使用一维卷积进行“序列到序列”分类
此示例说明如何使用通用时序卷积网络 (TCN) 对序列数据的每个时间步进行分类。
虽然“序列到序列”任务通常采用循环神经网络架构解决,但 Bai 等人 [1] 的研究表明,卷积神经网络在典型序列建模任务上能够达到与循环网络相当的性能,甚至表现更优。使用卷积网络的潜在优势包括:更出色的并行机制、对感受野大小的更精确控制、对训练期间网络内存占用的更精确控制以及更稳定的梯度。与循环网络类似,卷积网络可以处理可变长度的输入序列,并可用于对“序列到序列”或“序列到单个”任务进行建模。
在此示例中,您将训练一个 TCN 来识别在身体上佩戴智能手机的人的活动。您将使用表示三个方向上的加速度计读数的时间序列数据来训练网络。
加载训练数据
加载人体活动识别数据。该数据包含从佩戴在身体上的智能手机获得的七个时间序列的传感器数据。每个序列有三个特征,且长度不同。这三个特征对应于三个方向上的加速度计读数。
s = load("HumanActivityTrain.mat");
XTrain = s.XTrain;
TTrain = s.YTrain;查看训练数据中观测值的数量。
numObservations = numel(XTrain)
numObservations = 6
查看训练数据中类的数量。
classes = categories(TTrain{1});
numClasses = numel(classes)numClasses = 5
查看训练数据中特征的数量。
numFeatures = size(s.XTrain{1},1)numFeatures = 3
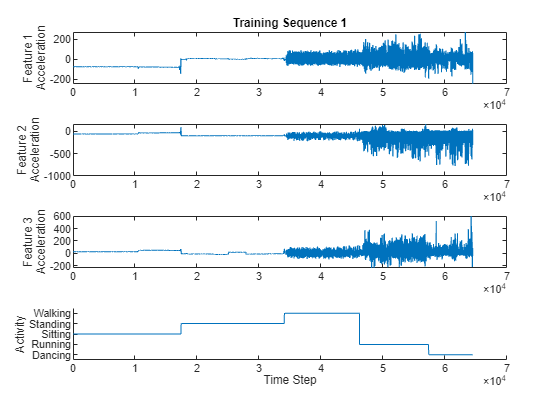
在图中可视化其中一个训练序列。绘制第一个训练序列的特征和对应的活动。
figure for i = 1:3 X = s.XTrain{1}(i,:); subplot(4,1,i) plot(X) ylabel("Feature " + i + newline + "Acceleration") end subplot(4,1,4) hold on plot(s.YTrain{1}) hold off xlabel("Time Step") ylabel("Activity") subplot(4,1,1) title("Training Sequence 1")
定义深度学习模型
TCN 的主要构建模块是扩张因果卷积层,该层在每个序列的时间步进行运算。在此上下文中,“因果”意味着为特定时间步计算的激活值不能依赖于未来时间步的激活值。
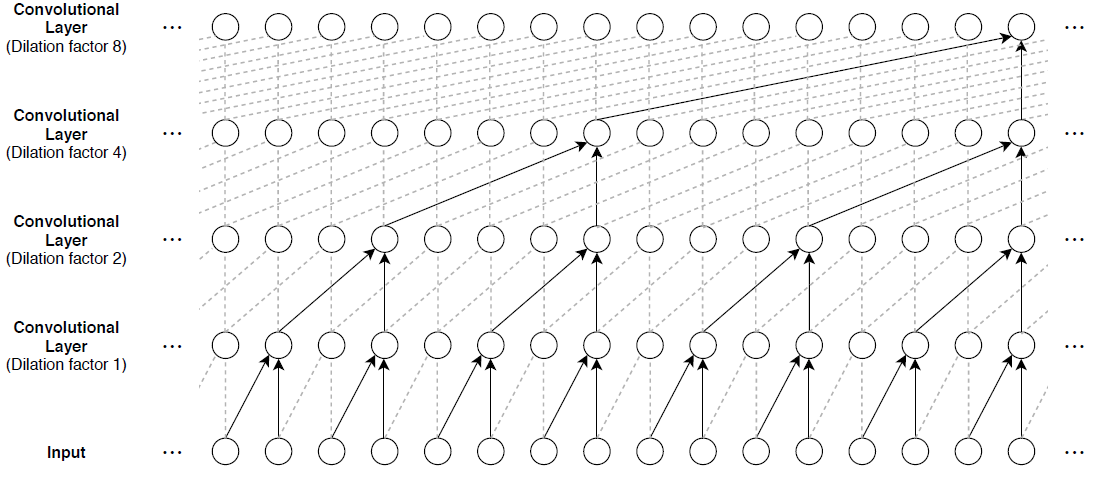
为了从先前的时间步构建上下文,通常将多个卷积层堆叠在一起。为获得较大的感受野,后续卷积层的扩张因子呈指数级增长,如下图所示。假设第 k 个卷积层的扩张因子为 ,步幅为 1,则此类网络的感受野大小可计算为 ,其中 为滤波器大小, 为卷积层数量。根据具体的数据和任务需求,可通过更改滤波器大小和层数来轻松调整感受野大小和可学习参数的数量。
与循环网络相比,TCN 的缺点之一是在推断期间内存占用更大。计算下一个时间步需要完整的原始序列。为了减少推断时间和内存消耗,特别是对于向前一步预测,应使用最小的合理感受野大小 进行训练,并且仅使用输入序列的最后 个时间步执行预测。
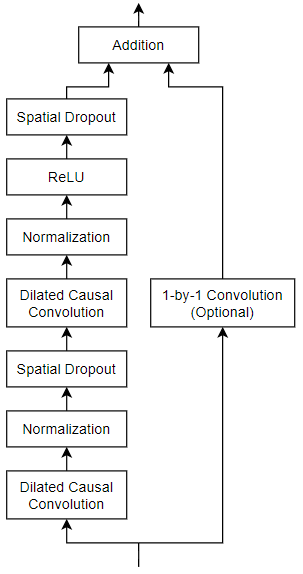
通用 TCN 架构(如 [1] 中所述)由多个残差块组成,每个残差块包含两组具有相同扩张因子的扩张因果卷积层,随后依次连接归一化层、ReLU 激活层和空间丢弃层。网络将每个块的输入与输出相加(当输入与输出的通道数不匹配时,对输入进行 1×1 卷积),并应用最终的激活函数。
定义一个包含四个此类串联残差块的网络,每个残差块的扩张因子为前一层的两倍,起始扩张因子为 1。对于残差块,为一维卷积层指定 64 个大小为 5 的滤波器,并为空间丢弃层指定丢弃因子为 0.005。
您也可以使用深度网络设计器构建该网络。在深度网络设计器起始页,在序列到序列分类网络(未训练) 部分中点击 TCN。
