nlmefitsa
Fit nonlinear mixed-effects model with stochastic EM algorithm
Syntax
Description
beta = nlmefitsa(X,y,group,V,modelfun,beta0)modelfun to the data in
X, y, group, and
V and returns the fixed-effects estimates in
beta. nlmefitsa uses the initial fixed-effects
values in beta0 to fit the model.
For more information about the SAEM algorithm, see Algorithms.
Examples
Load nonlinear sample data and display the predictor, response, and grouping variables.
load nonlineardata.mat
[X,y,group]ans = 30×5
8.1472 0.7060 75.1267 573.4851 1.0000
9.0579 0.0318 25.5095 188.3748 1.0000
1.2699 0.2769 50.5957 356.7075 1.0000
9.1338 0.0462 69.9077 499.6050 1.0000
6.3236 0.0971 89.0903 631.6939 1.0000
0.9754 0.8235 95.9291 679.1466 1.0000
2.7850 0.6948 54.7216 398.8715 1.0000
5.4688 0.3171 13.8624 109.1202 1.0000
9.5751 0.9502 14.9294 207.5047 1.0000
9.6489 0.0344 25.7508 190.7724 1.0000
1.5761 0.4387 84.0717 593.2222 1.0000
9.7059 0.3816 25.4282 203.1922 1.0000
9.5717 0.7655 81.4285 634.8833 1.0000
4.8538 0.7952 24.3525 205.9043 1.0000
8.0028 0.1869 92.9264 663.2529 1.0000
⋮
Display the group predictor variables.
V
V = 2×1
2
3
X is a matrix of predictor data, and y is a vector containing the response variable. group contains data for the grouping variable, and v contains the group predictor variables.
Create an anonymous nonlinear function that accepts a vector of coefficients, a matrix of predictor data, and a vector of group predictor variables.
model = @(phi,xfun,vfun)(phi(1).*xfun(:,1).*exp(phi(2).*xfun(:,2)./vfun)+phi(3).*xfun(:,3))
model = function_handle with value:
@(phi,xfun,vfun)(phi(1).*xfun(:,1).*exp(phi(2).*xfun(:,2)./vfun)+phi(3).*xfun(:,3))
model is a handle for a function given by the formula
.
Fit model to the data in X, y, group, and v using the nlmefitsa function. Specify a vector of ones as the initial estimate for the fixed-effects coefficients.
beta = nlmefitsa(X,y,group,V,model,[1 1 1])

beta = 3×1
1.0008
4.9980
6.9999
The output shows the progress of estimating the fixed effects and the elements of the random-effects covariance matrix, as well as the final fixed-effects estimates beta. In each plot, the horizontal axis shows the iteration step, and the vertical axis shows the value of the estimation.
Load nonlinear sample data.
load nonlineardata.mat;X is a matrix of predictor data, and y is a vector containing the response variable. group contains the data for the grouping variable, and V contains the data for the group predictor.
Create an anonymous nonlinear function that accepts a vector of coefficients, a matrix of predictor data, and a vector of group predictor variables.
model = @(phi,xfun,vfun)(phi(1).*xfun(:,1).*exp(phi(2).*xfun(:,2)./vfun)+phi(3).*xfun(:,3));
model is a handle for a function given by the formula .
Define an output function for nlmefitsa. For more information about the form of the output function, see the OutputFcn field description for the Options name-value argument.
function stop = outputFunction(beta,status,state) stop = 0; hold on plot3(status.iteration,beta(2),beta(1),"mo") state = string(state); if state=="done" stop=1; end end
outputFunction plots the iteration number for the fitting algorithm together with the first and second fixed effects. outputFunction returns 1 when the fitting algorithm completes its final iteration.
Use the statset function to create an options structure for nlmefitsa that uses outputFunction as its output function.
default_opts=statset("nlmefitsa");
opts = statset(default_opts,OutputFcn=@outputFunction);opts is a statistics options structure that contains options for the stochastic expectation maximization fitting algorithm.
