simByMilstein
Description
[
simulates Paths,Times,Z] = simByMilstein(MDL,NPeriods)NTrials sample paths of Heston bivariate models
driven by two NBrowns Brownian motion sources of risk
approximating continuous-time stochastic processes by the Milstein
approximation.
simByMilstein provides a discrete-time approximation of the
underlying generalized continuous-time process. The simulation is derived directly
from the stochastic differential equation of motion; the discrete-time process
approaches the true continuous-time process only in the limit as
DeltaTime approaches zero.
[
specifies options using one or more name-value pair arguments in addition to the
input arguments in the previous syntax.Paths,Times,Z] = simByMilstein(___,Name=Value)
You can perform quasi-Monte Carlo simulations using the name-value arguments for
MonteCarloMethod, QuasiSequence, and
BrownianMotionMethod. For more information, see Quasi-Monte Carlo Simulation.
Examples
This example shows how to use simByMilstein with a Heston model to perform a quasi-Monte Carlo simulation. Quasi-Monte Carlo simulation is a Monte Carlo simulation that uses quasi-random sequences instead pseudo random numbers.
Define the parameters for the heston object.
Return = 0.03; Level = 0.05; Speed = 1.0; Volatility = 0.2; AssetPrice = 80; V0 = 0.04; Rho = -0.7; StartState = [AssetPrice;V0]; Correlation = [1 Rho;Rho 1];
Create a heston object.
Heston = heston(Return,Speed,Level,Volatility,startstate=StartState,correlation=Correlation)
Heston =
Class HESTON: Heston Bivariate Stochastic Volatility
----------------------------------------------------
Dimensions: State = 2, Brownian = 2
----------------------------------------------------
StartTime: 0
StartState: 2x1 double array
Correlation: 2x2 double array
Drift: drift rate function F(t,X(t))
Diffusion: diffusion rate function G(t,X(t))
Simulation: simulation method/function simByEuler
Return: 0.03
Speed: 1
Level: 0.05
Volatility: 0.2
Perform a quasi-Monte Carlo simulation by using simByMilstein with the optional name-value arguments for MonteCarloMethod, QuasiSequence, and BrownianMotionMethod.
[paths,time] = simByMilstein(Heston,10,ntrials=4096,MonteCarloMethod="quasi",QuasiSequence="sobol",BrownianMotionMethod="principal-components");
Input Arguments
Stochastic differential equation model, specified as a
heston object. You can create a
heston object using heston.
Data Types: object
Number of simulation periods, specified as a positive scalar integer. The
value of NPeriods determines the number of rows of the
simulated output series.
Data Types: double
Name-Value Arguments
Specify optional pairs of arguments as
Name1=Value1,...,NameN=ValueN, where Name is
the argument name and Value is the corresponding value.
Name-value arguments must appear after other arguments, but the order of the
pairs does not matter.
Example: [Paths,Times,Z] =
simByMilstein(Heston_obj,NPeriods,NTrials=10,DeltaTime=dt)
Simulated trials (sample paths) of NPeriods
observations each, specified as NTrials and a
positive scalar integer.
Data Types: double
Positive time increments between observations, specified as
DeltaTime and a scalar or an
NPeriods-by-1 column
vector.
DeltaTime represents the familiar
dt found in stochastic differential equations,
and determines the times at which the simulated paths of the output
state variables are reported.
Data Types: double
Number of intermediate time steps within each time increment
dt (specified as DeltaTime),
specified as NSteps and a positive scalar
integer.
The simByMilstein function partitions each time
increment dt into NSteps
subintervals of length dt/NSteps,
and refines the simulation by evaluating the simulated state vector at
NSteps − 1 intermediate points. Although
simByMilstein does not report the output state
vector at these intermediate points, the refinement improves accuracy by
allowing the simulation to more closely approximate the underlying
continuous-time process.
Data Types: double
Flag to use antithetic sampling to generate the Gaussian random
variates that drive the Brownian motion vector (Wiener processes),
specified as Antithetic and a scalar numeric or
logical 1 (true) or
0 (false).
When you specify true,
simByEuler performs sampling such that all
primary and antithetic paths are simulated and stored in successive
matching pairs:
Odd trials
(1,3,5,...)correspond to the primary Gaussian paths.Even trials
(2,4,6,...)are the matching antithetic paths of each pair derived by negating the Gaussian draws of the corresponding primary (odd) trial.
