simByMilstein
Simulate diagonal diffusion Merton sample paths by Milstein
approximation
Since R2023a
Syntax
Description
[
simulates Paths,Times,Z,N] = simByMilstein(MDL,NPeriods)NTrials sample paths of NVars
correlated state variables driven by NBrowns Brownian motion
sources of risk and NJumps compound Poisson processes
representing the arrivals of important events over NPeriods
consecutive observation periods. The simulation approximates the continuous-time
Merton jump diffusion process by the Milstein approach.
[
specifies options using one or more name-value pair arguments in addition to the
input arguments in the previous syntax.Paths,Times,Z,N] = simByMilstein(___,Name=Value)
You can perform quasi-Monte Carlo simulations using the name-value arguments for
MonteCarloMethod, QuasiSequence, and
BrownianMotionMethod. For more information, see Quasi-Monte Carlo Simulation.
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
There are inheritance relationships among the SDE classes.
The following figure illustrates the inheritance relationships.
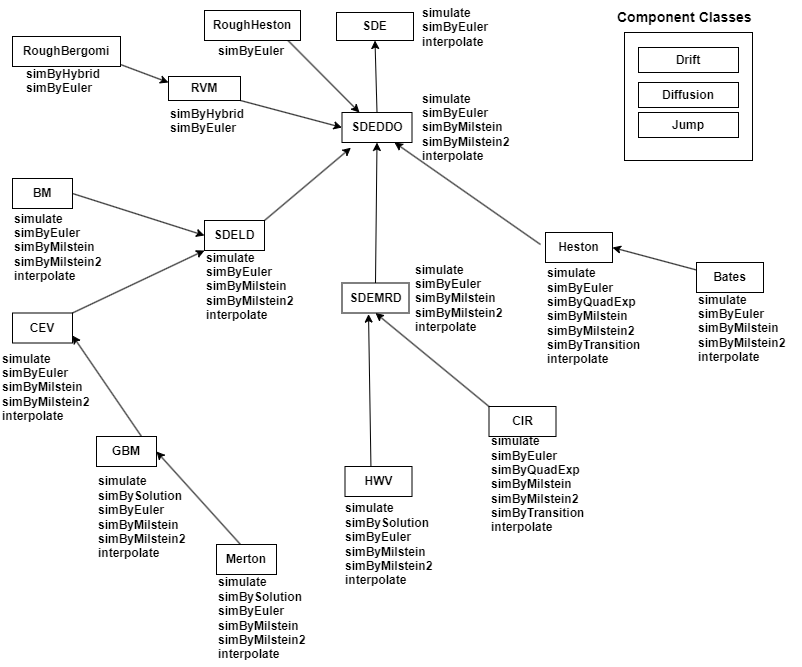
For more information, see SDE Class Hierarchy.
Algorithms
This function simulates any vector-valued SDE of the following form:
Here:
Xt is an
NVars-by-1state vector of process variables.B(t,Xt) is an
NVars-by-NVarsmatrix of generalized expected instantaneous rates of return.D(t,Xt)is anNVars-by-NVarsdiagonal matrix in which each element along the main diagonal is the corresponding element of the state vector.V(t,Xt)is anNVars-by-NVarsmatrix of instantaneous volatility rates.dWt is an
NBrowns-by-1Brownian motion vector.Y(t,Xt,Nt)is anNVars-by-NJumpsmatrix-valued jump size function.dNt is an
NJumps-by-1counting process vector.
simByEuler simulates NTrials sample paths of
NVars correlated state variables driven by
NBrowns Brownian motion sources of risk over
NPeriods consecutive observation periods, using the Euler
approach to approximate continuous-time stochastic processes.
Consider the process X satisfying a stochastic differential equation of the form.
The attempt of including a term of O(dt) in the drift refines the Euler scheme and results in the algorithm derived by Milstein [1].
References
[1] Milstein, G.N. "A Method of Second-Order Accuracy Integration of Stochastic Differential Equations."Theory of Probability and Its Applications, 23, 1978, pp. 396–401.
Version History
Introduced in R2023a