述 |
|---|---|
Name | 层名称,指定为字符向量或字符串标量。对于 Layer 数组输入,trainnet 和 dlnetwork 函数会自动为未命名层指定名称。 |
Description | 层的单行描述,指定为字符串标量或字符向量。当您显示 如果没有指定层描述,则软件将显示层类名。 |
Type | 层的类型,指定为字符向量或字符串标量。当层显示在 如果没有指定层类型,则软件将显示层类名。 |
NumInputs | 层的输入的数量,指定为正整数。如果您未指定此值,软件会自动将 NumInputs 设置为 InputNames 中的名称的数量。默认值为 1。 |
InputNames | 层的输入名称,指定为字符向量元胞数组。如果您未指定此值并且 NumInputs 大于 1,则软件会自动将 InputNames 设置为 {'in1',...,'inN'},其中 N 等于 NumInputs。默认值为 {'in'}。 |
NumOutputs | 层的输出的数量,指定为正整数。如果您未指定此值,软件会自动将 NumOutputs 设置为 OutputNames 中的名称的数量。默认值为 1。 |
OutputNames | 层的输出名称,指定为字符向量元胞数组。如果您未指定此值并且 NumOutputs 大于 1,则软件会自动将 OutputNames 设置为 {'out1',...,'outM'},其中 M 等于 NumOutputs。默认值为 {'out'}。 |
如果层没有其他属性,则您可以省略 properties 部分。
提示
如果要创建一个具有多个输入的层,则必须在层构造函数中设置 NumInputs 或 InputNames 属性。如果要创建一个具有多个输出的层,则必须在层构造函数中设置 NumOutputs 或 OutputNames 属性。有关示例,请参阅Define Custom Deep Learning Layer with Multiple Inputs。
可学习参数
在类定义的 properties (Learnable) 部分声明层可学习参数。
您可以将数值数组或 dlnetwork 对象指定为可学习参数。如果 dlnetwork 对象同时具有可学习参数和状态参数(例如,包含 LSTM 层的 dlnetwork 对象),您必须在 properties (Learnable, State) 部分中指定它。如果层没有可学习参数,则可以省略带有 Learnable 属性的 properties 部分。
您也可以指定可学习参数的学习率因子和 L2 因子。默认情况下,每个可学习参数的学习率因子和 L2 因子都设置为 1。对于内置层和自定义层,可以使用以下函数设置和获取学习率因子和 L2 正则化因子。
| 函数 | 描述 |
|---|---|
setLearnRateFactor | 设置可学习参数的学习率因子。 |
setL2Factor | 设置可学习参数的 L2 正则化因子。 |
getLearnRateFactor | 获取可学习参数的学习率因子。 |
getL2Factor | 获取可学习参数的 L2 正则化因子。 |
要指定可学习参数的学习率因子和 L2 因子,请分别使用语法 layer = setLearnRateFactor(layer,parameterName,value) 和 layer = setL2Factor(layer,parameterName,value)。
要获得可学习参数的学习率因子和 L2 因子的值,请分别使用语法 getLearnRateFactor(layer,parameterName) 和 getL2Factor(layer,parameterName)。
例如,此语法将可学习参数 "Alpha" 的学习率因子设置为 0.1。
layer = setLearnRateFactor(layer,"Alpha",0.1);状态参数
对于有状态层,如循环层,请在类定义的 properties (State) 部分中声明层状态参数。如果可学习参数是同时具有可学习参数和状态参数的 dlnetwork 对象(例如,包含 LSTM 层的 dlnetwork 对象),则您必须在 properties (Learnable, State) 部分中指定对应的属性。如果层没有状态参数,则可以省略具有 State 属性的 properties 部分。
如果层有状态参数,则前向函数必须同时返回更新后的层状态。有关详细信息,请参阅前向函数。
要指定自定义重置状态函数,请在类定义中包含语法为 layer = resetState(layer) 的函数。有关详细信息,请参阅重置状态函数。
不支持使用 trainnet 函数对包含具有状态参数的自定义层的网络进行并行训练。使用具有状态参数的自定义层训练网络时,ExecutionEnvironment 训练选项必须为 "auto"、"gpu" 或 "cpu"。