Create a figure and define axes in which to plot outputFunction. Fit model to the predictor data in X and the response data in y using the options in opts.
figure ax = axes(view=[12,10]); xlabel("Iteration") ylabel("beta(2)") zlabel("beta(1)") box on [beta,psi,stats] = nlmefitsa(X,y,group,V,model,[1 1 1],Options=opts)

beta = 3×1
1.0008
4.9980
6.9999
psi = 3×3
10-4 ×
0.0415 0 0
0 0.2912 0
0 0 0.0004
stats = struct with fields:
logl: []
aic: []
bic: []
sebeta: []
dfe: 23
covb: []
errorparam: 0.0139
rmse: 0.0012
ires: [30×1 double]
pres: [30×1 double]
iwres: [30×1 double]
pwres: [30×1 double]
cwres: [30×1 double]
nlmefitsa calls outputFunction after every iteration of the fitting algorithm. The figure shows that the beta(1) and beta(2) fixed effects are near 1 when the iteration number is near 0. This result is consistent with the initial values for beta. As the iteration number increases, beta(1) jumps significantly up to around 3.3 before converging to 1. As beta(1) converges to 1, beta(2) converges to 5. The output argument beta contains the final values for the fixed effects. psi contains the covariance matrix for the random effects, and stats contains additional statistics about the fit.
Load the indomethacin data set.
load indomethacinThe variables time, concentration, and subject contain time series data for the blood concentration of the drug indomethacin in six patients.
Create an anonymous nonlinear function that accepts a vector of coefficients and a vector of predictor variables.
model = @(phi,t)(phi(1).*exp(-phi(2).*t)+phi(3).*exp(-phi(4).*t));
model is a handle for a function given by the formula
,
where is the concentration of indomethacin, for are coefficients, and is time. The function does not contain group-specific predictor variables because the formula does not include them.
Fit the model to the data using time as the predictor variable, subject as the grouping variable, and concentration as the response. Specify a log transformation function for the second and fourth coefficients.
phi0 = [1 1 1 1];
xform = [0 1 0 1];
[beta,psi,stats,b] = nlmefitsa(time,concentration, ...
subject,[],model,phi0,ParamTransform=xform)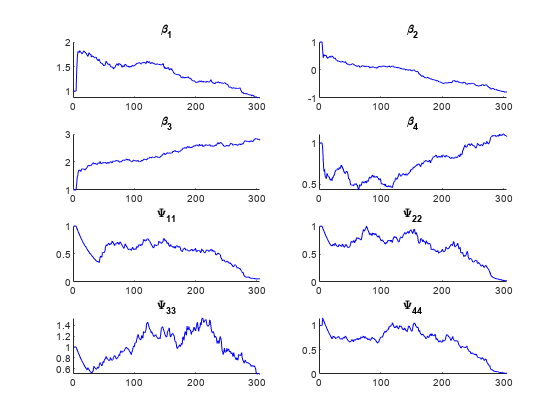
beta = 4×1
0.8630
-0.7897
2.7762
1.0785
psi = 4×4
0.0585 0 0 0
0 0.0248 0 0
0 0 0.5068 0
0 0 0 0.0139
stats = struct with fields:
logl: []
aic: []
bic: []
sebeta: []
dfe: 57
covb: []
errorparam: 0.0811
rmse: 0.0772
ires: [66×1 double]
pres: [66×1 double]
iwres: [66×1 double]
pwres: [66×1 double]
cwres: [66×1 double]
b = 4×6
-0.2302 -0.0033 0.1625 0.1774 -0.3334 0.1129
0.0363 -0.1502 0.0071 0.0471 0.0068 -0.0481
-0.7631 -0.0553 0.8780 -0.8120 0.5429 0.1695
-0.0030 -0.0223 0.0192 -0.0830 0.0505 -0.0066
The output argument beta contains the fixed effects for the model, and b contains the random effects. The plots show the progress of the Monte Carlo simulation used to fit the coefficients. The maximum likelihood estimates for beta and the random-effects covariance matrix psi converge after about 300 iterations.
Plot the sample data together with the model, using only the fixed effects in beta for the model coefficients. Use the gscatter function to color code the data according to the subject. To reverse the log transformation on the second and fourth coefficients, take their exponentials using the exp function.
