Simulink 和 Stateflow 在建模中的使用
使用 Stateflow® 时,需要 Simulink® 来进行输入、输出和结构化处理。Stateflow 本身可以执行各种公式处理。使用 Simulink 时,可以通过各种方法(例如使用 Switch Case 模块)来实现复杂的状态变量。
Simulink 或 Stateflow 均可用来对控制的特定部分建模,但在开发工作流中的应用哪个产品取决于用户对底层算法的理解,并最终由组织来决定哪种工具最适合其需求。是应该使用 Simulink 还是使用 Stateflow 进行设计应由一组人根据任务来做决定。还需指定 Stateflow 中的实现是使用状态转换还是使用流程图。
在大多数情况下,Stateflow 在 RAM 方面的效率较低。因此,Simulink 在使用简单公式的计算中具有优势。此外,对于使用简单触发器和 Relay 模块来操作状态变量的情形,Simulink 更有优势。在评估是在工程中使用 Simulink 还是 Stateflow 时,应考虑以下主题:
增加 RAM:必须始终有可用的 RAM 来实现 Stateflow 输入、输出和内部变量的可视化。
方程错误处理:在内部使用通用计算公式时,用户需设计防止溢出的方法。
拆分和分离功能:在 Stateflow 之外使用 Simulink 进行计算时,可能会导致拆分,从而降低可读性。有时可读性也可能会提高。这很难判断。
在实现接近代码的最佳表达式上,个别情况下 Stateflow 的代码效率会比 Simulink 更高,但大多数情况下,会使模型难以理解。如果代码已经存在,使用 S 函数比 Stateflow 建模更有利。Stateflow 可以比 Simulink 更有效地记录指定了特定模式(或结构)的计算或使用 for 循环的计算,但近年来,使用 MATLAB® 语言进行描述也变得方便。如果需要,可以考虑使用 MATLAB 语言进行建模。
对于 Stateflow 模型,在处理如下所述的状态时,通过将其描述为状态转换可以提高可读性:
对于相同的输入,输出不同的输出值。
存在多个状态(作为指导,三个或更多)。
各个状态的名称要有意义,而不仅仅是数字。
在一个状态内部,需要初始化(第一次)并能在后续执行中进行区分(第二次之后)。
例如,在触发器电路中,输入会产生不同的输出值。状态变量限制为 0 和 1。然而,仅仅保留布尔类型的数字并不能为每个状态添加有意义的名称。状态内部也没有初始化和后续执行的区别。因此,上述四个触发器中只有一个适用,所以 Simulink 更有优势。
