movstd
移动标准差
语法
说明
M = movstd(___, 指定包含还是省略 nanflag)A 中的 NaN 值。例如,movstd(A,k,"omitnan") 在计算每个标准差时忽略 NaN 值。默认情况下,movstd 包括 NaN 值。
M = movstd(___, 使用一个或多个名称-值对组参量指定移动标准差的其他参数。例如,如果 Name,Value)x 是时间向量,则 movstd(A,k,"SamplePoints",x) 相对于 x 中的时间计算移动标准差。
示例
输入参数
输入数据,指定为向量、矩阵、多维数组、表或时间表。
数据类型: single | double | logical | table | timetable
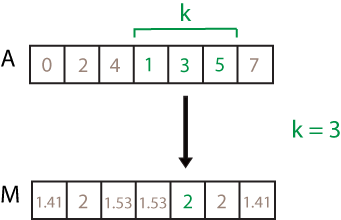
窗长度,指定为数值或持续时间标量。当 k 是正整数标量时,中心标准差包括当前位置的元素以及周围的相邻元素。
例如,movstd(A,3) 计算一个由局部三点标准差值组成的数组。
定向窗长度,指定为包含两个元素的数值或持续时间行向量。当 kb 和 kf 为正整数标量时,将基于 kb+kf+1 个元素进行计算。该计算包括当前位置的元素、当前位置前面的 kb 个元素以及当前位置后面的 kf 个元素。
例如,movstd(A,[2 1]) 计算一个由局部四点标准差值组成的数组。
![movstd(A,[2 1]) computation. The elements in the sample window are 4, 1, 3, and 5, so the resulting local standard deviation is 1.71.](movstd_windowing.png)
权重,指定为下列值之一:
0- 按k-1进行归一化,其中k是窗长度。如果k=1,则权重为k。1- 按k实现归一化。
数据类型: single | double
沿其运算的维度,指定为正整数标量。如果不指定维度,则默认值是大小不等于 1 的第一个数组维度。
维度 dim 表示 movstd 运算所沿的维度,即指定窗的移动方向。
以一个 m×n 输入矩阵 A 为例:
movstd(A,k,0,1)为A的每列计算包含k个元素的移动标准差,并返回一个m×n矩阵。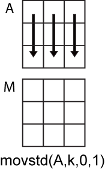
movstd(A,k,0,2)为A的每行计算包含k个元素的移动标准差,并返回一个m×n矩阵。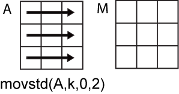
如果 A 是表或时间表,则无法指定 dim。movstd 函数始终沿表和时间表的变量进行运算。 (自 R2025a 起)
缺失值条件,指定为下列值之一:
"includemissing"或"includenan"- 在计算每个标准差时包括A中的NaN值。如果窗中的任一元素是NaN,则M中的对应元素是NaN。"includemissing"和"includenan"具有相同的行为。"omitmissing"或"omitnan"- 忽略A中的NaN值,并基于较少的点计算每个标准差。如果窗中的所有元素都是NaN,则M中的对应元素是NaN。"omitmissing"和"omitnan"具有相同的行为。