可学习参数和状态参数初始化
您可以指定在层构造函数或自定义 initialize 函数中初始化层的可学习参数和状态参数:
如果可学习参数或状态参数初始化不需要来自层输入的大小信息,例如,加权加法层的可学习权重是大小与层输入数匹配的向量,则您可以在层构造函数中初始化权重。有关示例,请参阅Define Custom Deep Learning Layer with Multiple Inputs。
如果可学习参数或状态参数初始化需要来自层输入的大小信息,例如,SReLU 层的可学习权重是大小与输入数据的通道数匹配的向量,则您可以在利用输入数据布局相关信息的自定义初始化函数中初始化权重。有关示例,请参阅Define Custom Deep Learning Layer with Learnable Parameters。
前向函数
一些层在训练期间的行为和其在预测期间的行为是不同的。例如,丢弃层仅在训练期间执行丢弃,在预测期间不起作用。层使用 predict 或 forward 函数来执行前向传导。如果前向传导在预测时间进行,则该层使用 predict 函数。如果前向传导在训练时进行,则该层使用 forward 函数。如果不需要对预测时间和训练时间使用两个不同函数,则可以省略 forward 函数。执行此操作时,该层在训练时使用 predict。
如果层具有状态参数,则前向函数还必须以数值数组形式返回更新后的层状态参数。
如果您同时定义自定义 forward 函数和自定义 backward 函数,则前向函数必须返回 memory 输出。
predict 函数语法取决于层的类型。
Y = predict(layer,X)通过层对输入数据X进行前向传播处理并输出结果Y,其中layer只有一个输入和一个输出。[Y,state] = predict(layer,X)还输出更新后的状态参数state,其中layer只有一个状态参数。
您可以针对具有多个输入、多个输出或多个状态参数的层调整语法:
对于具有多个输入的层,请将
X替换为X1,...,XN,其中N是输入的数量。NumInputs属性必须与N匹配。对于具有多个输出的层,请将
Y替换为Y1,...,YM,其中M是输出的数量。NumOutputs属性必须与M匹配。对于具有多个状态参数的层,请将
state替换为state1,...,stateK,其中K是状态参数的数量。
提示
如果该层的输入的数量可能变化,则使用 varargin 代替 X1,…,XN。在本例中,varargin 是由输入组成的元胞数组,其中 varargin{i} 对应于 Xi。
如果输出的数量可能变化,则使用 varargout 代替 Y1,…,YM。在本例中,varargout 是由输出组成的元胞数组,其中 varargout{j} 对应于 Yj。
提示
如果自定义层具有一个作为可学习参数的 dlnetwork 对象,则在自定义层的 predict 函数中,应对 dlnetwork 使用 predict 函数。在执行此操作时,dlnetwork 对象 predict 函数使用适当的层运算进行预测。如果 dlnetwork 具有状态参数,则同时返回网络状态。
forward 函数语法取决于层的类型:
Y = forward(layer,X)通过层对输入数据X进行前向传播处理并输出结果Y,其中layer只有一个输入和一个输出。[Y,state] = forward(layer,X)还输出更新后的状态参数state,其中layer只有一个状态参数。[__,memory] = forward(layer,X)还使用上述任一语法返回自定义backward函数的内存值。如果层同时具有自定义forward函数和自定义backward函数,则前向函数必须返回内存值。
您可以针对具有多个输入、多个输出或多个状态参数的层调整语法:
对于具有多个输入的层,请将
X替换为X1,...,XN,其中N是输入的数量。NumInputs属性必须与N匹配。对于具有多个输出的层,请将
Y替换为Y1,...,YM,其中M是输出的数量。NumOutputs属性必须与M匹配。对于具有多个状态参数的层,请将
state替换为state1,...,stateK,其中K是状态参数的数量。
提示
如果该层的输入的数量可能变化,则使用 varargin 代替 X1,…,XN。在本例中,varargin 是由输入组成的元胞数组,其中 varargin{i} 对应于 Xi。
如果输出的数量可能变化,则使用 varargout 代替 Y1,…,YM。在本例中,varargout 是由输出组成的元胞数组,其中 varargout{j} 对应于 Yj。
提示
如果自定义层具有一个作为可学习参数的 dlnetwork 对象,则在自定义层的 forward 函数中,应对 dlnetwork 对象使用 forward 函数。在执行此操作时,dlnetwork 对象 forward 函数使用适当的层运算进行训练。
输入的维度取决于数据的类型和所连接层的输出。