figure hold on gscatter(time,concentration,subject); phi = [beta(1),exp(beta(2)),beta(3),exp(beta(4))]; tt = linspace(0,8); cc = model(phi,tt); plot(tt,cc,LineWidth=2,Color="k") legend("Subject 1","Subject 2","Subject 3",... "Subject 4","Subject 5","Subject 6","Fitted curve") xlabel("Time (hours)") ylabel("Concentration (mcg/ml)") title("Indomethacin Elimination") hold off
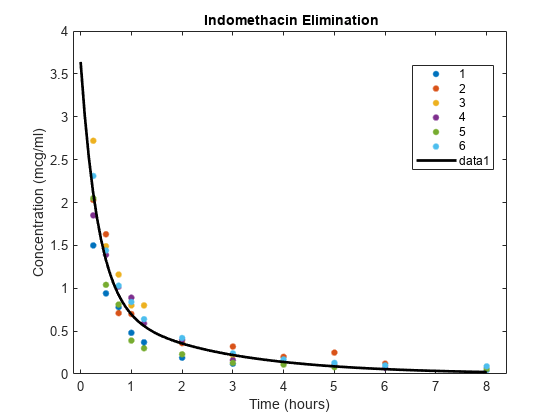
The plot shows that the blood concentration of indomethacin decreases over eight hours, and the fitted model passes through the bulk of the data.
Plot the data together with the model again, using both the fixed effects and the random effects in b for the model coefficients. For each subject, plot the data and the fitted curve in the same color.
figure hold on h = gscatter(time,concentration,subject); for j=1:6 phir = [beta(1)+b(1,j),exp(beta(2)+b(2,j)), ... beta(3)+b(3,j),exp(beta(4)+b(4,j))]; ccr = model(phir,tt); col = h(j).Color; plot(tt,ccr,Color=col) end legend("Subject 1","Subject 2","Subject 3",... "Subject 4","Subject 5","Subject 6",... "Fitted curve 1","Fitted curve 2","Fitted curve 3",... "Fitted curve 4","Fitted curve 5","Fitted curve 6") xlabel("Time (hours)") ylabel("Concentration (mcg/ml)") title("Indomethacin Elimination") hold off
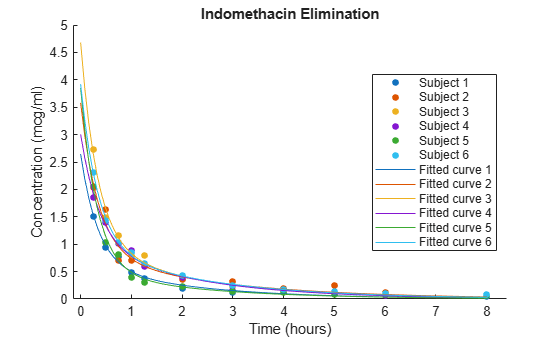
The plot shows that, for each subject, the fitted curve follows the bulk of the data more closely than the curve for the fixed-effects model in the previous figure. This result suggests that the random effects improve the fit of the model.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
By default, nlmefitsa fits a model where each model coefficient is
the sum of a fixed effect and a random effect. To fit a model with a different number of fixed
and random effects, use the name-value arguments in the Fixed and Random Effects section.
To estimate the parameters of a nonlinear mixed-effects model,
nlmefitsa uses an iterative algorithm that includes a random Monte
Carlo simulation. To specify parameters for the iterative algorithm, use the name-value
arguments in the Iterative Algorithm section. Examine the plot of
simulation results to ensure that the simulation has converged. You can also compare the
results of calling nlmefitsa multiple times with different starting
values, or use the Replicates name-value argument to perform multiple
simulations.
During fitting, nlmefitsa calculates maximum likelihood
estimates, which are parameter values that maximize a likelihood function.
nlmefitsa uses the following likelihood function:
where
is the response data.
is the vector of population coefficients.
is the residual variance.
is the covariance matrix for the random effects.
is the set of unobserved random effects.
Each pdf on the right side of the formula is a normal (Gaussian) likelihood function that might depend on covariates.
nlmefitsa uses the stochastic approximation
expectation-maximization (SAEM) algorithm to calculate the maximum likelihood estimates [1]. The SAEM algorithm takes
these steps:
Simulation — Use a Markov chain Monte Carlo algorithm together with the posterior density function and the current parameter estimates to simulate values for . Calculate the loglikelihood for each simulated , and then take the average of the loglikelihoods.
Stochastic approximation — Update the expected value of the loglikelihood function by moving its current value toward the average calculated in the previous step.
Maximization — Choose new estimates for , , and that maximize the loglikelihood function given the simulated values of the random effects.
References
[1] Delyon, B., M. Lavielle, and E. Moulines. "Convergence of a Stochastic Approximation Version of the EM Algorithm." Annals of Statistics, 27, 94–128, 1999.
[2] Mentré, F., and M. Lavielle. "Stochastic EM Algorithms in Population PKPD Analyses." American Conference on Pharmacometrics, 2008.
Version History
Introduced in R2010a