uniquetol
容差内的唯一值
语法
说明
C = uniquetol(A,___,occurrence)occurrence。
[___] = uniquetol(___, 使用一个或多个名称-值参量指定用于确定唯一元素的其他参数。例如,Name=Value)uniquetol(A,ByRows=true) 确定 A 中的唯一行。
示例
创建向量 x。通过变换和取消变换 x 来获取第二个向量 y。此变换会向 y 中引入舍入误差。
x = (1:6)'*pi; y = 10.^log10(x);
通过取差值来验证 x 和 y 不同。
x-y
ans = 6×1
10-14 ×
0.0444
0
0
0
0
-0.3553
串联向量 x 和 y。然后,使用 unique 查找唯一元素。unique 函数执行精确比较,并确定 x 中有些值与 y 中的值不完全相等。这些值与那些在 x-y 中具有非零差分的元素是同一批元素。因此,C 中包含一些貌似重复的值(实际上有细微差异)。
A = [x; y]; C = unique(A)
C = 8×1
3.1416
3.1416
6.2832
9.4248
12.5664
15.7080
18.8496
18.8496
使用 uniquetol 应用一个较小的容差执行比较。uniquetol 会将处于容差范围内的元素视为相等。
Ctol = uniquetol(A)
Ctol = 6×1
3.1416
6.2832
9.4248
12.5664
15.7080
18.8496
默认情况下,uniquetol 查找处于容差范围内的唯一元素,但它也可以查找矩阵中处于容差范围内的唯一行。
创建一个数值矩阵 x。通过变换和取消变换 y 来获取第二个矩阵 x。此变换会向 y 引入舍入差异。
x = [0.05 0.11 0.18; 0.18 0.21 0.29; 0.34 0.36 0.41; 0.46 0.52 0.76]; y = log10(10.^x);
串联矩阵 x 和 y。然后,使用 unique 查找唯一行。unique 函数执行精确比较,并确定串联矩阵 [x; y] 中的所有行都是唯一的,即使一些行仅有非常小的差别。
A = [x; y];
C = unique(A,"rows")C = 8×3
0.0500 0.1100 0.1800
0.0500 0.1100 0.1800
0.1800 0.2100 0.2900
0.1800 0.2100 0.2900
0.3400 0.3600 0.4100
0.3400 0.3600 0.4100
0.4600 0.5200 0.7600
0.4600 0.5200 0.7600
使用 uniquetol 找出唯一行。uniquetol 将处于容差范围内的行视为相等。
Ctol = uniquetol(A,ByRows=true)
Ctol = 4×3
0.0500 0.1100 0.1800
0.1800 0.2100 0.2900
0.3400 0.3600 0.4100
0.4600 0.5200 0.7600
创建向量 x。通过变换和取消变换 x 来获取第二个向量 y。此变换会向 y 中的一些元素引入舍入误差。
x = (1:5)'*pi; y = 10.^log10(x);
串联向量 x 和 y。然后,使用 uniquetol 重新构造 A,并将处于容差范围内的值视为相等。
A = [x; y]; [C,IA,IC] = uniquetol(A); newA = C(IC)
newA = 10×1
3.1416
6.2832
9.4248
12.5664
15.7080
3.1416
6.2832
9.4248
12.5664
15.7080
您可以在后续代码中将 newA 与 == 或验证全等的函数结合使用,如 isequal 或 unique。
D1 = unique(A)
D1 = 6×1
3.1416
3.1416
6.2832
9.4248
12.5664
15.7080
D2 = unique(newA)
D2 = 5×1
3.1416
6.2832
9.4248
12.5664
15.7080
通过指定 occurrence 选项来控制 uniquetol 选择哪些元素作为唯一元素。
创建一个向量,并找出在 1e-1 的容差范围内哪些元素是唯一元素。
A = [1 1.1 1.11 1.12 1.13 2]; C = uniquetol(A,1e-1)
C = 1×2
1 2
由于 A 中的前五个元素都具有关于 1e-1 的容差的相似值,因此只有其中的最小值被选取为唯一元素。这是因为 uniquetol 从 a 中的最小值开始,直到到达向量末尾的 2 才找到不在容差范围内的新元素。
使用 "highest" 选项指定 uniquetol 应从 A 中的最高值开始。1.13 元素被选作唯一元素,因为 uniquetol 从最高值向下查找。