Note
If you specify an input noise process (see
Z), simByMilstein ignores
the value of Antithetic.
Data Types: logical
Direct specification of the dependent random noise process for
generating the Brownian motion vector (Wiener process) that drives the
simulation, specified as Z and a function or as an
(NPeriods ⨉
NSteps)-by-NBrowns-by-NTrials
three-dimensional array of dependent random variates.
Note
If you specify Z as a function, it must return
an NBrowns-by-1 column vector,
and you must call it with two inputs:
A real-valued scalar observation time t
An
NVars-by-1state vector Xt
Data Types: double | function
Flag that indicates how the output array Paths is
stored and returned, specified as StorePaths and a
scalar numeric or logical 1 (true)
or 0 (false).
If
StorePathsistrue(the default value) or is unspecified,simByMilsteinreturnsPathsas a three-dimensional time-series array.If
StorePathsisfalse(logical0),simByMilsteinreturnsPathsas an empty matrix.
Data Types: logical
Monte Carlo method to simulate stochastic processes, specified as
MonteCarloMethod and a string or character vector
with one of the following values:
"standard"— Monte Carlo using pseudo random numbers"quasi"— Quasi-Monte Carlo using low-discrepancy sequences"randomized-quasi"— Randomized quasi-Monte Carlo
Note
If you specify an input noise process (see
Z), simByMilstein ignores
the value of MonteCarloMethod.
Data Types: string | char
Low discrepancy sequence to drive the stochastic processes, specified
as QuasiSequence and a string or character vector
with the following value:
"sobol"— Quasi-random low-discrepancy sequences that use a base of two to form successively finer uniform partitions of the unit interval and then reorder the coordinates in each dimension.
Note
If MonteCarloMethod option is not specified
or specified as"standard",
QuasiSequence is ignored.
If you specify an input noise process (see
Z), simByMilstein ignores
the value of QuasiSequence.
Data Types: string | char
Brownian motion construction method, specified as
BrownianMotionMethod and a string or character
vector with one of the following values:
"standard"— The Brownian motion path is found by taking the cumulative sum of the Gaussian variates."brownian-bridge"— The last step of the Brownian motion path is calculated first, followed by any order between steps until all steps have been determined."principal-components"— The Brownian motion path is calculated by minimizing the approximation error.
Note
If an input noise process is specified using the
Z input argument,
BrownianMotionMethod is ignored.
The starting point for a Monte Carlo simulation is the construction of a Brownian motion sample path (or Wiener path). Such paths are built from a set of independent Gaussian variates, using either standard discretization, Brownian-bridge construction, or principal components construction.
Both standard discretization and Brownian-bridge construction share
the same variance and, therefore, the same resulting convergence when
used with the MonteCarloMethod using pseudo random
numbers. However, the performance differs between the two when the
MonteCarloMethod option
"quasi" is introduced, with faster convergence
for the "brownian-bridge" construction option and the
fastest convergence for the "principal-components"
construction option.
Data Types: string | char
Sequence of end-of-period processes or state vector adjustments,
specified as Processes and a function or cell array
of functions of the form
The simByMilstein function runs processing
functions at each interpolation time. The functions must accept the
current interpolation time t, and the current state
vector Xt
and return a state vector that can be an adjustment to the input
state.
If you specify more than one processing function,
simByMilstein invokes the functions in the order
in which they appear in the cell array. You can use this argument to
specify boundary conditions, prevent negative prices, accumulate
statistics, plot graphs, and more.
The end-of-period Processes argument allows you to
terminate a given trial early. At the end of each time step,
simByMilstein tests the state vector
Xt for an
all-NaN condition. Thus, to signal an early
termination of a given trial, all elements of the state vector
Xt must be
NaN. This test enables you to define a
Processes function to signal early termination of
a trial, and offers significant performance benefits in some situations
(for example, pricing down-and-out barrier options).
Data Types: cell | function
Output Arguments
Simulated paths of correlated state variables, returned as an
(NPeriods +
1)-by-NVars-by-NTrials
three-dimensional time series array.