| 层输入 | 示例 | |
|---|---|---|
| 形状 | 数据格式 | |
| 二维图像 | h×w×c×N 数值数组,其中 h、w、c 和 N 分别是图像的高度、宽度、通道数和观测值数量。 | "SSCB" |
| 三维图像 | h×w×d×c×N 数值数组,其中 h、w、d、c 和 N 分别是图像的高度、宽度、深度、通道数和图像观测值数量。 | "SSSCB" |
| 向量序列 | c×N×s 矩阵,其中 c 是序列的特征数,N 是序列观测值数量,而 s 是序列长度。 | "CBT" |
| 二维图像序列 | h×w×c×N×s 数组,其中 h、w 和 c 分别对应于图像的高度、宽度和通道数,N 是图像序列观测值数量,而 s 是序列长度。 | "SSCBT" |
| 三维图像序列 | h×w×d×c×N×s 数组,其中 h、w、d 和 c 分别对应于图像的高度、宽度、深度和通道数量,N 是图像序列观测值数量,而 s 是序列长度。 | "SSSCBT" |
| 特征 | c×N 数组,其中 c 是特征数量,N 是观测值数量。 | "CB" |
对于输出序列的层,层可以输出任意长度的序列或输出无时间维度的数据。
自定义层前向函数的输出可以是复数值。 (自 R2024a 起)如果该层输出复数值数据,则在神经网络中使用自定义层时,必须确保后续层或损失函数支持复数值输入。在自定义层的 predict 或 forward 函数中使用复数会导致复数型可学习参数。要训练具有复数值可学习参数的模型,请使用带有 "sgdm"、"adam" 或 "rmsprop" 求解器(这些求解器使用 trainingOptions 函数来指定)的 trainnet 函数,或使用包含 sgdmupdate、adamupdate 或 rmspropupdate 函数的自定义训练循环。
在 R2024a 之前的版本中: 自定义层前向函数的输出不能为复数。如果自定义层的 predict 或 forward 函数包含复数,请在返回输出之前将所有输出转换为实数值。在自定义层的 predict 或 forward 函数中使用复数会导致复数型可学习参数。如果您使用的是自动微分(换句话说,您没有为自定义层编写后向函数),则在函数计算开始时,请将所有可学习参数转换为实数值。这样做可以确保自动微分算法不会输出复数值梯度。
重置状态函数
默认情况下,dlnetwork 对象的 resetState 函数对具有状态参数的自定义层不起作用。要为网络对象定义 resetState 函数的层行为,请在重置状态参数的层定义中定义可选层 resetState 函数。
resetState 函数必须具有语法 layer = resetState(layer),其中返回的层具有重置状态属性。
resetState 函数不能设置除可学习属性和状态属性之外的任何层属性。如果该函数设置了其他层属性,则可能会出现意外的层行为。 (自 R2023a 起)
后向函数
层后向函数计算损失关于输入数据的导数,然后将结果输出(反向传播)到前一层。如果层具有可学习参数(例如,层权重),则 backward 还计算损失关于可学习参数的导数。当您使用 trainnet 函数时,层会在后向传导过程中使用这些导数自动更新可学习参数。
定义后向函数是可选的。如果未指定后向函数,并且层前向函数支持 dlarray 对象,则软件会使用自动微分自动确定后向函数。有关支持 dlarray 对象的函数列表,请参阅List of Functions with dlarray Support。当您需要执行以下操作时,请定义一个自定义后向函数:
使用特定算法来计算导数。
在前向函数中使用不支持
dlarray对象的操作。
具有可学习 dlnetwork 对象的自定义层不支持自定义后向函数。
要定义一个自定义后向函数,请创建名为 backward 的函数。
backward 函数语法取决于层的类型。
dLdX = backward(layer,X,Y,dLdY,memory)返回损失关于层输入的导数dLdX,其中layer只有一个输入和一个输出。Y对应于前向函数输出,而dLdY对应于损失关于Y的导数。函数输入memory对应于前向函数的内存输出。[dLdX,dLdW] = backward(layer,X,Y,dLdY,memory)还返回损失关于可学习参数的导数dLdW,其中layer只有一个可学习参数。[dLdX,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory)还返回损失关于状态输入的导数dLdSin,其中layer只有一个状态参数,而dLdSout对应于损失关于层状态输出的导数。[dLdX,dLdW,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory)还返回损失关于可学习参数的导数dLdW,并返回损失关于层状态输入的导数dLdSin,其中layer只有一个状态参数和一个可学习参数。
