Get Started with Motion Planning Networks
Motion Planning Networks (MPNet) is a deep-learning-based approach for finding optimal paths between a start point and goal point in motion planning problems. MPNet is a deep neural network that can be trained on multiple environments to learn optimal paths between various states in the environments. The MPNet uses this prior knowledge to
Generate informed samples between two states in an unknown test environment. These samples can be used with sampling-based motion planners such as optimal rapidly-exploring random trees (RRT*) for path planning.
Compute collision-free path between two states in an unknown test environment. MPNet based path planner is more efficient than the classical path planners such as the RRT*.
Navigation Toolbox™ provides functionalities to perform MPNet based state space sampling and motion planning.
MPNet Architecture
The MPNet consists of two modules. The first module encodes the input map environments
to a compact representation by using basis point sets encoding approach [1]. The size of the
encoded environment is less than that of the actual map environment. In real time, the
map environments are large and often sparse. Encoding the map environment before using
it for training, reduces sparsity in the input training data, decreases computational
complexity and the time taken for training the network. The encoded environment must be
stored as a binaryOccupancyMap or occupancyMap object.
The second module consists of a feedforward network that comprise of a feature input layer, one or more hidden layers, and an output layer. Each hidden layer comprises a fully connected layer, a ReLU (Rectified Linear Unit) layer and a dropout layer.
ReLU layer adds non-linearity by applying the ReLU activation function. This allows the network to learn and represent non-linear relationships in the training data.
Dropout layer helps prevent overfitting by randomly setting a fraction of the input units to zero during training.
An MPNet can have a varying number of hidden layers and dropout layers depending on factors such as the size and resolution of the training data, risk of overfitting, and computational resources available. For example, the number of hidden layers should be reduced when computational resources are limited and also to mitigate the risk of overfitting. The network uses weighted mean square distance as the loss function for output layer.
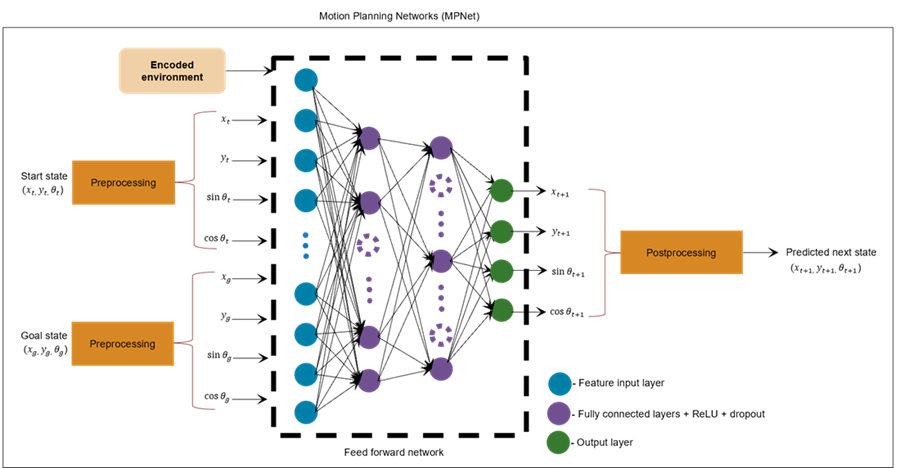
The feedforward network takes the encoded environment as an input along with a start state and goal state to predict a next state that is closer to the goal state. The feedforward network is trained through supervised learning by using optimal paths generated by classical path planners like RRT*.
The number of inputs to the feature input layer of the MPNet depends on the size of the encoded environment in addition to the number of state space variables in the start state and goal state. In an SE(2) state space, the states are specified using three state space variables x, y, and θ. The input state values must be preprocessed such that the:
State inputs to the network must be of the form [x y cosθ sinθ].
Values of the state space variables x and y must be normalized to the range [0, 1].
The number of inputs to the input layer of the MPNet is the sum of the number of state space variables representing the start state and goal state and the size of the encoded environment. For an SE(2) state space, the number of state variables given as inputs to the network is 4 for each of the start state and the goal state. If the size of the encoded environment is M-by-N then the number of inputs to the network is (M*N)+8.
Create MPNet
You can either load a preconfigured MPNet or create a custom MPNet for the purpose of state space sampling or motion planning.