For a given trial, each row of Paths is the transpose
of the state vector
Xt at time
t. When StorePaths is set to
false, simByMilstein returns
Paths as an empty matrix.
Observation times associated with the simulated paths, returned as an
(NPeriods + 1)-by-1 column vector.
Each element of Times is associated with the
corresponding row of Paths.
Dependent random variates for generating the Brownian motion vector
(Wiener processes) that drive the simulation, returned as an
(NPeriods ⨉
NSteps)-by-NBrowns-by-NTrials
three-dimensional time-series array.
More About
There are inheritance relationships among the SDE classes.
The following figure illustrates the inheritance relationships.
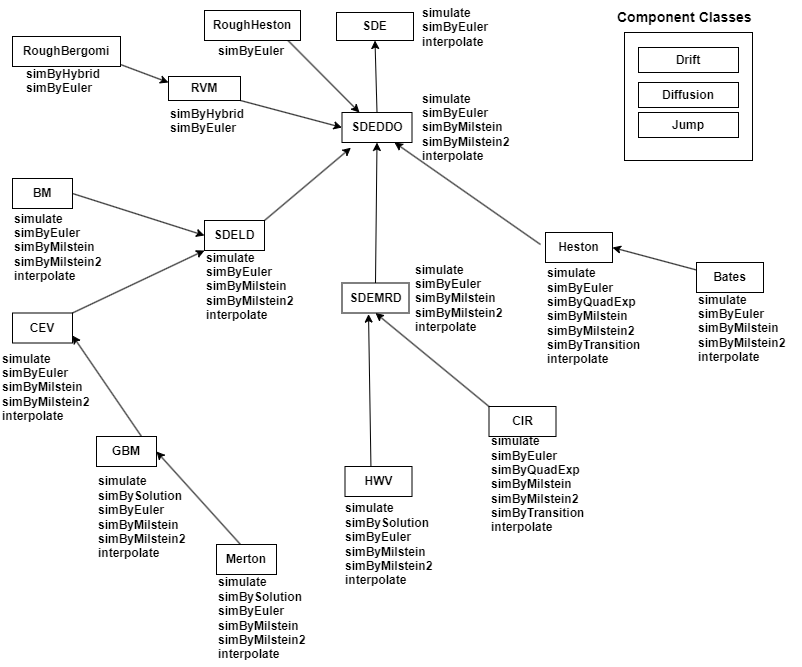
For more information, see SDE Class Hierarchy.
The Milstein method is a numerical method for approximating solutions to stochastic differential equations (SDEs).
The Milstein method is an extension of the Euler-Maruyama method, which is a first-order numerical method for SDEs. The Milstein method adds a correction term to the Euler-Maruyama method that takes into account the second-order derivative of the SDE. This correction term improves the accuracy of the approximation, especially for SDEs with non-linearities.
Simulation methods allow you to specify a popular variance reduction technique called antithetic sampling.
This technique attempts to replace one sequence of random observations with another that has the same expected value but a smaller variance. In a typical Monte Carlo simulation, each sample path is independent and represents an independent trial. However, antithetic sampling generates sample paths in pairs. The first path of the pair is referred to as the primary path, and the second as the antithetic path. Any given pair is independent other pairs, but the two paths within each pair are highly correlated. Antithetic sampling literature often recommends averaging the discounted payoffs of each pair, effectively halving the number of Monte Carlo trials.
This technique attempts to reduce variance by inducing negative dependence between paired input samples, ideally resulting in negative dependence between paired output samples. The greater the extent of negative dependence, the more effective antithetic sampling is.
Algorithms
Consider the process X satisfying a stochastic differential equation of the form.
The attempt of including a term of O(dt) in the drift refines the Euler scheme and results in the algorithm derived by Milstein [1].
References
[1] Milstein, G.N. "A Method of Second-Order Accuracy Integration of Stochastic Differential Equations."Theory of Probability and Its Applications, 23, 1978, pp. 396–401.
Version History
Introduced in R2023a
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
选择网站
选择网站以获取翻译的可用内容,以及查看当地活动和优惠。根据您的位置,我们建议您选择:。
您也可以从以下列表中选择网站:
如何获得最佳网站性能
选择中国网站(中文或英文)以获得最佳网站性能。其他 MathWorks 国家/地区网站并未针对您所在位置的访问进行优化。
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)