numFilters = 64; filterSize = 5; dropoutFactor = 0.005; numBlocks = 4; net = dlnetwork; layer = sequenceInputLayer(numFeatures,Normalization="rescale-symmetric",Name="input"); net = addLayers(net,layer); outputName = layer.Name; for i = 1:numBlocks dilationFactor = 2^(i-1); layers = [ convolution1dLayer(filterSize,numFilters,DilationFactor=dilationFactor,Padding="causal",Name="conv1_"+i) layerNormalizationLayer spatialDropoutLayer(Probability=dropoutFactor) convolution1dLayer(filterSize,numFilters,DilationFactor=dilationFactor,Padding="causal") layerNormalizationLayer reluLayer spatialDropoutLayer(Probability=dropoutFactor) additionLayer(2,Name="add_"+i)]; % Add and connect layers. net = addLayers(net,layers); net = connectLayers(net,outputName,"conv1_"+i); % Skip connection. if i == 1 % Include convolution in first skip connection. layer = convolution1dLayer(1,numFilters,Name="convSkip"); net = addLayers(net,layer); net = connectLayers(net,outputName,"convSkip"); net = connectLayers(net,"convSkip","add_" + i + "/in2"); else net = connectLayers(net,outputName,"add_" + i + "/in2"); end % Update layer output name. outputName = "add_" + i; end layers = [ fullyConnectedLayer(numClasses,Name="fc") softmaxLayer]; net = addLayers(net,layers); net = connectLayers(net,outputName,"fc");
在图中查看网络。
figure
plot(net)
title("Temporal Convolutional Network")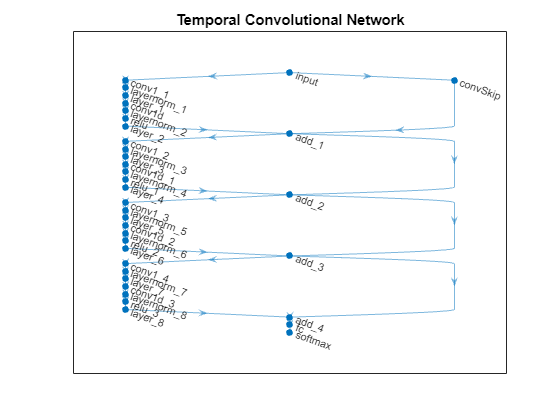
指定训练选项
指定用于训练的选项集。在选项中进行选择需要经验分析。要通过运行试验探索不同训练选项配置,您可以使用Experiment Manager。
使用 Adam 优化器进行训练。
使用 1 的小批量大小进行 60 轮训练。
由于训练数据具有行和列分别对应于通道和时间步的序列,请指定输入数据格式
"CTB"(通道、时间、批量)。在图中显示训练进度并监控准确度。
禁用详尽输出。
options = trainingOptions("adam", ... MaxEpochs=60, ... miniBatchSize=1, ... InputDataFormats="CTB", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=0);
训练模型