C2 = uniquetol(A,1e-1,"highest")C2 = 1×2
1.1300 2.0000
创建一个由二维样本点组成的云,这些样本点限定在一个以点 为圆心,以 0.5 为半径的圆内。
x = rand(10000,2); insideCircle = sqrt((x(:,1)-.5).^2+(x(:,2)-.5).^2)<0.5; A = x(insideCircle,:);
求解一个缩小的点集,以便原始数据集中的每个点都处于该点集中点的容差范围之内。
tol = 0.05; C = uniquetol(A,tol,ByRows=true);
绘制原始数据集和缩小后的点集。缩小后的集合中的所有点都是原始数据集的成员,并且彼此之间的距离至少为 tol。
plot(A(:,1),A(:,2),"c.") hold on axis equal plot(C(:,1),C(:,2),"r.",MarkerSize=10) legend("Original Data","Reduced Data")

创建一个随机数向量,并使用容差确定唯一元素。将 OutputAllIndices 指定为 true,以返回处于唯一值的容差范围内的元素的所有索引。
rng default
A = rand(100,1);
[C,IA] = uniquetol(A,1e-2,OutputAllIndices=true);计算处于值 C(2) 的容差范围内的元素的平均值。
C(2)
ans = 0.0318
allA = A(IA{2})allA = 3×1
0.0357
0.0318
0.0344
aveA = mean(allA)
aveA = 0.0340
默认情况下,uniquetol 使用 abs(u-v) <= tol*DS 形式的容差测试,其中 DS 会根据输入数据的量级自动缩放。您可以另外指定 DS 值以用于 DataScale 名称-值参量。但是,绝对容差(其中 DS 为标量)不会根据输入数据的量级缩放。
首先,比较相距 eps 的两个较小值。指定 tol 和 DS 以生成满足容差范围的等式:abs(u-v) <= 10^-6。
x = 0.1; uniquetol([x exp(log(x))],10^-6,DataScale=1)
ans = 0.1000
接下来,增大这些值的量级。exp(log(x)) 计算中的舍入误差与这些值的量级成正比,具体来说,是 eps(x)。即使两个较大值彼此相距 eps,eps(x) 现在也更大。因此,10^-6 不再是适合的容差。
x = 10^10; uniquetol([x exp(log(x))],10^-6,DataScale=1)
ans = 1×2
1010 ×
1.0000 1.0000
使用 DS 的默认(缩放)值可更正此问题。
format long
Y = [0.1 10^10];
uniquetol([Y exp(log(Y))])ans = 1×2
1010 ×
0.000000000010000 1.000000000000000
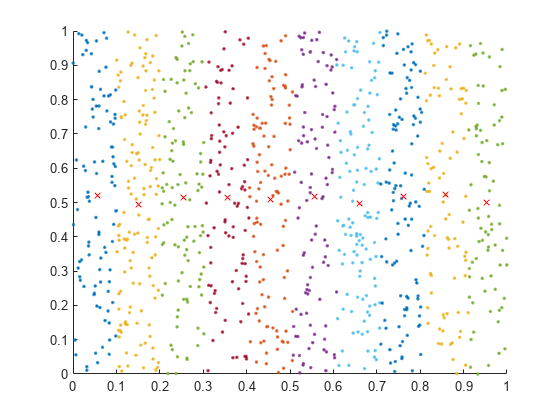
创建一个随机二维点集,然后使用 uniquetol 将这些点分组到具有相似 x 坐标(容差范围之内)的垂直波段中。将以下选项与 uniquetol 配合使用:
将
ByRows指定为true,因为点坐标在A的行中。将
OutputAllIndices指定为true,以返回那些 x 坐标在彼此容差范围内的所有点的索引。将
DataScale指定为[1 Inf],以将绝对容差用于x坐标,同时忽略y坐标。
A = rand(1000,2); DS = [1 Inf]; [C,IA] = uniquetol(A,0.1,ByRows=true,OutputAllIndices=true,DataScale=DS);
绘制每个波段的点和平均值。
hold on for k = 1:length(IA) plot(A(IA{k},1),A(IA{k},2),".") meanAi = mean(A(IA{k},:)); plot(meanAi(1),meanAi(2),"xr") end
输入参数
名称-值参数
输出参量
算法
uniquetol 以字典的编纂方式对输入进行排序,然后从最低值或最高值开始寻找容差范围内的唯一值。因此,更改输入的排序会更改输出。例如,uniquetol(-A) 给出的结果可能与 -uniquetol(A) 所给出的结果不同。
这些可以是满足该条件的多个有效 C 输出,C 中的任意两个元素都不在彼此的容差范围内。uniquetol 函数可以返回多个有效输出,具体取决于 occurrence 的值是 "highest" 还是 "lowest" 以及是否指定 PreserveRange。