在 Stateflow 中,可以表示为状态的情况被实现为状态转换,而非状态的条件分支被实现为流程图。真值表被归类为条件分支实现方法。当使用 Stateflow 将状态设计为状态转换时,应选择 Classic 作为状态机类型,以便将其作为软件实现到控制系统的嵌入式微控制器中。
Stateflow 支持 HDL Coder™。使用 HDL Coder 时,必须选择 Mealy 或 Moore;当需要防止内部漏电时,Moore 模式更为合适。
注意
这些规范中没有描述 HDL Coder 用例。
Simulink 功能
本节提供有关使用 Simulink 进行建模的信息。
具有状态变量的模块
具有状态变量的模块主要分为 Simulink 类型和离散类型。
对于这些模块中的大多数,用户可以使用模块参数来设置状态属性和初始值。条件子系统可以具有状态变量,这取决于结构模式。
在此示例中,Unit Delay 模块具有状态属性。
在此示例中,Tapped Delay 模块没有状态属性。
请参阅规范:jc_0640
具有状态变量的分支语法
当使用状态变量时,Switch 模块和条件子系统的行为有所不同。
根据配置设置,当存在任何状态变量时,Switch 模块通常会在满足控制端口的条件时执行子系统 A。若条件不满足,则只执行子系统 B,而不计算子系统 A。但是,当子系统 A 包含状态变量时,即使控制端口的条件不满足,也会处理子系统 A 内的状态变量的计算。
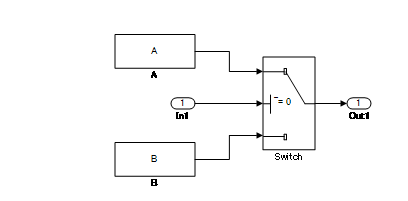
在条件子系统中,当条件满足时,计算子系统 A。当条件不满足时,则计算子系统 B 而不是子系统 A,而不管子系统 A 中是否存在任何状态变量。
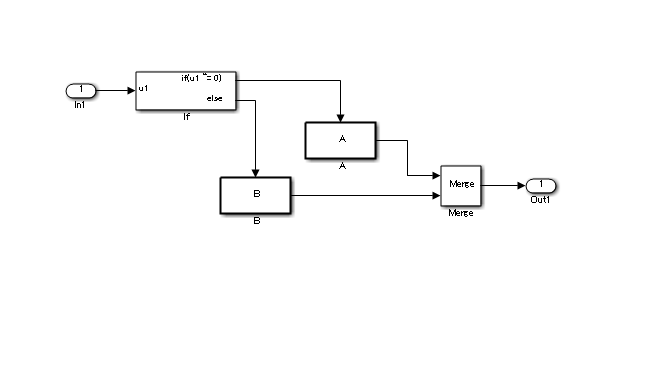
可以使用 {动作端口} 设置来指定重新计算中的重置操作。
下表列出了使用 Switch 模块和条件控制流时子系统 A 的行为。熟悉这些行为以确定哪个结构、Switch 模块或条件子系统最适合预期目的。
该表显示了子系统 A 的行为。
| 控制端口条件 | (在子系统 A 中) 状态变量 | Switch | 条件子系统 |
| 保持 | 否 | 执行 | 执行 |
| 是 | |||
| 不保持 | 否 | 不执行 | 不执行 |
| 是 | 最小处理 *执行与状态变量相关的计算 |
该表提供了子系统 A 的初始化时序。
| 动作端口 | 初始化 | |
| Switch | - | 仅第一次 |
| 条件子系统 | 保持 | 仅第一次 |
| 重置 | 按条件返回 |
请参阅规范:
子系统
子系统用于编译各种模块和子系统。
子系统还可以用于其他目的。非功能子系统的使用方法包括:
用子系统的封装显示来描述概要或显示固定格式的文件,如 "classified"
用子系统的开放函数(模块属性中的回调函数)来运行多个工具或显示与模型分开的解释性文本
具有管理权限的用户通过简单地将子系统设置为
NoReadOrWrite来将其更改为封装子系统,使其他用户无法看到子系统中的内容。
这些非典型子系统超出了规范的范围,如果被排除,则应将其列入工程内管理的例外列表中。
请参阅规范:
原子子系统和虚拟子系统. 子系统有两种类型:虚拟子系统和原子子系统。这些子系统之间的主要区别在于子系统是否被视为单个执行单元。虚拟子系统是默认的子系统模块。
在模型中,虚拟子系统的边框较细,而原子子系统的边框较粗。
虚拟子系统
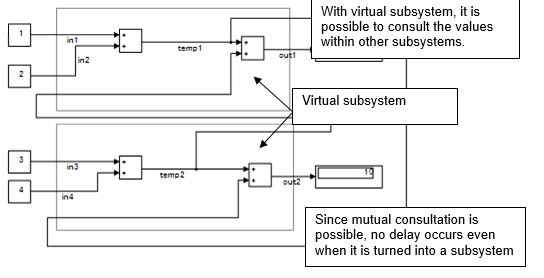
提供视觉表示的模块称为“虚拟模块”。例如,编译多条信号线的 Mux 模块,发出信号的 From 模块,以及与虚拟模块对应的 Goto 模块。由于默认设置中的子系统模块仅构成视觉上的层次结构,因此这些模块被称为虚拟模块。子系统被称为虚拟子系统。
考虑一个子系统,该子系统在子系统内查阅外部计算结果,如下例所示。这个系统是根据下面这四个方程计算出来的。
temp1= in1 + in2
temp2= in3 + in4
out1= in1 + in2 + temp2
out2= temp1 + in3 + in4
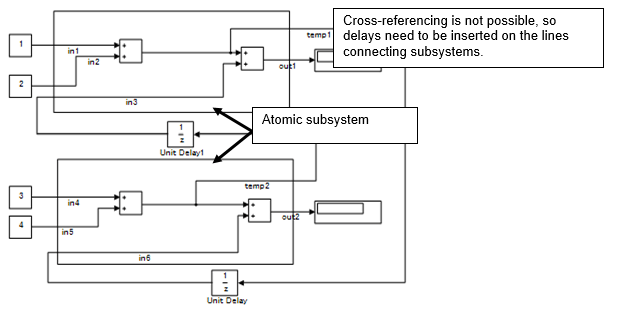
原子子系统
原子子系统与外部系统分离,不受跨边界优化的影响。原子子系统不使用每个子系统内部计算的结果。因此,中期输出值将使用延迟一个会话的计算结果。
temp1= in1 + in2
temp2= in4 + in5
out1= in1+ in2 + in3
out2= in4+ in5 + in6
in3= temp2
in6= temp1
原子子系统禁止其他子系统直接引用中间计算结果。
关于原子子系统的注释:
原子子系统可以选择 C 源函数设置。
如上所述,原子子系统的内部部分将被封装(对象化)。
根据前后关系,应在子系统内部为输出信号保留一个静态 RAM 分区。
应谨慎使用原子子系统(包括添加功能设置)。因子设置不会简单地在 C 代码中插入一个因子名称。应当了解子系统被描述为在数学上独立的系统,应仔细审查原子子系统的使用条件。
包括与结构层的关系;需要确定每个工程的运算规则,并确定其与规范规则的关系。
信号名称
信号可以被命名,并称为信号名称。当一个信号被命名时,其信号名称将显示为标签。标签的更新反映在信号名称中并显示出来。
信号名称可以通过分支信号线或端口模块传播到信号线并显示为信号名称。
请参阅规范:
可以通过将信号名称与信号对象(Simulink 对象或 mpt 对象)关联来生成代码。类型设置通过数据字典配置,存储类别的设置是可选的。这些模块的推荐数据类型设置包括:
请参阅规范 jc_0644:类型设置。
向量信号/路径信号
组成向量的各个标量信号应具有共同的功能、数据类型和单位。
不满足向量条件的信号只能分组为总线信号。Bus Selector 模块仅应用于总线信号输入。它不能用于从向量信号中提取标量信号。
下表是向量信号的示例。
| 向量类型 | 大小 |
|---|---|
| 行向量 | [1 n] |
| 列向量 | [n 1] |
| 车轮转速子系统 | [1 车轮数量] |
| 气缸向量 | [1 气缸数量] |
| 基于二维坐标点的位置向量 | [1 2] |
| 基于三维坐标点的位置向量 | [1 3] |
下表是总线信号的示例。
| 总线类型 | 元素 |
|---|---|
| 传感器总线 | 力向量 |
| 位置 | |
| 车轮速度向量 [Θlf, Θrf, Θlr, Θrr] | |
| 加速度 | |
| 压力 | |
| 控制器总线 | 传感器总线 |
| 作动器总线 | |
| 串行数据总线 | 循环水温 |
| 发动机速度、前排乘客座椅门打开 |
请参阅规范:
枚举类型
枚举型数据是指被限制为确定数值的数据。
Simulink 中的枚举类型中可使用的模块类型是有限的。
要使用枚举类型,必须使用 MATLAB 上的 .m 文件定义枚举类型。有关定义枚举数据类型的更多信息,请参阅在 Simulink 模型中使用枚举数据。
Stateflow 功能
本节提供有关使用 Stateflow 进行建模的信息。
Stateflow 的可用操作
有关 Stateflow 操作的更多信息,请参阅 对 Stateflow 数据的运算 (Stateflow)。
请参阅规范:
状态转移和流程图之间的差异
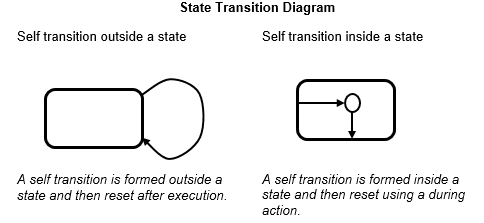
Stateflow 既可以表示状态转移,也可以表示流程图。
Stateflow 允许在状态转移图中设计流程图。
entry 动作在状态中表示为一个流程图,从默认转移开始,通过转移线移动到结点,如下图所示。从内部转移线开始允许在流程图中表示 during 动作。
流程图无法在更新之间保持其激活状态。因此,流程图总是在终止结点(没有有效出向转移的连接结点)结束。
相比之下,状态转移图会在内存中存储其当前状态,以在更新之间保留本地数据和激活状态。因此,状态转移图可以从上一个时间步骤中断的地方开始执行。这意味着状态转移适合依赖于历史的反应式或监督系统建模。
该表定义了流程图和状态转移图的起点和终点。
