findgroups
查找组并返回组编号
语法
说明
要将数据分成若干组并将函数应用于这些组,请同时使用 findgroups 和 splitapply 函数。有关数据组计算的详细信息,请参阅对数据组的计算。
G = findgroups(A)G,它是从分组变量 A 生成的组编号的向量。输出参量 G 包含从 1 到 N 的整数值,指示 A 中 N 个唯一值的 N 个不同组。例如,如果 A 是 ["b" "a" "a" "b"],则 findgroups 返回 G 为 [2 1 1 2]。换句话说,G 中的组编号对应于 A 中排序的唯一值。
要使用 G 基于其他变量拆分数据组,请将其作为 splitapply 函数的输入参量传入。
findgroups 函数将 A 中的缺失字符串、空字符向量、NaN、NaT 以及未定义的分类值视为缺失值,并返回 NaN 作为 G 的对应元素。
示例
输入参数
输出参量
详细信息
在数据分析中,您通常对数据组执行计算。对于这种计算,您可以将一个或多个数据变量拆分成若干数据组,对每个数据组执行计算,并将结果组合成一个或多个输出变量。您可以使用一个或多个分组变量来指定组。分组变量中的唯一值定义数据变量的对应值所属的组。
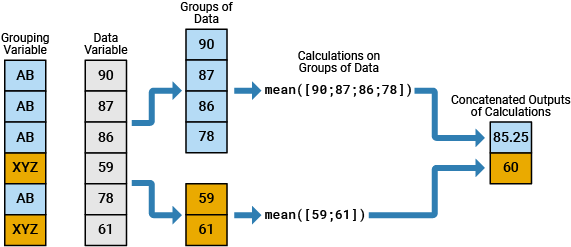
例如,该图显示简单的分组计算,该计算将 6×1 数值向量拆分为两组数据,计算每组数据的均值,然后将输出合并为一个 2×1 数值向量。6×1 分组变量有两个唯一值,即 AB 和 XYZ。
您可以指定包含数值、文本、日期和时间、类别或 bin 数据的分组变量。