splitapply
将数据划分归组并应用函数
语法
说明
要将数据分成若干组并将函数应用于这些组,请同时使用 findgroups 和 splitapply 函数。有关数据组计算的详细信息,请参阅对数据组的计算。
Y = splitapply(func,X,G)X 划分为由 G 指定的若干组,并将函数 func 应用于每个组。然后 splitapply 以数组形式返回 Y,其中包含对从 X 划分出的组应用 func 后的串联输出。输入参量 G 是由正整数组成的向量,用于指定 X 的对应元素属于哪个组。
输出 Y 和组编号 G 具有相同的排序。
如果 G 的任何元素是 NaN,则 splitapply 在将 X 拆分成若干组时会省略 X 中的对应值。
要创建 G,请先使用 findgroups 函数。然后使用 splitapply。
[Y1,...,YM] = splitapply(___) 将变量划分归组并向每个组应用 func。func 返回多个输出参量。Y1,...,YM 包含对从输入数据变量划分出的组应用 func 后的串联输出。func 可以返回属于不同类的输出参量,但在每次调用 func 时每个输出的类必须是相同的。您可将此语法与上述语法中的任何输入参量一起使用。
从 func 返回的输出参量的数量不必与 X1,...,XN 指定的输入参量的数量相同。
示例
输入参数
输出参量
详细信息
在数据分析中,您通常对数据组执行计算。对于这种计算,您可以将一个或多个数据变量拆分成若干数据组,对每个数据组执行计算,并将结果组合成一个或多个输出变量。您可以使用一个或多个分组变量来指定组。分组变量中的唯一值定义数据变量的对应值所属的组。
例如,该图显示简单的分组计算,该计算将 6×1 数值向量拆分为两组数据,计算每组数据的均值,然后将输出合并为一个 2×1 数值向量。6×1 分组变量有两个唯一值,即 AB 和 XYZ。
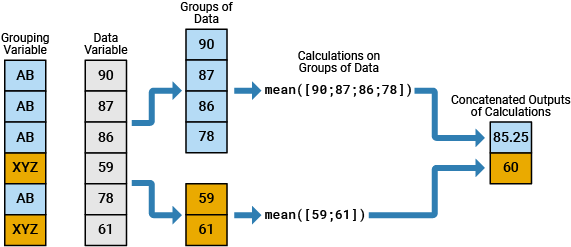
您可以指定包含数值、文本、日期和时间、类别或 bin 数据的分组变量。
扩展功能
版本历史记录
在 R2015b 中推出