| 起点 | 终点 | |
| 流程图 | 默认转移 | 所有源自状态的终止点都连接到连接结点。 |
| 状态转移图 | 默认转移 | 所有终止点都应连接到状态 |
此图显示了一般流程图和状态转移图之间的区别
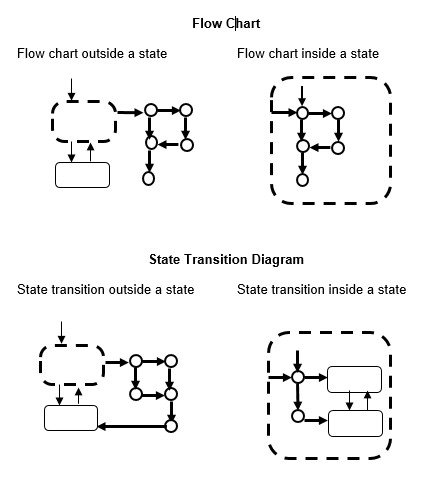
流程图和具有自转移的状态转移图的混合具有更严格的约束。
请参阅规范:
回溯
此示例显示了具有结点的转移的行为,这些结点强制在流程图中执行回溯行为。该图使用出向转移的隐式排序。
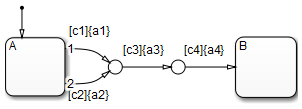
最初,状态 A 处于激活状态,并且转移条件 c1、c2 和 c3 为 true。转移条件 c4 为 false。
图的根节点检查是否存在源自状态 A 的有效转移。
从状态 A 到连接结点之间存在一条有效转移段,其转移条件为 c1,因此:
转移条件 c1 为 true,因此执行动作 a1。
转移条件 c3 为 true,因此执行动作 a3。
转移条件 c4 不为 true,因此控制流回溯到状态 A。
图的根节点检查是否存在源自状态 A 的另一个有效转移。
从状态 A 到连接结点之间存在一条有效转移段,其转移条件为 c2,因此:
转移条件 c2 为 true,因此执行动作 a2。
转移条件 c3 为 true,因此执行动作 a3。
转移条件 c4 不为 true,因此控制流回溯到状态 A。
图进入休眠状态。
为了解决这个问题,请考虑在终止结点处添加无条件转移线。当 c3 或 c4 不成立时,终止结点允许流程结束。这种设计使状态 A 保持激活状态,而无需执行不必要的操作。

请参阅规范:
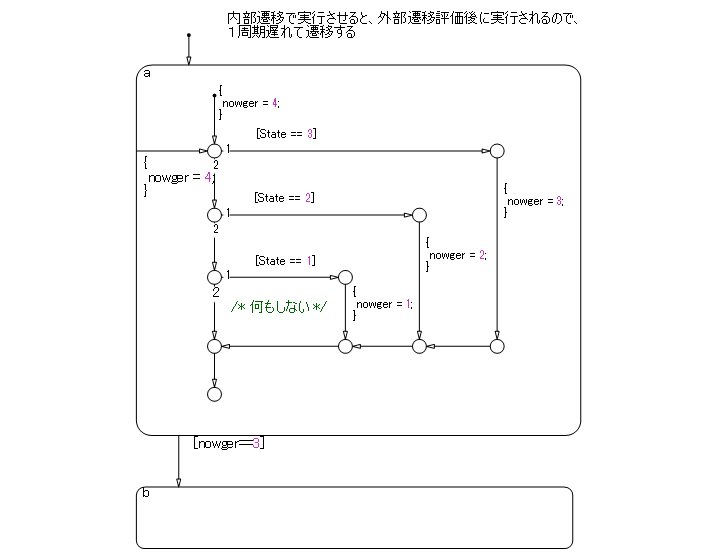
状态外流程图
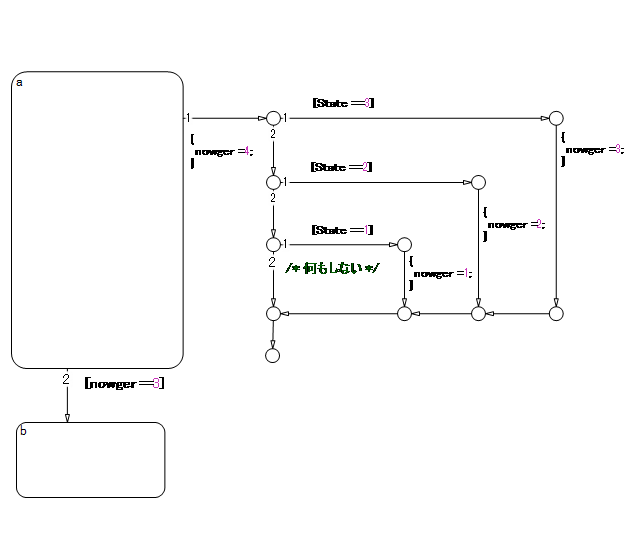
与状态相关的流程图可以在状态内部或外部编写;但是,要注意执行顺序和回溯。
以下流程图在执行状态外的流程图后评估从 a 到 b 的转移,看起来这个转移是在与新一轮计算相同的周期内执行的。但是,如果通过计算状态外的转移到达终止点,则不会评估到 b 的转移线。这是一个始终停留在 a 的状态转移图。
正确的做法如下所示,转移条件不在外部流程图的终止处,允许在执行流程图后评估从 a 到 b 的转移线。这使得外部流程图能够在转移之前执行,并在转移瞬间使用最新值进行评估。请注意,该图包含一个死路径,其中的转移条件永远不会成立,这可能会在将来变更规范时导致错误。请慎用这种图结构。
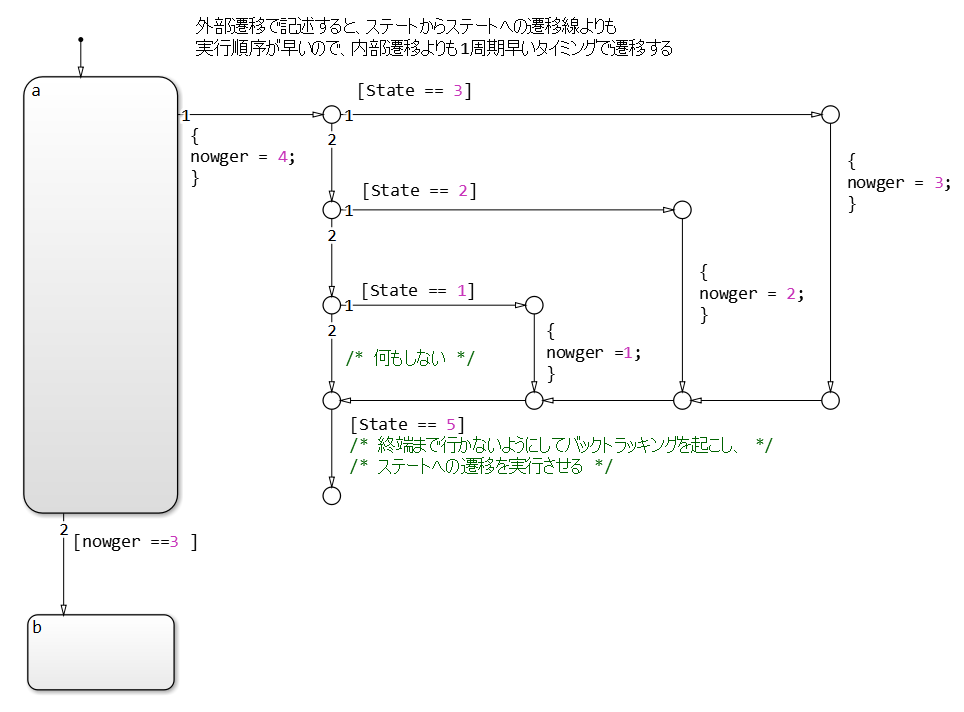