The Network property of the mpnetSE2
object stores an untrained, preconfigured MPNet that you can load and train on a new
data set. The preconfigured MPNet consists of an input layer, four hidden layers, an
output layer. The number of inputs to this network is set to 108 and number of outputs
from the network is set to 4. The encoding size for the map environment is set to [10
10].
Alternatively, you can use the mpnetLayers
function to create a custom MPNet with a variable number of inputs, depending on the
encoding size of the map environment. You can also adjust the number of hidden layers
and their sizes, as well as the number of dropout layers and their dropout probabilities
within the network. You can then configure this custom network for training on an SE(2)
state space by using the mpnetSE2
object.
You can use both single map environment and multiple map environments to train and test an MPNet. When you use a single map environment, the test environment must be the same as the environment used for training the MPNet.
During training phase, the network trains the weights until the weighted mean squared loss between the predicted state and the actual state (ground truth) is minimized.
During simulation and deployment phase, the start state specified at the input is considered as the current state for the first iteration. For subsequent iterations, the predicted next state returned by the network is considered as the current state. The iterations repeat until the current state reach the desired goal state.
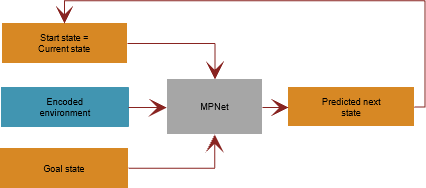
Train MPNet from Scratch
You can train an MPNet from scratch on a new data set by using the trainnet (Deep Learning Toolbox)
function. Use the trainingOptions (Deep Learning Toolbox) function to specify the
hyperparameters for training the network. You can use the mpnetPrepareData function to preprocess the training data set. The
mpnetPrepareData function uses basis point sets encoding approach to
encode the training data. The function internally calls the bpsEncoder
object and the encode object
function for encoding the data prior to training.
In the case of a single map environment, you must use a fixed map for training and testing the network. Also, use training loss to evaluate the network accuracy. For information on how to train the MPNet on a single map environment, see Train MPNet on Single Map Environment.
If you train the MPNet on a large training data set created using multiple map environments, you must compute both training loss and validation loss to fine-tune the network accuracy. For information on how to train the MPNet on multiple map environments, see Train Deep Learning-Based Sampler for Motion Planning. This example uses the trained MPNet for state space sampling. The Train MPNet on Custom Data for Motion Planning example shows how to train MPNet and perform motion planning.
After training the network, use the predict
function of the mpnetSE2 object iteratively to find the samples between
a start state and goal state in a test environment. If you have the ground truth, you
can check the network accuracy by computing the loss between the predicted state and the
ground truth state. You can use the loss
function of mpnetSE2 object to calculate the network accuracy.
Perform State Space Sampling Using MPNet
Use the stateSamplerMPNET object to create a state sampler using a pretrained
MPNet. You can then use the sample
method of the stateSamplerMPNet object to compute the learned
samples.
Classical sampling approaches, such as uniform sampling, generate more number of samples and not all the generated samples may have an impact on the final path. When you use these samples with a sampling-based planner, the planning process becomes slow and inefficient, especially for state spaces with a large number of dimensions. On the other hand, MPNet based state sampling generates learned samples that can bias the path towards the optimal solution. However, learned sampling cannot guarantee the probabilistic completeness and asymptotic optimality that uniform sampling does. To guarantee a solution, you can generate learned samples for a fixed number of iterations after which you can switch to uniform sampling. This strategy guarantees an optimal solution, if the optimal solution exists.
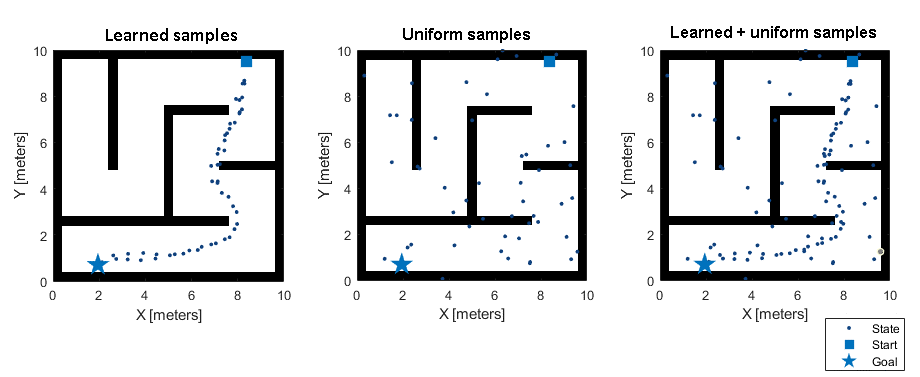
You can use the MaxLearnedSamples property of the stateSamplerMPNET object to specify the number of iterations after which
the MPNet state sampler computes samples using the uniform sampling approach.