您可以针对具有多个输入、多个输出、多个可学习参数或多个状态参数的层调整语法:
对于具有多个输入的层,分别用
X1,...,XN和dLdX1,...,dLdXN替换X和dLdX,其中N是输入的数量。对于具有多个输出的层,分别用
Y1,...,YM和dLdY1,...,dLdYM替换Y和dLdY,其中M是输出的数量。对于具有多个可学习参数的层,将
dLdW替换为dLdW1,...,dLdWP,其中P是可学习参数的数量。对于具有多个状态参数的层,分别用
dLdSin1,...,dLdSinK和dLdSout1,...,dLdSoutK替换dLdSin和dLdSout,其中K是状态参数的数量。
要通过防止在前向和后向传导之间保存未使用的变量来减少内存使用量,请用 ~ 替换对应的输入参量。
提示
如果 backward 的输入数量可能变化,则使用 varargin 代替 layer 后的输入参量。在这种情况下,varargin 是由输入组成的元胞数组,其中前 N 个元素对应于 N 个层输入,接下来的 M 个元素对应于 M 个层输出,接下来的 M 个元素对应于损失关于 M 个层输出的导数,接下来的 K 个元素对应于损失关于 K 个状态输出的 K 个导数,最后一个元素对应于 memory。
如果输出的数量可能变化,则使用 varargout 代替输出参量。在这种情况下,varargout 是由输出组成的元胞数组,其中前 N 个元素对应于损失关于 N 个层输入的 N 个导数,接下来的 P 个元素对应于损失关于 P 个可学习参数的导数,接下来的 K 个元素对应于损失关于 K 个状态输入的导数。
X 和 Y 的值与前向函数中的对应值相同。dLdY 的维度与 Y 的维度相同。
dLdX 的维度和数据类型与 X 的维度和数据类型相同。dLdW 的维度和数据类型与 W 的维度和数据类型相同。
要计算损失关于输入数据的导数,可以使用链式法则计算损失关于输出数据的导数以及输出数据关于输入数据的导数:
当使用 trainnet 函数时,层会在后向传导过程中使用导数 dLdW 自动更新可学习参数。
有关如何定义自定义后向函数的示例,请参阅Specify Custom Layer Backward Function。
自定义层后向函数的输出可以是复数值。 (自 R2024a 起)使用复数值梯度可能会导致可学习参数为复数值。要训练具有复数值可学习参数的模型,请使用带有 "sgdm"、"adam" 或 "rmsprop" 求解器(这些求解器使用 trainingOptions 函数来指定)的 trainnet 函数,或使用包含 sgdmupdate、adamupdate 或 rmspropupdate 函数的自定义训练循环。
在 R2024a 之前的版本中: 自定义层后向函数的输出不能为复数。如果您的后向函数涉及复数,则请在返回输出之前将后向函数的所有输出转换为实数值。
GPU 兼容性
如果层前向函数完全支持 dlarray 对象,则该层与 GPU 兼容。否则,为了与 GPU 兼容,层函数必须支持 gpuArray (Parallel Computing Toolbox) 类型的输入并返回其输出。
许多 MATLAB® 内置函数支持 gpuArray (Parallel Computing Toolbox) 和 dlarray 输入参量。有关支持 dlarray 对象的函数列表,请参阅List of Functions with dlarray Support。有关在 GPU 上执行的函数的列表,请参阅在 GPU 上运行 MATLAB 函数 (Parallel Computing Toolbox)。要使用 GPU 进行深度学习,您还必须拥有支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。有关在 MATLAB 中使用 GPU 的详细信息,请参阅MATLAB 中的 GPU 计算 (Parallel Computing Toolbox)。
代码生成兼容性
您必须在层定义中指定 pragma %#codegen,以创建用于代码生成的自定义层。代码生成不支持具有状态属性(具有特性 State 的属性)的自定义层。
此外,在生成使用第三方库的代码时:
代码生成仅支持包含二维图像或特征输入的自定义层。
层前向函数的输入和输出必须具有相同的批量大小。
非标量属性的类型必须为单精度、双精度或字符数组。
标量属性的类型必须为数值、逻辑值或字符串。
有关如何创建支持代码生成的自定义层的示例,请参阅Define Custom Deep Learning Layer for Code Generation。
网络合成
要创建本身定义神经网络的自定义层,您可以在层定义的 properties (Learnable) 部分中将 dlnetwork 对象声明为可学习参数。这种方法称为网络合成。您可以使用网络合成来实现以下目的:
创建一个具有控制流的网络,例如,网络的一部分可以根据输入数据而动态变化。
创建一个具有循环的网络,例如,网络的某些部分将输出反馈到自身。
实现权重共享,例如,在不同数据需要通过相同层的网络(如孪生神经网络或生成对抗网络 (GAN))中执行此操作。
对于同时具有可学习参数和状态参数的嵌套网络(例如,具有批量归一化或 LSTM 层的网络),请在层定义的 properties (Learnable, State) 部分中声明网络。
检查层的有效性
如果您创建自定义深度学习层,则可以使用 checkLayer 函数来检查该层是否有效。该函数检查层的有效性、GPU 兼容性、正确定义的梯度和代码生成兼容性。要检查层是否有效,请运行以下命令:
checkLayer(layer,layout)
layer 是层的实例,而 layout 是 networkDataLayout 对象,该对象指定层输入的有效大小和数据格式。要检查多个观测值,请使用 ObservationDimension 选项。要运行代码生成兼容性检查,请将 CheckCodegenCompatibility 选项设置为 1 (true)。对于较大的输入大小,梯度检查的运行时间较长。为了加快检查速度,请指定较小的有效输入大小。有关详细信息,请参阅Check Custom Layer Validity。
使用 checkLayer 检查自定义层的有效性
检查自定义层 sreluLayer 的层有效性。
自定义层 sreluLayer 作为支持文件附加到此示例中,该层会将 SReLU 运算应用于输入数据。要访问此层,请以实时脚本形式打开此示例。
创建层的一个实例。
layer = sreluLayer;
创建一个 networkDataLayout 对象,该对象指定层的典型输入的预期输入大小和格式。指定有效的输入大小 [24 24 20 128],其中维度对应于前一层输出的高度、宽度、通道数和观测值数量。将格式指定为 "SSCB"(空间、空间、通道、批量)。
validInputSize = [24 24 20 128];
layout = networkDataLayout(validInputSize,"SSCB");使用 checkLayer 检查层的有效性。
checkLayer(layer,layout)
Skipping GPU tests. No compatible GPU device found. Skipping code generation compatibility tests. To check validity of the layer for code generation, specify the CheckCodegenCompatibility and ObservationDimension options. Running nnet.checklayer.TestLayerWithoutBackward .......... .......... Done nnet.checklayer.TestLayerWithoutBackward __________ Test Summary: 20 Passed, 0 Failed, 0 Incomplete, 14 Skipped. Time elapsed: 0.35114 seconds.
该函数对层进行检查时未发现任何问题。
另请参阅
trainnet | trainingOptions | dlnetwork | functionLayer | checkLayer | setLearnRateFactor | setL2Factor | getLearnRateFactor | getL2Factor | findPlaceholderLayers | replaceLayer | PlaceholderLayer | networkDataLayout
主题
- Define Custom Deep Learning Layer with Learnable Parameters
- Define Custom Deep Learning Layer with Multiple Inputs
- Define Custom Deep Learning Layer with Formatted Inputs
- Define Custom Recurrent Deep Learning Layer
- Specify Custom Layer Backward Function
- Define Custom Deep Learning Layer for Code Generation
- Deep Learning Network Composition
- Define Nested Deep Learning Layer Using Network Composition
- Check Custom Layer Validity