相比之下,下面的流程图是在状态内部,这意味着在执行状态 a 时总是会计算内部流程图,且该流程图可以描述为一种易于理解的结构,没有死路径。然而,需要注意的是,作为性能特征,当执行状态 a 时,从 a 到 b 的转移会在内部流程图计算之后的循环中进行评估。由于此特性,外部流程图的计算和转移的执行时间可能会存在偏差。请慎用。
请参阅规范:
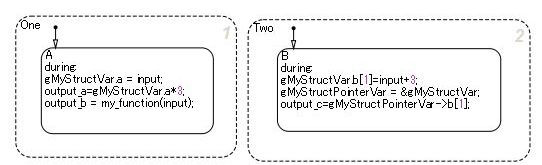
指针变量
此代码示例来自模型 sf_custom。要打开模型,请在 MATLAB 命令行中输入以下内容:
openExample('sf_custom')sf_custom 中,点击打开 my_header.。 #include "tmwtypes.h"
extern real_T my_function(real_T x);
/* Definition of custom type */
typedef struct {
real_T a;
int8_T b[10];
}MyStruct;
/* External declaration of a global struct variable */
extern MyStruct gMyStructVar;
extern MyStruct *gMyStructPointerVar;
sf_custom 中,点击Open my_function.c。#include "my_header.h"
#include <stdio.h>
/* Definition of global struct var */
MyStruct gMyStructVar;
MyStruct *gMyStructPointerVar=NULL;
real_T my_function(real_T x)
{
real_T y;
y=2*x;
return(y);
}
gMyStructVar 未在 Stateflow 中定义。通常,my_function 的函数从 C 源文件调用以供 Stateflow 使用。但是,也可以从 Stateflow 中直接引用 C 源文件公开的全局变量。
初始化
本节提供有关如何初始化值的信息。
初始化中的初始值设置
当信号需要初始化时,需要正确设置初始值。
在模块内部设置初始值时,请使用包含注解的初始值列表,以便直观地确认输入的初始值。
需要初始值的情况包括:
当定义了状态变量且使用了具有状态变量的 AND 模块时。
使用内部模块设置。
使用外部输入值。
当定义了状态变量并且执行特定配置时为模块启用了初始值时。
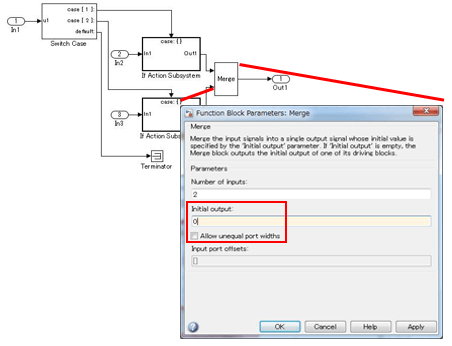