For information about how to perform informed sampling using MPNet and understand the effect of combining learned sampling and uniform sampling approach, see Perform Informed Sampling with MPNet.
To accelerate motion planning, you can use MPNet state sampling with a path planner. This approach reduces the number of samples required to find a feasible path and speeds up motion planning. You can configure a MPNet state sampler object and specify it as an input to a path planner. The path planner will use the samples returned by the state sampler as seeds for finding the optimal path between a start and goal pose. For information about how to use the MPNet state sampler for motion planning, see Sample State Space Using Pretrained MPNet and Perform Motion Planning.
The Accelerate Motion Planning with Deep-Learning-Based Sampler example compares the performance of MPNet state sampling with uniform sampling using evaluation metrics such as execution time, path length, and smoothness.
Perform Motion Planning Using MPNet Path Planner
Use the plannerMPNET
object to create a path planner using pretrained MPNet. You can then use the plan
function of the plannerMPNET object to compute path between two
states in an known or unknown map environment.
MPNet path planner is a bidirectional planner and converges more rapidly toward the
optimal solution. The MPNet path planner uses two planning approaches for computing
collision-free paths: 1) Neural path planning, and 2) Classical path planning. It
switches from neural path planning to classical plan planning when it encounters
difficulty in compute a collision-free path between two states. For information about
how the MPNet path planner works, see the Algorithms section of plannerMPNET.
The Plan Path Between Two States Using MPNet Path Planner example shows how to perform motion planning using MPNet path planner.
Use Pretrained MPNet
Navigation Toolbox ships pretrained MPNet as .mat files that you can load
in to the MATLAB® workspace and directly use for prediction. First, you must store this
pretrained network to the Network property of the
mpnetSE2 object and then use the stateSamplerMPNET or plannerMPNET
object for state space sampling or path planning, respectively.
The file
officeMapTrainedMPNET.matcontains an MPNet that is trained on a single office map environment for a Dubins vehicle. In this case, the test environment is the same as the train environment. For information on how to use this pretrained MPNet, see Predict State Samples Using MPNet Trained on Single Environment and Plan Path in Dubins State Space Using MPNet Path Planner.The file
mazeMapTrainedMPNET.matcontains an MPNet that is trained on various, randomly generated maze maps of specific dimensions. You can use this pretrained network to predict states in both known and unknown test environments. However, the test environment must have the same data distribution as that of the environments used for training the network. For information on how to use this pretrained MPNet, see Predict State Samples Using MPNet Trained on Multiple Environments and Plan Path Between Two States Using MPNet Path Planner.
References
[1] Prokudin, Sergey, Christoph Lassner, and Javier Romero. “Efficient Learning on Point Clouds with Basis Point Sets.” In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 3072–81. Seoul, Korea (South): IEEE, 2019. https://doi.org/10.1109/ICCVW.2019.00370.
[2] Qureshi, Ahmed Hussain, Yinglong Miao, Anthony Simeonov, and Michael C. Yip. “Motion Planning Networks: Bridging the Gap Between Learning-Based and Classical Motion Planners.” IEEE Transactions on Robotics 37, no. 1 (February 2021): 48–66. https://doi.org/10.1109/TRO.2020.3006716.
[3] Qureshi, Ahmed H., and Michael C. Yip. “Deeply Informed Neural Sampling for Robot Motion Planning.” In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 6582–88. Madrid: IEEE, 2018. https://doi.org/10.1109/IROS.2018.8593772.
See Also
mpnetSE2 | stateSamplerMPNET | stateSamplerGaussian | stateSamplerUniform | plannerMPNET