使用 trainnet 函数训练神经网络。默认情况下,trainnet 函数使用 GPU(如果有)。在 GPU 上进行训练需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet 函数使用 CPU。要指定执行环境,请使用 ExecutionEnvironment 训练选项。
net = trainnet(XTrain,TTrain,net,"crossentropy",options);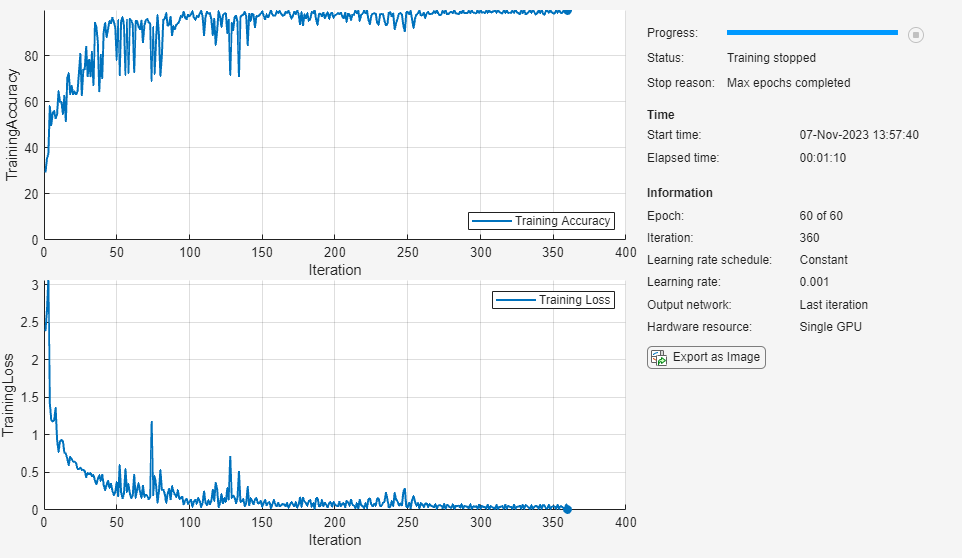
测试模型
通过将对保留测试集的预测值与每个时间步的真实标签进行比较,来测试模型的分类准确度。
加载测试数据。
s = load("HumanActivityTest.mat");
XTest = s.XTest;
TTest = s.YTest;对测试图像进行分类。要使用多个观测值进行预测,请使用 minibatchpredict 函数。要将预测分数转换为标签,请使用 scores2label 函数。minibatchpredict 函数自动使用 GPU(如果有)。否则,该函数使用 CPU。
scores = minibatchpredict(net,XTest,InputDataFormats="CTB");
YPred = scores2label(scores,classes);在图中将预测值与对应的测试数据进行比较。
figure plot(YPred,".-") hold on plot(TTest{1}) hold off xlabel("Time Step") ylabel("Activity") legend(["Predicted" "Test Data"],Location="northeast") title("Test Sequence Predictions")
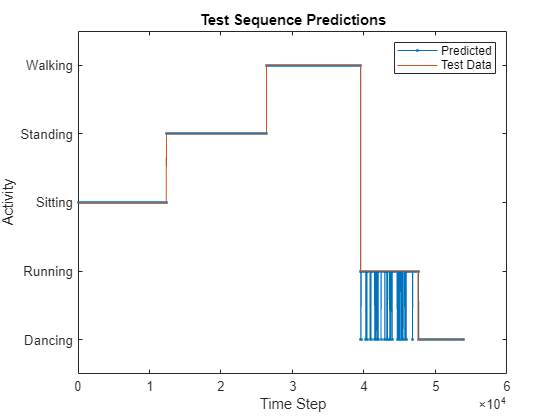
在混淆矩阵中可视化预测。
figure
confusionchart(TTest{1},YPred)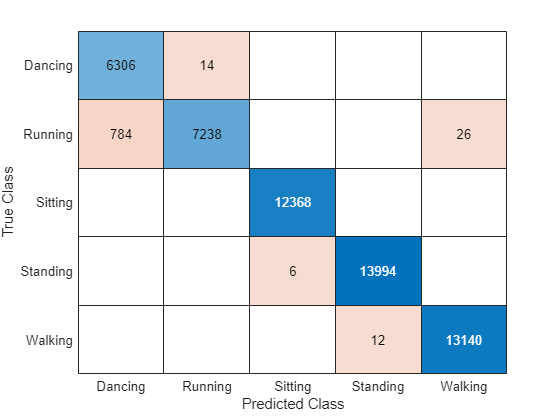
通过将预测值与测试标签进行比较来评估分类准确度。
accuracy = mean(YPred == TTest{1})accuracy = 0.9905
参考资料
[1] Bai, Shaojie, J. Zico Kolter, and Vladlen Koltun.“An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling.”Preprint, submitted April 19, 2018. https://arxiv.org/abs/1803.01271.
[2] Oord, Aaron van den, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu.“WaveNet:A Generative Model for Raw Audio.”Preprint, submitted September 12, 2016. https://arxiv.org/abs/1609.03499.
[3] Tompson, Jonathan, Ross Goroshin, Arjun Jain, Yann LeCun, and Christoph Bregler.“Efficient Object Localization Using Convolutional Networks.”2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 648–56. https://doi.org/10.1109/CVPR.2015.7298664.
另请参阅
convolution1dLayer | trainnet | trainingOptions | dlnetwork | sequenceInputLayer | maxPooling1dLayer | averagePooling1dLayer | globalMaxPooling1dLayer | globalAveragePooling1dLayer