在 Merge 模块中设置初始值。
使用在数据字典中注册的信号。
当定义了可以从外部引用的信号设置(使用 RAM)时。
使用在数据字典中注册的信号。
数据字典中注册信号的初始值
为数据字典中注册的信号设置初始值。
离散模块组,例如 Unit Delay 和 Data Store Memory,具有状态变量。
在自动代码生成的情况下,可以通过将状态变量与数据字典中的信号(与 Simulink 信号对象关联)进行匹配来设置信号名称、类型和初始值。当使用数据字典中定义的信号作为状态变量时,各状态变量的初始值应与定义的值一致。
当使用数据字典中定义的信号作为状态变量时
对于离散模块,例如 Unit Delay 和 Data Store Memory,设置不是在使用数据字典中为模块输出线定义的信号时执行的,而是为模块内部的状态变量执行的。即使将数据字典的信号名分配给信号线,也会重复保留 RAM,这会浪费 RAM。
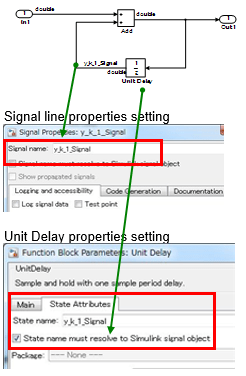
示例 - 正确
信号是为模块内的状态变量定义的。定义了信号名称并选择了模块参数状态名称必须解析为 Simulink 信号对象。
示例 - 不正确
信号被定义为具有状态变量的模块的输出信号。信号名称已定义,但未选择模块参数状态名称必须解析为 Simulink 信号对象。

在工作区中定义的信号对象可以通过 disableimplicitsignalresolution(modelname) 自动与同名的信号对象和信号名称相关联。但是对于模块内部的状态变量来说,它们是与模块内部的状态变量以及同名的信号名称相关联的。如果一个全局设置的信号同时与两个变量关联,最好将模块内部的状态变量和信号线上的信号标签设置为不同的名称,否则模型将无法仿真。
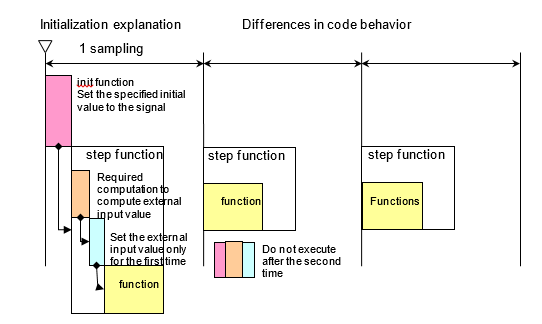
以外部输入值为初始值的模块
在初始化期间设置初始值时,会调用 init 函数将信号设置为模块内的值或数据字典中定义的初始值。接下来,执行单步函数(数据流执行函数)。这里,外部输入值被设置为初始值。建模时,要注意初始化的执行函数和执行时间。下图说明了这一点。

系统配置中启用初始化参数的初始值设置
在某些系统配置中,根据其设置,可以为条件子系统和 Merge 模块的组合启用初始化参数。当这些组合中需要初始值时,将执行以下任一建模方法:
例外情况是,当有连续模块具有初始值,并且不需要为每个模块的设置明确显示信号的初始值时。
示例 - 正确
在 Merge 模块中设置的初始值。
示例 - 正确
在 mpt 对象中设置的初始值。
示例 - 不正确
尽管需要设置初始值,但它却未在任何地方显示出来。
